 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSMOS: Multi-organ segmentation facilitated by medical report supervision
Sep 04, 2024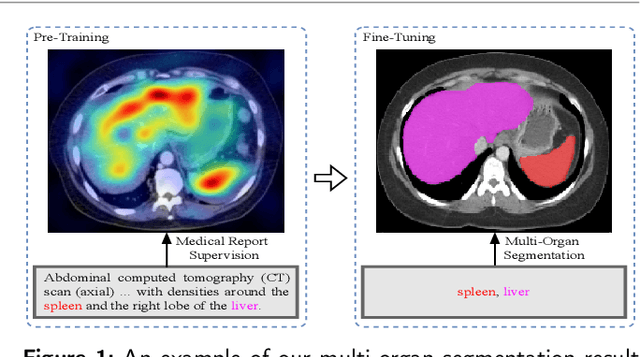
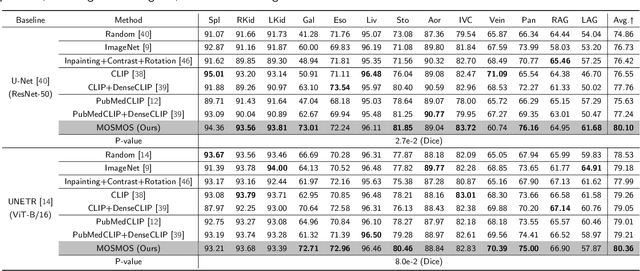
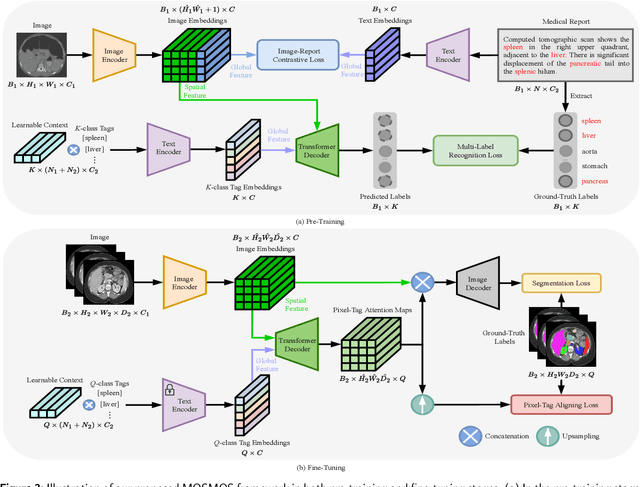
Owing to a large amount of multi-modal data in modern medical systems, such as medical images and reports, Medical Vision-Language Pre-training (Med-VLP) has demonstrated incredible achievements in coarse-grained downstream tasks (i.e., medical classification, retrieval, and visual question answering). However, the problem of transferring knowledge learned from Med-VLP to fine-grained multi-organ segmentation tasks has barely been investigated. Multi-organ segmentation is challenging mainly due to the lack of large-scale fully annotated datasets and the wide variation in the shape and size of the same organ between individuals with different diseases. In this paper, we propose a novel pre-training & fine-tuning framework for Multi-Organ Segmentation by harnessing Medical repOrt Supervision (MOSMOS). Specifically, we first introduce global contrastive learning to maximally align the medical image-report pairs in the pre-training stage. To remedy the granularity discrepancy, we further leverage multi-label recognition to implicitly learn the semantic correspondence between image pixels and organ tags. More importantly, our pre-trained models can be transferred to any segmentation model by introducing the pixel-tag attention maps. Different network settings, i.e., 2D U-Net and 3D UNETR, are utilized to validate the generalization. We have extensively evaluated our approach using different diseases and modalities on BTCV, AMOS, MMWHS, and BRATS datasets. Experimental results in various settings demonstrate the effectiveness of our framework. This framework can serve as the foundation to facilitate future research on automatic annotation tasks under the supervision of medical reports.