 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Medical Multimodal Large Language Model for Pediatric Pneumonia
Paper and Code
Sep 04, 2024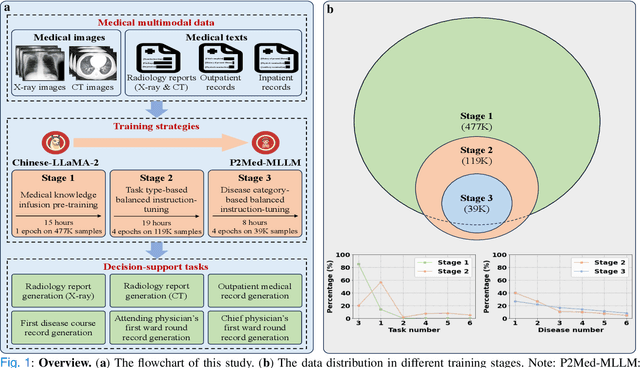

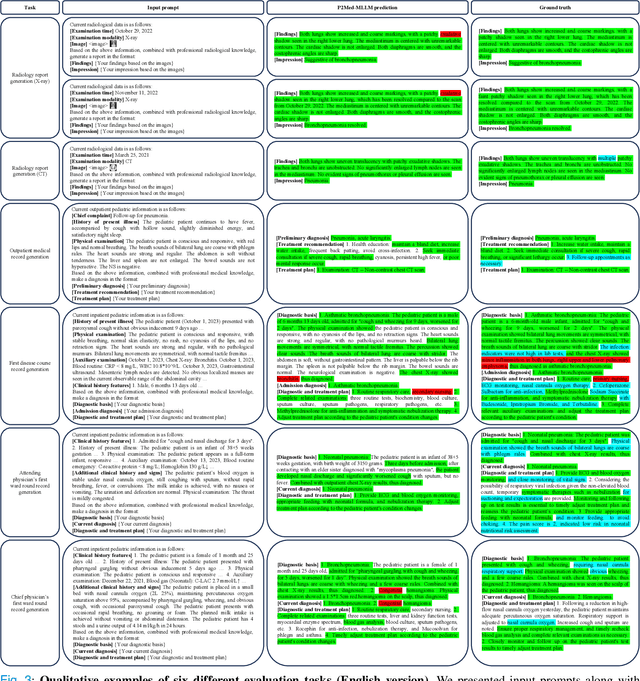
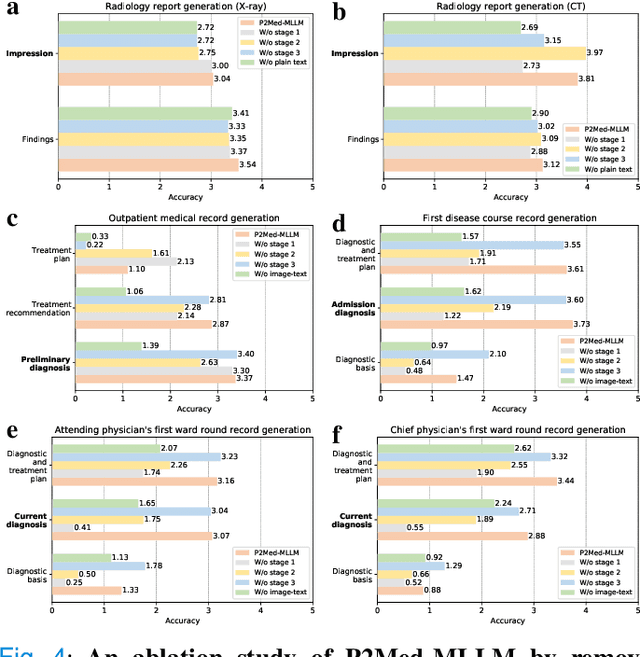
Pediatric pneumonia is the leading cause of death among children under five years worldwide, imposing a substantial burden on affected families. Currently, there are three significant hurdles in diagnosing and treating pediatric pneumonia. Firstly, pediatric pneumonia shares similar symptoms with other respiratory diseases, making rapid and accurate differential diagnosis challenging. Secondly, primary hospitals often lack sufficient medical resources and experienced doctors. Lastly, providing personalized diagnostic reports and treatment recommendations is labor-intensive and time-consuming. To tackle these challenges, we proposed a Medical Multimodal Large Language Model for Pediatric Pneumonia (P2Med-MLLM). It was capable of handling diverse clinical tasks, such as generating free-text radiology reports and medical records within a unified framework. Specifically, P2Med-MLLM can process both pure text and image-text data, trained on an extensive and large-scale dataset (P2Med-MD), including real clinical information from 163,999 outpatient and 8,684 inpatient cases. This dataset comprised 2D chest X-ray images, 3D chest CT images, corresponding radiology reports, and outpatient and inpatient records. We designed a three-stage training strategy to enable P2Med-MLLM to comprehend medical knowledge and follow instructions for various clinical tasks. To rigorously evaluate P2Med-MLLM's performance, we developed P2Med-MBench, a benchmark consisting of 642 meticulously verified samples by pediatric pulmonology specialists, covering six clinical decision-support tasks and a balanced variety of diseases. The automated scoring results demonstrated the superiority of P2Med-MLLM. This work plays a crucial role in assisting primary care doctors with prompt disease diagnosis and treatment planning, reducing severe symptom mortality rates, and optimizing the allocation of medical resources.