 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSMOS: Multi-organ segmentation facilitated by medical report supervision
Sep 04, 2024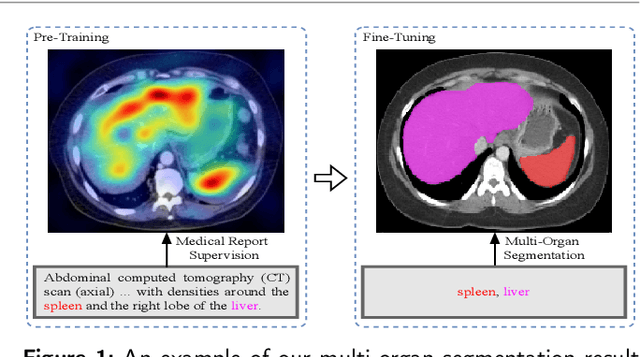
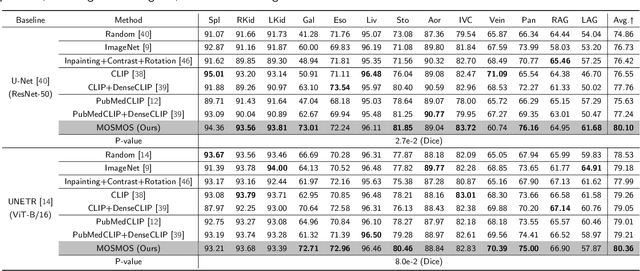
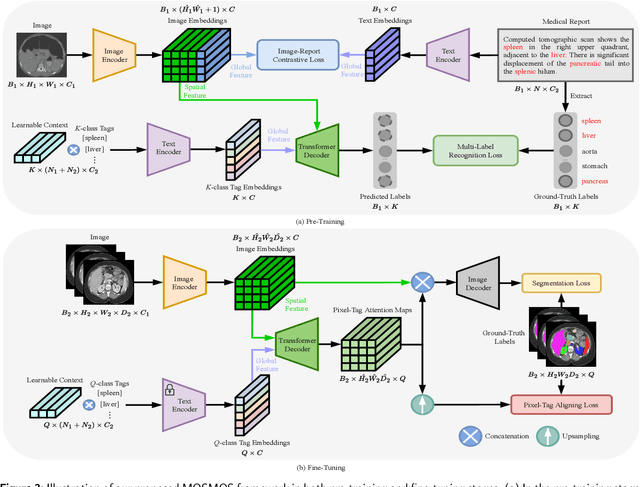
Owing to a large amount of multi-modal data in modern medical systems, such as medical images and reports, Medical Vision-Language Pre-training (Med-VLP) has demonstrated incredible achievements in coarse-grained downstream tasks (i.e., medical classification, retrieval, and visual question answering). However, the problem of transferring knowledge learned from Med-VLP to fine-grained multi-organ segmentation tasks has barely been investigated. Multi-organ segmentation is challenging mainly due to the lack of large-scale fully annotated datasets and the wide variation in the shape and size of the same organ between individuals with different diseases. In this paper, we propose a novel pre-training & fine-tuning framework for Multi-Organ Segmentation by harnessing Medical repOrt Supervision (MOSMOS). Specifically, we first introduce global contrastive learning to maximally align the medical image-report pairs in the pre-training stage. To remedy the granularity discrepancy, we further leverage multi-label recognition to implicitly learn the semantic correspondence between image pixels and organ tags. More importantly, our pre-trained models can be transferred to any segmentation model by introducing the pixel-tag attention maps. Different network settings, i.e., 2D U-Net and 3D UNETR, are utilized to validate the generalization. We have extensively evaluated our approach using different diseases and modalities on BTCV, AMOS, MMWHS, and BRATS datasets. Experimental results in various settings demonstrate the effectiveness of our framework. This framework can serve as the foundation to facilitate future research on automatic annotation tasks under the supervision of medical reports.
A Medical Multimodal Large Language Model for Pediatric Pneumonia
Sep 04, 2024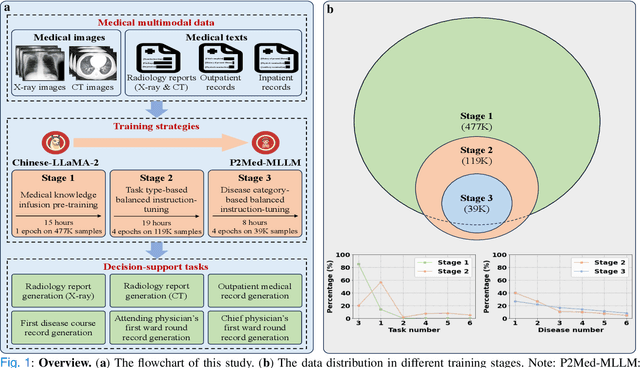

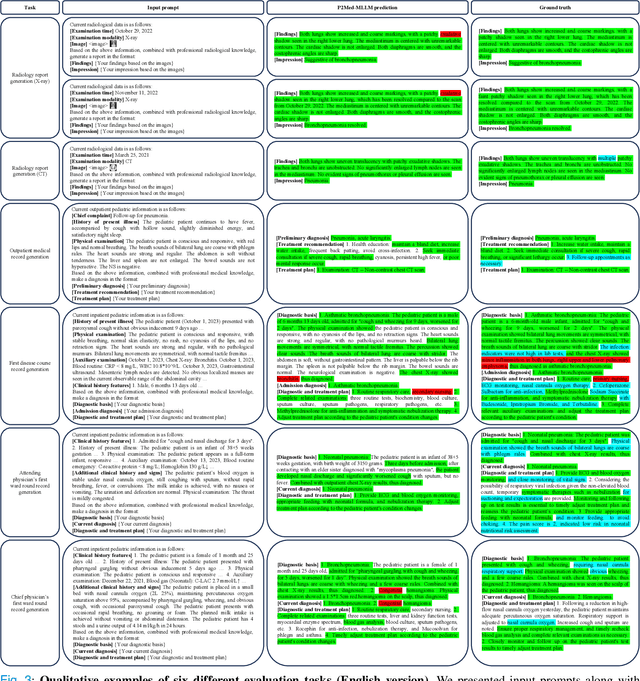
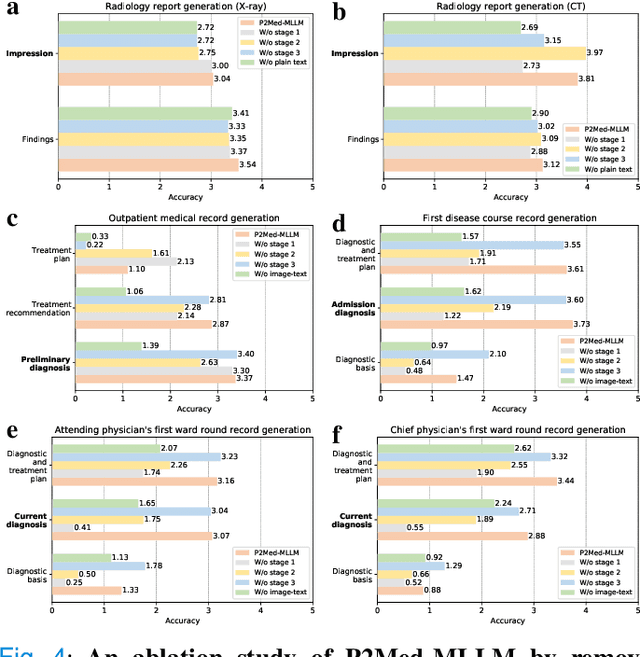
Pediatric pneumonia is the leading cause of death among children under five years worldwide, imposing a substantial burden on affected families. Currently, there are three significant hurdles in diagnosing and treating pediatric pneumonia. Firstly, pediatric pneumonia shares similar symptoms with other respiratory diseases, making rapid and accurate differential diagnosis challenging. Secondly, primary hospitals often lack sufficient medical resources and experienced doctors. Lastly, providing personalized diagnostic reports and treatment recommendations is labor-intensive and time-consuming. To tackle these challenges, we proposed a Medical Multimodal Large Language Model for Pediatric Pneumonia (P2Med-MLLM). It was capable of handling diverse clinical tasks, such as generating free-text radiology reports and medical records within a unified framework. Specifically, P2Med-MLLM can process both pure text and image-text data, trained on an extensive and large-scale dataset (P2Med-MD), including real clinical information from 163,999 outpatient and 8,684 inpatient cases. This dataset comprised 2D chest X-ray images, 3D chest CT images, corresponding radiology reports, and outpatient and inpatient records. We designed a three-stage training strategy to enable P2Med-MLLM to comprehend medical knowledge and follow instructions for various clinical tasks. To rigorously evaluate P2Med-MLLM's performance, we developed P2Med-MBench, a benchmark consisting of 642 meticulously verified samples by pediatric pulmonology specialists, covering six clinical decision-support tasks and a balanced variety of diseases. The automated scoring results demonstrated the superiority of P2Med-MLLM. This work plays a crucial role in assisting primary care doctors with prompt disease diagnosis and treatment planning, reducing severe symptom mortality rates, and optimizing the allocation of medical resources.
Inject Semantic Concepts into Image Tagging for Open-Set Recognition
Oct 23, 2023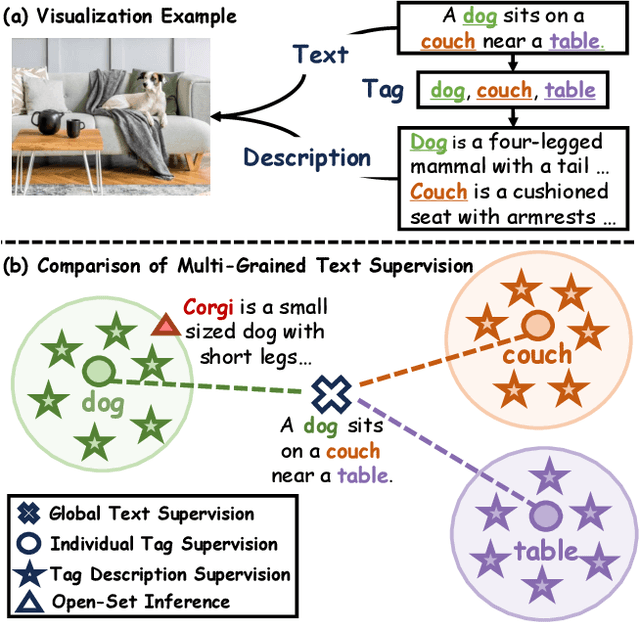
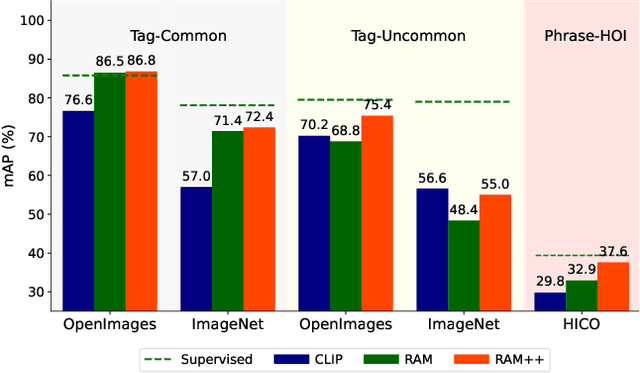
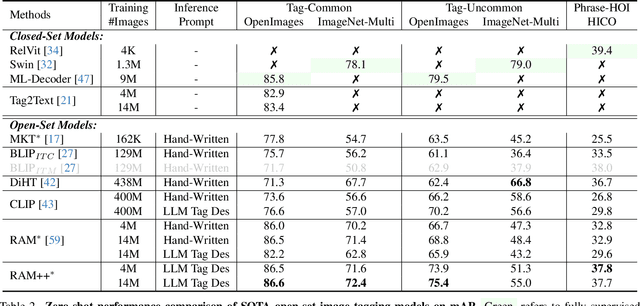
In this paper, we introduce the Recognize Anything Plus Model~(RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition. In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM++ not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories. Moreover, RAM++ employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM's knowledge into image tagging training. This approach empowers RAM++ to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate RAM++ exceeds existing state-of-the-art (SOTA) fundamental image recognition models on most aspects. Specifically, for predefined common-used tag categories, RAM++ showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet. For open-set categories beyond predefined, RAM++ records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM++ achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark. Code, datasets and pre-trained models are available at \url{https://github.com/xinyu1205/recognize-anything}.
Tag2Text: Guiding Vision-Language Model via Image Tagging
Mar 10, 2023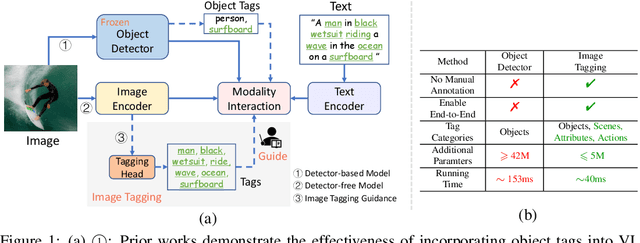
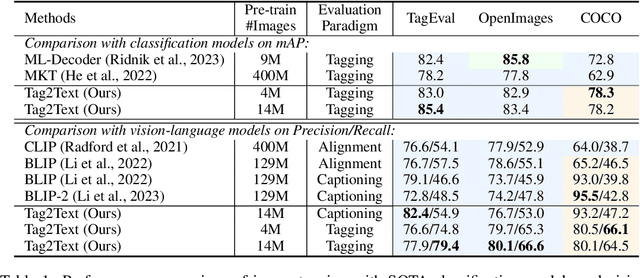

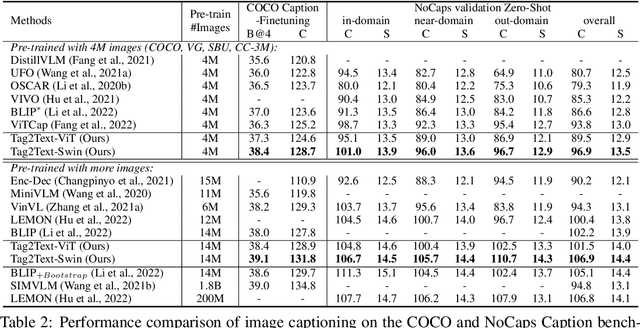
This paper presents Tag2Text, a vision language pre-training (VLP) framework, which introduces image tagging into vision-language models to guide the learning of visual-linguistic features. In contrast to prior works which utilize object tags either manually labeled or automatically detected with a limited detector, our approach utilizes tags parsed from its paired text to learn an image tagger and meanwhile provides guidance to vision-language models. Given that, Tag2Text can utilize large-scale annotation-free image tags in accordance with image-text pairs, and provides more diverse tag categories beyond objects. As a result, Tag2Text achieves a superior image tag recognition ability by exploiting fine-grained text information. Moreover, by leveraging tagging guidance, Tag2Text effectively enhances the performance of vision-language models on both generation-based and alignment-based tasks. Across a wide range of downstream benchmarks, Tag2Text achieves state-of-the-art or competitive results with similar model sizes and data scales, demonstrating the efficacy of the proposed tagging guidance.
IDEA: Increasing Text Diversity via Online Multi-Label Recognition for Vision-Language Pre-training
Jul 12, 2022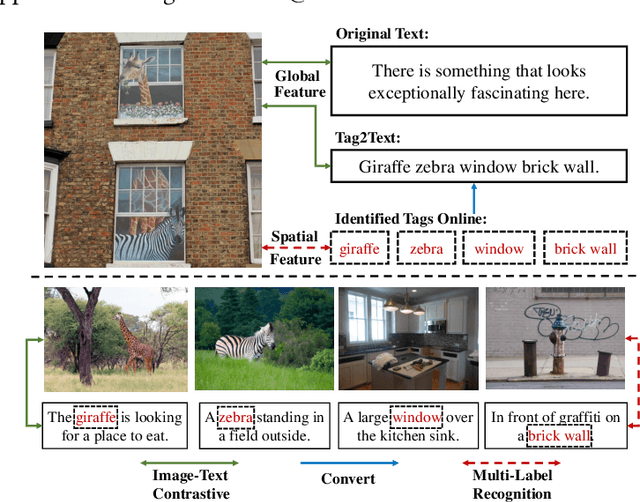


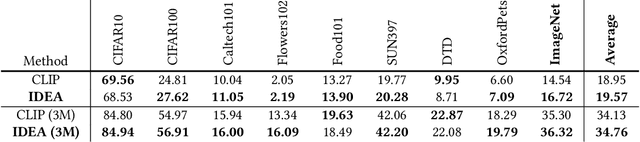
Vision-Language Pre-training (VLP) with large-scale image-text pairs has demonstrated superior performance in various fields. However, the image-text pairs co-occurrent on the Internet typically lack explicit alignment information, which is suboptimal for VLP. Existing methods proposed to adopt an off-the-shelf object detector to utilize additional image tag information. However, the object detector is time-consuming and can only identify the pre-defined object categories, limiting the model capacity. Inspired by the observation that the texts incorporate incomplete fine-grained image information, we introduce IDEA, which stands for increasing text diversity via online multi-label recognition for VLP. IDEA shows that multi-label learning with image tags extracted from the texts can be jointly optimized during VLP. Moreover, IDEA can identify valuable image tags online to provide more explicit textual supervision. Comprehensive experiments demonstrate that IDEA can significantly boost the performance on multiple downstream datasets with a small extra computational cost.