 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProper Reuse of Image Classification Features Improves Object Detection
Paper and Code
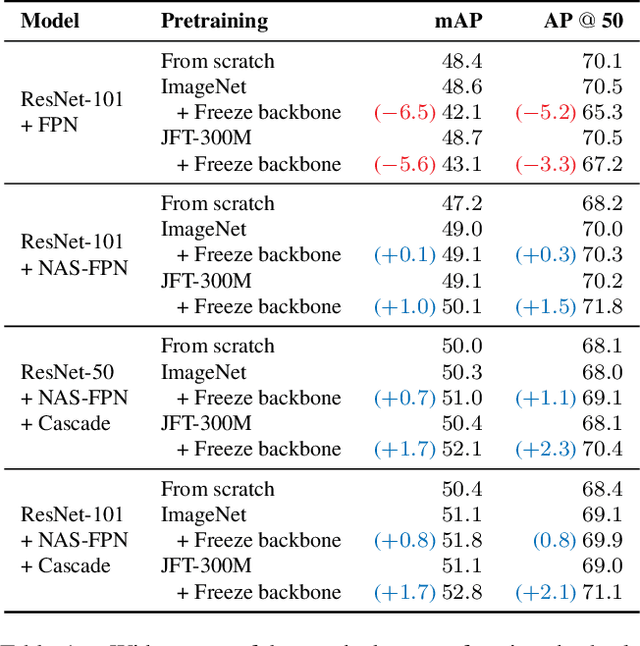
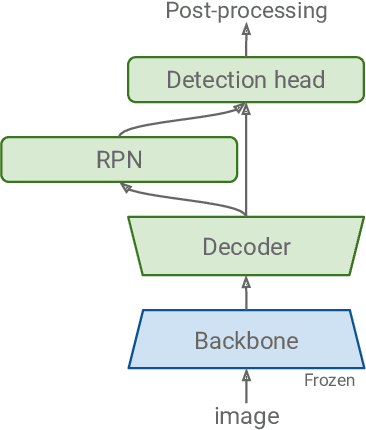
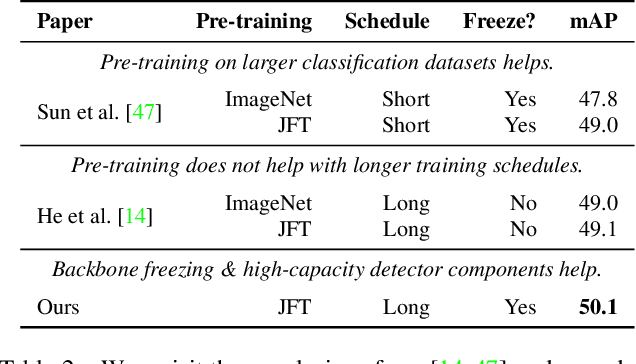

A common practice in transfer learning is to initialize the downstream model weights by pre-training on a data-abundant upstream task. In object detection specifically, the feature backbone is typically initialized with Imagenet classifier weights and fine-tuned on the object detection task. Recent works show this is not strictly necessary under longer training regimes and provide recipes for training the backbone from scratch. We investigate the opposite direction of this end-to-end training trend: we show that an extreme form of knowledge preservation -- freezing the classifier-initialized backbone -- consistently improves many different detection models, and leads to considerable resource savings. We hypothesize and corroborate experimentally that the remaining detector components capacity and structure is a crucial factor in leveraging the frozen backbone. Immediate applications of our findings include performance improvements on hard cases like detection of long-tail object classes and computational and memory resource savings that contribute to making the field more accessible to researchers with access to fewer computational resources.