 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster WIND: Accelerating Iterative Best-of-$N$ Distillation for LLM Alignment
Oct 28, 2024


Recent advances in aligning large language models with human preferences have corroborated the growing importance of best-of-N distillation (BOND). However, the iterative BOND algorithm is prohibitively expensive in practice due to the sample and computation inefficiency. This paper addresses the problem by revealing a unified game-theoretic connection between iterative BOND and self-play alignment, which unifies seemingly disparate algorithmic paradigms. Based on the connection, we establish a novel framework, WIN rate Dominance (WIND), with a series of efficient algorithms for regularized win rate dominance optimization that approximates iterative BOND in the parameter space. We provides provable sample efficiency guarantee for one of the WIND variant with the square loss objective. The experimental results confirm that our algorithm not only accelerates the computation, but also achieves superior sample efficiency compared to existing methods.
Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF
May 29, 2024


Reinforcement learning from human feedback (RLHF) has demonstrated great promise in aligning large language models (LLMs) with human preference. Depending on the availability of preference data, both online and offline RLHF are active areas of investigation. A key bottleneck is understanding how to incorporate uncertainty estimation in the reward function learned from the preference data for RLHF, regardless of how the preference data is collected. While the principles of optimism or pessimism under uncertainty are well-established in standard reinforcement learning (RL), a practically-implementable and theoretically-grounded form amenable to large language models is not yet available, as standard techniques for constructing confidence intervals become intractable under arbitrary policy parameterizations. In this paper, we introduce a unified approach to online and offline RLHF -- value-incentivized preference optimization (VPO) -- which regularizes the maximum-likelihood estimate of the reward function with the corresponding value function, modulated by a $\textit{sign}$ to indicate whether the optimism or pessimism is chosen. VPO also directly optimizes the policy with implicit reward modeling, and therefore shares a simpler RLHF pipeline similar to direct preference optimization. Theoretical guarantees of VPO are provided for both online and offline settings, matching the rates of their standard RL counterparts. Moreover, experiments on text summarization and dialog verify the practicality and effectiveness of VPO.
Beyond Expectations: Learning with Stochastic Dominance Made Practical
Feb 05, 2024



Stochastic dominance models risk-averse preferences for decision making with uncertain outcomes, which naturally captures the intrinsic structure of the underlying uncertainty, in contrast to simply resorting to the expectations. Despite theoretically appealing, the application of stochastic dominance in machine learning has been scarce, due to the following challenges: $\textbf{i)}$, the original concept of stochastic dominance only provides a $\textit{partial order}$, therefore, is not amenable to serve as an optimality criterion; and $\textbf{ii)}$, an efficient computational recipe remains lacking due to the continuum nature of evaluating stochastic dominance.%, which barriers its application for machine learning. In this work, we make the first attempt towards establishing a general framework of learning with stochastic dominance. We first generalize the stochastic dominance concept to enable feasible comparisons between any arbitrary pair of random variables. We next develop a simple and computationally efficient approach for finding the optimal solution in terms of stochastic dominance, which can be seamlessly plugged into many learning tasks. Numerical experiments demonstrate that the proposed method achieves comparable performance as standard risk-neutral strategies and obtains better trade-offs against risk across a variety of applications including supervised learning, reinforcement learning, and portfolio optimization.
Federated Natural Policy Gradient Methods for Multi-task Reinforcement Learning
Nov 01, 2023Federated reinforcement learning (RL) enables collaborative decision making of multiple distributed agents without sharing local data trajectories. In this work, we consider a multi-task setting, in which each agent has its own private reward function corresponding to different tasks, while sharing the same transition kernel of the environment. Focusing on infinite-horizon tabular Markov decision processes, the goal is to learn a globally optimal policy that maximizes the sum of the discounted total rewards of all the agents in a decentralized manner, where each agent only communicates with its neighbors over some prescribed graph topology. We develop federated vanilla and entropy-regularized natural policy gradient (NPG) methods under softmax parameterization, where gradient tracking is applied to the global Q-function to mitigate the impact of imperfect information sharing. We establish non-asymptotic global convergence guarantees under exact policy evaluation, which are nearly independent of the size of the state-action space and illuminate the impacts of network size and connectivity. To the best of our knowledge, this is the first time that global convergence is established for federated multi-task RL using policy optimization. Moreover, the convergence behavior of the proposed algorithms is robust against inexactness of policy evaluation.
Global Convergence of Policy Gradient Methods in Reinforcement Learning, Games and Control
Oct 08, 2023

Policy gradient methods, where one searches for the policy of interest by maximizing the value functions using first-order information, become increasingly popular for sequential decision making in reinforcement learning, games, and control. Guaranteeing the global optimality of policy gradient methods, however, is highly nontrivial due to nonconcavity of the value functions. In this exposition, we highlight recent progresses in understanding and developing policy gradient methods with global convergence guarantees, putting an emphasis on their finite-time convergence rates with regard to salient problem parameters.
Asynchronous Gradient Play in Zero-Sum Multi-agent Games
Nov 16, 2022


Finding equilibria via gradient play in competitive multi-agent games has been attracting a growing amount of attention in recent years, with emphasis on designing efficient strategies where the agents operate in a decentralized and symmetric manner with guaranteed convergence. While significant efforts have been made in understanding zero-sum two-player matrix games, the performance in zero-sum multi-agent games remains inadequately explored, especially in the presence of delayed feedbacks, leaving the scalability and resiliency of gradient play open to questions. In this paper, we make progress by studying asynchronous gradient plays in zero-sum polymatrix games under delayed feedbacks. We first establish that the last iterate of entropy-regularized optimistic multiplicative weight updates (OMWU) method converges linearly to the quantal response equilibrium (QRE), the solution concept under bounded rationality, in the absence of delays. While the linear convergence continues to hold even when the feedbacks are randomly delayed under mild statistical assumptions, it converges at a noticeably slower rate due to a smaller tolerable range of learning rates. Moving beyond, we demonstrate entropy-regularized OMWU -- by adopting two-timescale learning rates in a delay-aware manner -- enjoys faster last-iterate convergence under fixed delays, and continues to converge provably even when the delays are arbitrarily bounded in an average-iterate manner. Our methods also lead to finite-time guarantees to approximate the Nash equilibrium (NE) by moderating the amount of regularization. To the best of our knowledge, this work is the first that aims to understand asynchronous gradient play in zero-sum polymatrix games under a wide range of delay assumptions, highlighting the role of learning rates separation.
Faster Last-iterate Convergence of Policy Optimization in Zero-Sum Markov Games
Oct 04, 2022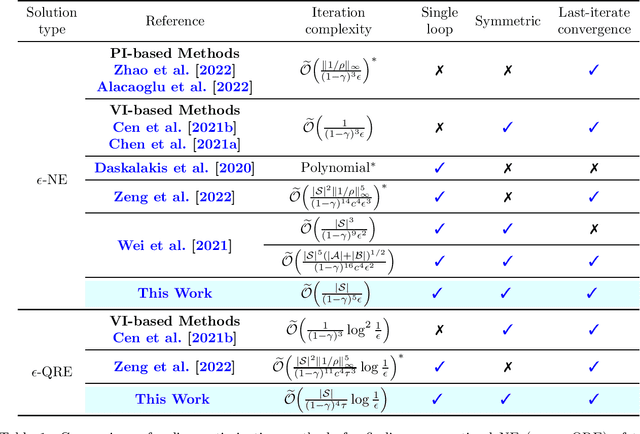
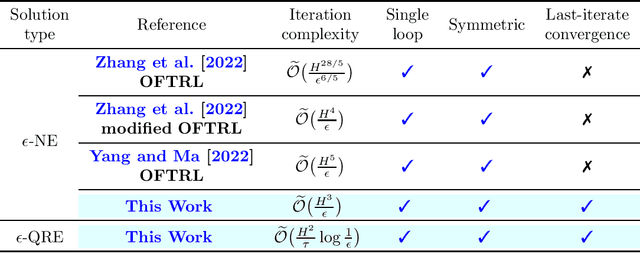
Multi-Agent Reinforcement Learning (MARL) -- where multiple agents learn to interact in a shared dynamic environment -- permeates across a wide range of critical applications. While there has been substantial progress on understanding the global convergence of policy optimization methods in single-agent RL, designing and analysis of efficient policy optimization algorithms in the MARL setting present significant challenges, which unfortunately, remain highly inadequately addressed by existing theory. In this paper, we focus on the most basic setting of competitive multi-agent RL, namely two-player zero-sum Markov games, and study equilibrium finding algorithms in both the infinite-horizon discounted setting and the finite-horizon episodic setting. We propose a single-loop policy optimization method with symmetric updates from both agents, where the policy is updated via the entropy-regularized optimistic multiplicative weights update (OMWU) method and the value is updated on a slower timescale. We show that, in the full-information tabular setting, the proposed method achieves a finite-time last-iterate linear convergence to the quantal response equilibrium of the regularized problem, which translates to a sublinear last-iterate convergence to the Nash equilibrium by controlling the amount of regularization. Our convergence results improve upon the best known iteration complexities, and lead to a better understanding of policy optimization in competitive Markov games.
Independent Natural Policy Gradient Methods for Potential Games: Finite-time Global Convergence with Entropy Regularization
Apr 12, 2022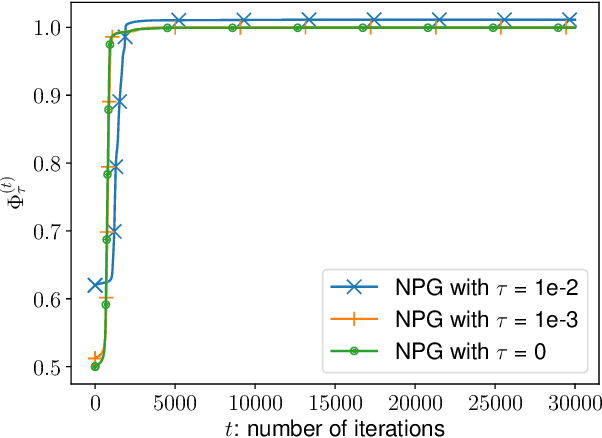
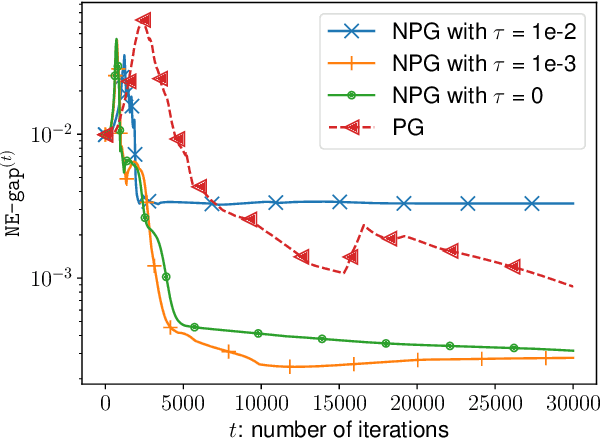
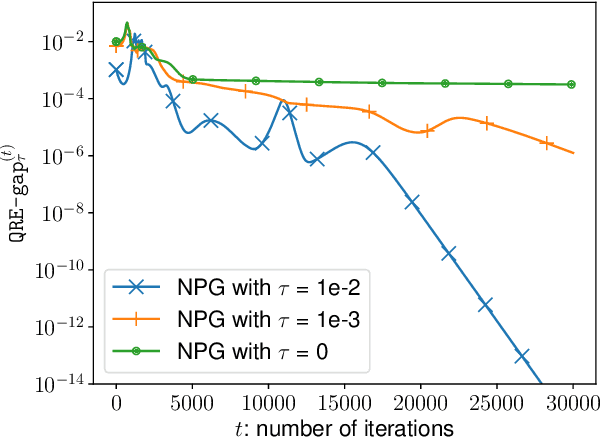
A major challenge in multi-agent systems is that the system complexity grows dramatically with the number of agents as well as the size of their action spaces, which is typical in real world scenarios such as autonomous vehicles, robotic teams, network routing, etc. It is hence in imminent need to design decentralized or independent algorithms where the update of each agent is only based on their local observations without the need of introducing complex communication/coordination mechanisms. In this work, we study the finite-time convergence of independent entropy-regularized natural policy gradient (NPG) methods for potential games, where the difference in an agent's utility function due to unilateral deviation matches exactly that of a common potential function. The proposed entropy-regularized NPG method enables each agent to deploy symmetric, decentralized, and multiplicative updates according to its own payoff. We show that the proposed method converges to the quantal response equilibrium (QRE) -- the equilibrium to the entropy-regularized game -- at a sublinear rate, which is independent of the size of the action space and grows at most sublinearly with the number of agents. Appealingly, the convergence rate further becomes independent with the number of agents for the important special case of identical-interest games, leading to the first method that converges at a dimension-free rate. Our approach can be used as a smoothing technique to find an approximate Nash equilibrium (NE) of the unregularized problem without assuming that stationary policies are isolated.
Fast Policy Extragradient Methods for Competitive Games with Entropy Regularization
May 31, 2021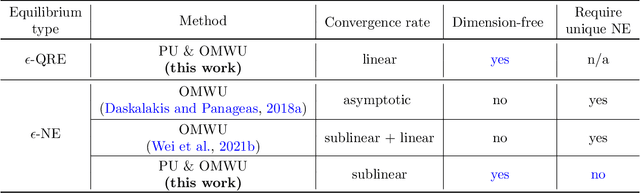
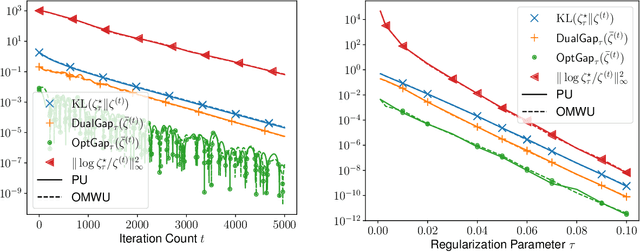
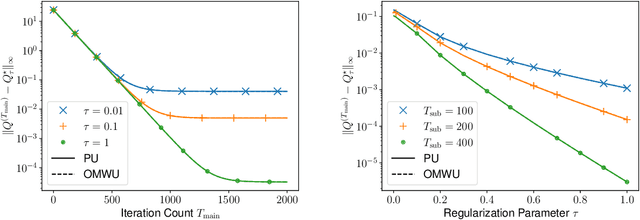
This paper investigates the problem of computing the equilibrium of competitive games, which is often modeled as a constrained saddle-point optimization problem with probability simplex constraints. Despite recent efforts in understanding the last-iterate convergence of extragradient methods in the unconstrained setting, the theoretical underpinnings of these methods in the constrained settings, especially those using multiplicative updates, remain highly inadequate, even when the objective function is bilinear. Motivated by the algorithmic role of entropy regularization in single-agent reinforcement learning and game theory, we develop provably efficient extragradient methods to find the quantal response equilibrium (QRE) -- which are solutions to zero-sum two-player matrix games with entropy regularization -- at a linear rate. The proposed algorithms can be implemented in a decentralized manner, where each player executes symmetric and multiplicative updates iteratively using its own payoff without observing the opponent's actions directly. In addition, by controlling the knob of entropy regularization, the proposed algorithms can locate an approximate Nash equilibrium of the unregularized matrix game at a sublinear rate without assuming the Nash equilibrium to be unique. Our methods also lead to efficient policy extragradient algorithms for solving entropy-regularized zero-sum Markov games at a linear rate. All of our convergence rates are nearly dimension-free, which are independent of the size of the state and action spaces up to logarithm factors, highlighting the positive role of entropy regularization for accelerating convergence.
Policy Mirror Descent for Regularized Reinforcement Learning: A Generalized Framework with Linear Convergence
May 24, 2021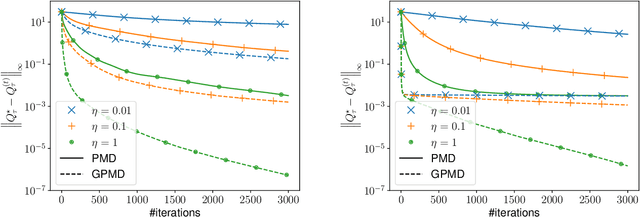
Policy optimization, which learns the policy of interest by maximizing the value function via large-scale optimization techniques, lies at the heart of modern reinforcement learning (RL). In addition to value maximization, other practical considerations arise commonly as well, including the need of encouraging exploration, and that of ensuring certain structural properties of the learned policy due to safety, resource and operational constraints. These considerations can often be accounted for by resorting to regularized RL, which augments the target value function with a structure-promoting regularization term. Focusing on an infinite-horizon discounted Markov decision process, this paper proposes a generalized policy mirror descent (GPMD) algorithm for solving regularized RL. As a generalization of policy mirror descent Lan (2021), the proposed algorithm accommodates a general class of convex regularizers as well as a broad family of Bregman divergence in cognizant of the regularizer in use. We demonstrate that our algorithm converges linearly over an entire range of learning rates, in a dimension-free fashion, to the global solution, even when the regularizer lacks strong convexity and smoothness. In addition, this linear convergence feature is provably stable in the face of inexact policy evaluation and imperfect policy updates. Numerical experiments are provided to corroborate the applicability and appealing performance of GPMD.