 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeu-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
Nov 09, 2023
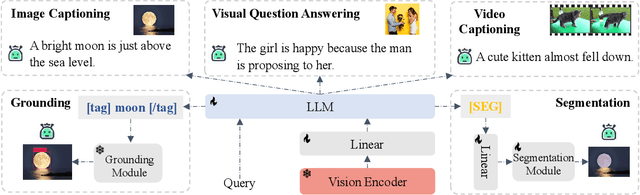
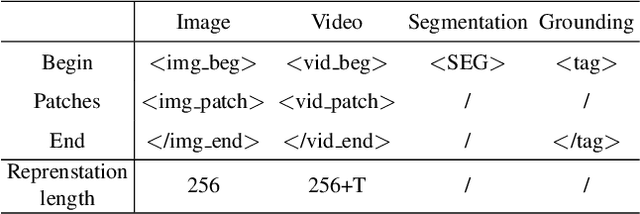

Recent advances such as LLaVA and Mini-GPT4 have successfully integrated visual information into LLMs, yielding inspiring outcomes and giving rise to a new generation of multi-modal LLMs, or MLLMs. Nevertheless, these methods struggle with hallucinations and the mutual interference between tasks. To tackle these problems, we propose an efficient and accurate approach to adapt to downstream tasks by utilizing LLM as a bridge to connect multiple expert models, namely u-LLaVA. Firstly, we incorporate the modality alignment module and multi-task modules into LLM. Then, we reorganize or rebuild multi-type public datasets to enable efficient modality alignment and instruction following. Finally, task-specific information is extracted from the trained LLM and provided to different modules for solving downstream tasks. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. We also release our model, the generated data, and the code base publicly available.
Inject Semantic Concepts into Image Tagging for Open-Set Recognition
Oct 23, 2023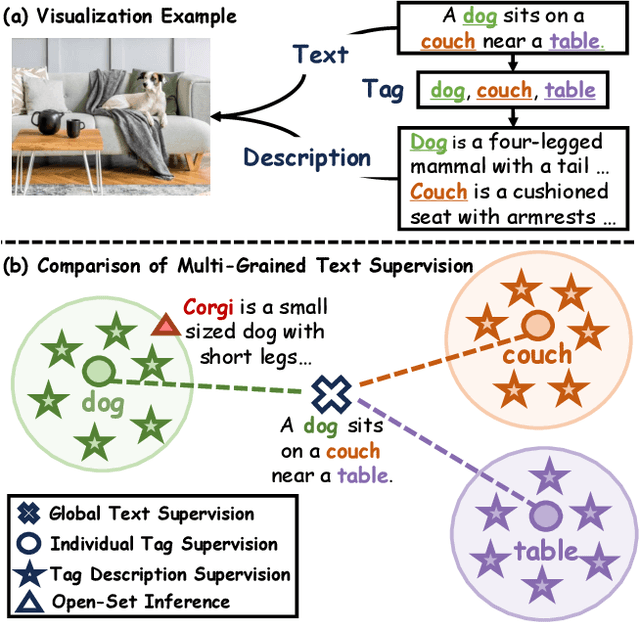
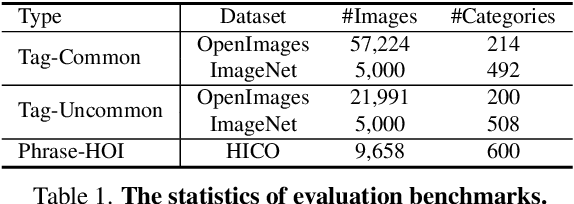
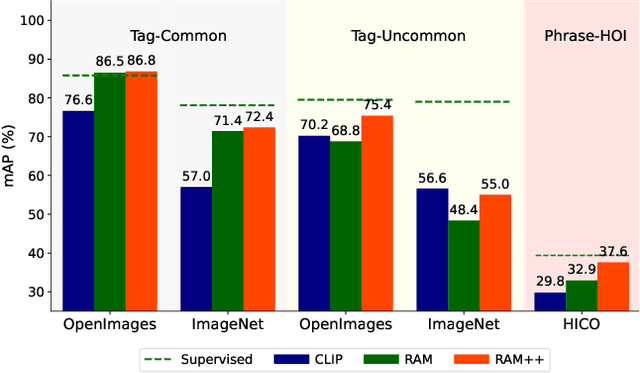
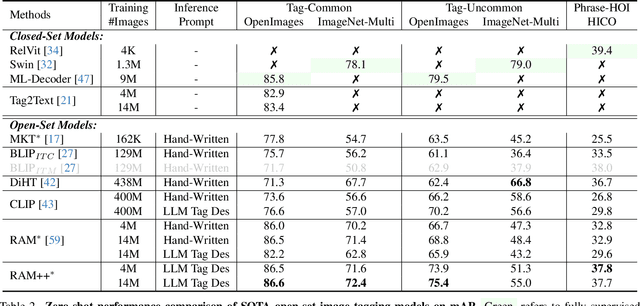
In this paper, we introduce the Recognize Anything Plus Model~(RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition. In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM++ not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories. Moreover, RAM++ employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM's knowledge into image tagging training. This approach empowers RAM++ to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate RAM++ exceeds existing state-of-the-art (SOTA) fundamental image recognition models on most aspects. Specifically, for predefined common-used tag categories, RAM++ showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet. For open-set categories beyond predefined, RAM++ records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM++ achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark. Code, datasets and pre-trained models are available at \url{https://github.com/xinyu1205/recognize-anything}.
Prototype Fission: Closing Set for Robust Open-set Semi-supervised Learning
Aug 29, 2023



Semi-supervised Learning (SSL) has been proven vulnerable to out-of-distribution (OOD) samples in realistic large-scale unsupervised datasets due to over-confident pseudo-labeling OODs as in-distribution (ID). A key underlying problem is class-wise latent space spreading from closed seen space to open unseen space, and the bias is further magnified in SSL's self-training loops. To close the ID distribution set so that OODs are better rejected for safe SSL, we propose Prototype Fission(PF) to divide class-wise latent spaces into compact sub-spaces by automatic fine-grained latent space mining, driven by coarse-grained labels only. Specifically, we form multiple unique learnable sub-class prototypes for each class, optimized towards both diversity and consistency. The Diversity Modeling term encourages samples to be clustered by one of the multiple sub-class prototypes, while the Consistency Modeling term clusters all samples of the same class to a global prototype. Instead of "opening set", i.e., modeling OOD distribution, Prototype Fission "closes set" and makes it hard for OOD samples to fit in sub-class latent space. Therefore, PF is compatible with existing methods for further performance gains. Extensive experiments validate the effectiveness of our method in open-set SSL settings in terms of successfully forming sub-classes, discriminating OODs from IDs and improving overall accuracy. Codes will be released.
3D RoI-aware U-Net for Accurate and Efficient Colorectal Tumor Segmentation
Jul 19, 2018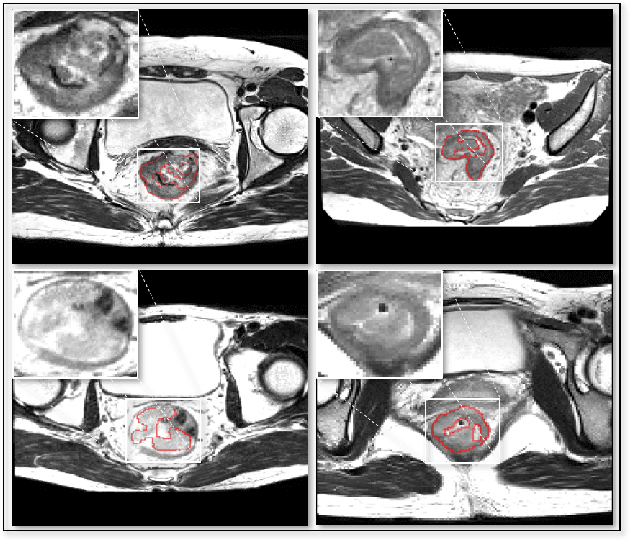
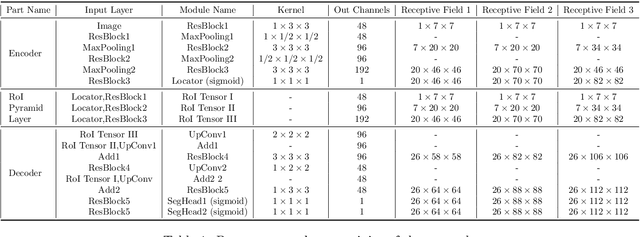
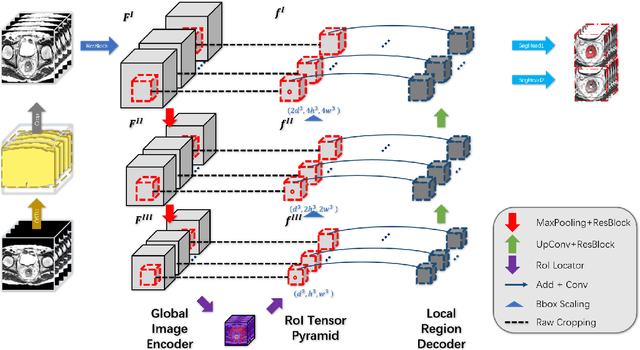

Segmentation of colorectal cancerous regions from Magnetic Resonance (MR) images is a crucial procedure for radiotherapy which conventionally requires accurate delineation of tumour boundaries at an expense of labor, time and reproducibility. To address this important yet challenging task within the framework of performance-leading deep learning methods, regions of interest (RoIs) localization from large whole volume 3D images serves as a preceding operation that brings about multiple benefits in terms of speed, target completeness and reduction of false positives. Distinct from sliding window or discrete localization-segmentation based models, we propose a novel multi-task framework referred to as 3D RoI-aware U-Net (3D RU-Net), for RoI localization and intra-RoI segmentation where the two tasks share one backbone encoder network. With the region proposals from the encoder, we crop multi-level feature maps from the backbone network to form a GPU memory-efficient decoder for detail-preserving intra-RoI segmentation. To effectively train the model, we designed a Dice formulated loss function for the global-to-local multi-task learning procedure. Based on the promising efficiency gains demonstrated by the proposed method, we went on to ensemble multiple models to achieve even higher performance costing minor extra computational expensiveness. Extensive experiments were subsequently conducted on 64 cancerous cases with a four-fold cross-validation, and the results showed significant superiority in terms of accuracy and efficiency over conventional state-of-the art frameworks. In conclusion, the proposed method has a huge potential for extension to other 3D object segmentation tasks from medical images due to its inherent generalizability. The code for the proposed method is publicly available.