 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo as the New Language for Real-World Decision Making
Paper and Code
Feb 27, 2024


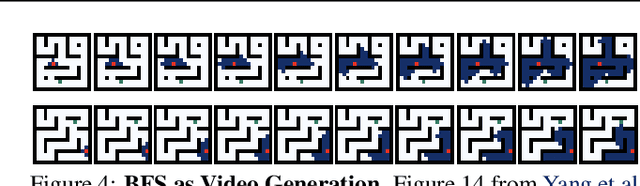
Both text and video data are abundant on the internet and support large-scale self-supervised learning through next token or frame prediction. However, they have not been equally leveraged: language models have had significant real-world impact, whereas video generation has remained largely limited to media entertainment. Yet video data captures important information about the physical world that is difficult to express in language. To address this gap, we discuss an under-appreciated opportunity to extend video generation to solve tasks in the real world. We observe how, akin to language, video can serve as a unified interface that can absorb internet knowledge and represent diverse tasks. Moreover, we demonstrate how, like language models, video generation can serve as planners, agents, compute engines, and environment simulators through techniques such as in-context learning, planning and reinforcement learning. We identify major impact opportunities in domains such as robotics, self-driving, and science, supported by recent work that demonstrates how such advanced capabilities in video generation are plausibly within reach. Lastly, we identify key challenges in video generation that mitigate progress. Addressing these challenges will enable video generation models to demonstrate unique value alongside language models in a wider array of AI applications.