 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Mirror Descent for Regularized Reinforcement Learning: A Generalized Framework with Linear Convergence
Paper and Code
May 24, 2021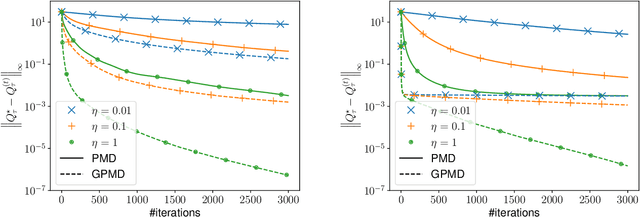
Policy optimization, which learns the policy of interest by maximizing the value function via large-scale optimization techniques, lies at the heart of modern reinforcement learning (RL). In addition to value maximization, other practical considerations arise commonly as well, including the need of encouraging exploration, and that of ensuring certain structural properties of the learned policy due to safety, resource and operational constraints. These considerations can often be accounted for by resorting to regularized RL, which augments the target value function with a structure-promoting regularization term. Focusing on an infinite-horizon discounted Markov decision process, this paper proposes a generalized policy mirror descent (GPMD) algorithm for solving regularized RL. As a generalization of policy mirror descent Lan (2021), the proposed algorithm accommodates a general class of convex regularizers as well as a broad family of Bregman divergence in cognizant of the regularizer in use. We demonstrate that our algorithm converges linearly over an entire range of learning rates, in a dimension-free fashion, to the global solution, even when the regularizer lacks strong convexity and smoothness. In addition, this linear convergence feature is provably stable in the face of inexact policy evaluation and imperfect policy updates. Numerical experiments are provided to corroborate the applicability and appealing performance of GPMD.