 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamViG: Camera Aware Image-to-Video Generation with Multimodal Transformers
May 21, 2024



We extend multimodal transformers to include 3D camera motion as a conditioning signal for the task of video generation. Generative video models are becoming increasingly powerful, thus focusing research efforts on methods of controlling the output of such models. We propose to add virtual 3D camera controls to generative video methods by conditioning generated video on an encoding of three-dimensional camera movement over the course of the generated video. Results demonstrate that we are (1) able to successfully control the camera during video generation, starting from a single frame and a camera signal, and (2) we demonstrate the accuracy of the generated 3D camera paths using traditional computer vision methods.
SLAIM: Robust Dense Neural SLAM for Online Tracking and Mapping
Apr 17, 2024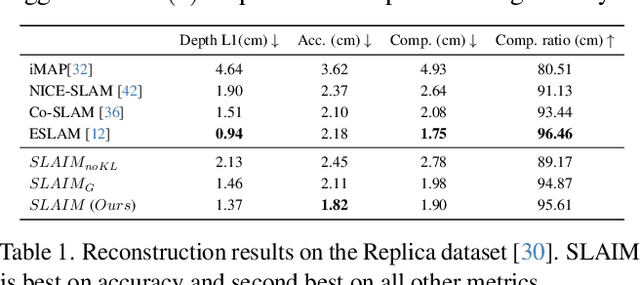
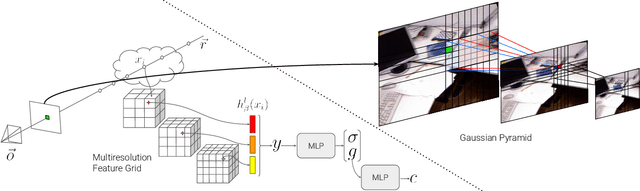
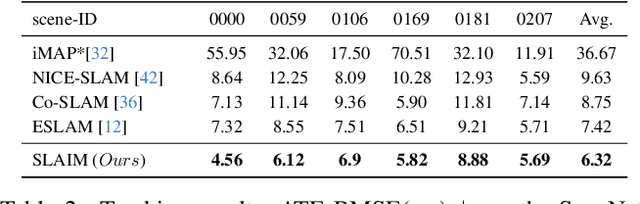
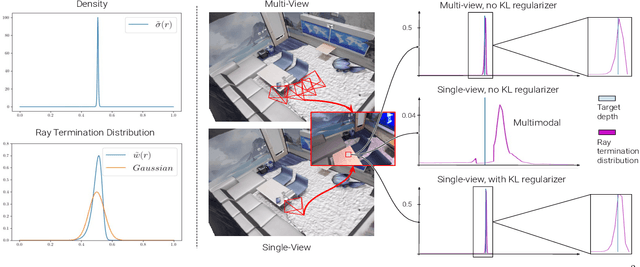
We present SLAIM - Simultaneous Localization and Implicit Mapping. We propose a novel coarse-to-fine tracking model tailored for Neural Radiance Field SLAM (NeRF-SLAM) to achieve state-of-the-art tracking performance. Notably, existing NeRF-SLAM systems consistently exhibit inferior tracking performance compared to traditional SLAM algorithms. NeRF-SLAM methods solve camera tracking via image alignment and photometric bundle-adjustment. Such optimization processes are difficult to optimize due to the narrow basin of attraction of the optimization loss in image space (local minima) and the lack of initial correspondences. We mitigate these limitations by implementing a Gaussian pyramid filter on top of NeRF, facilitating a coarse-to-fine tracking optimization strategy. Furthermore, NeRF systems encounter challenges in converging to the right geometry with limited input views. While prior approaches use a Signed-Distance Function (SDF)-based NeRF and directly supervise SDF values by approximating ground truth SDF through depth measurements, this often results in suboptimal geometry. In contrast, our method employs a volume density representation and introduces a novel KL regularizer on the ray termination distribution, constraining scene geometry to consist of empty space and opaque surfaces. Our solution implements both local and global bundle-adjustment to produce a robust (coarse-to-fine) and accurate (KL regularizer) SLAM solution. We conduct experiments on multiple datasets (ScanNet, TUM, Replica) showing state-of-the-art results in tracking and in reconstruction accuracy.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Augmenting Bag-of-Words: Data-Driven Discovery of Temporal and Structural Information for Activity Recognition
Oct 07, 2015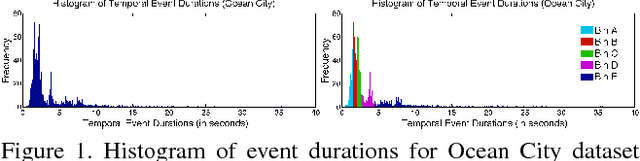

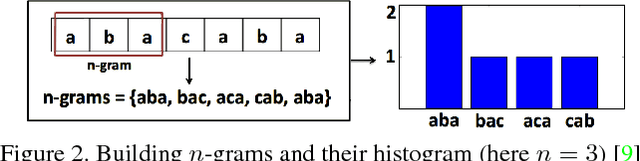
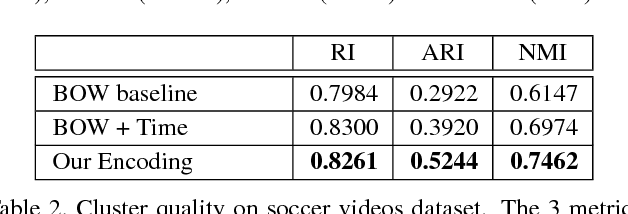
We present data-driven techniques to augment Bag of Words (BoW) models, which allow for more robust modeling and recognition of complex long-term activities, especially when the structure and topology of the activities are not known a priori. Our approach specifically addresses the limitations of standard BoW approaches, which fail to represent the underlying temporal and causal information that is inherent in activity streams. In addition, we also propose the use of randomly sampled regular expressions to discover and encode patterns in activities. We demonstrate the effectiveness of our approach in experimental evaluations where we successfully recognize activities and detect anomalies in four complex datasets.
* 8 pages