 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo and Accelerometer-Based Motion Analysis for Automated Surgical Skills Assessment
Feb 24, 2017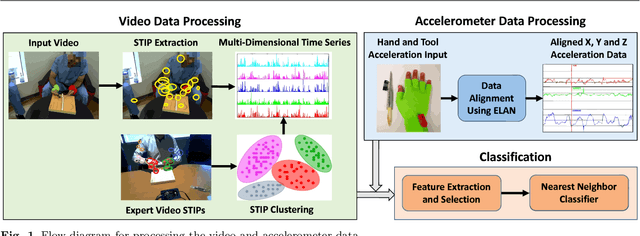
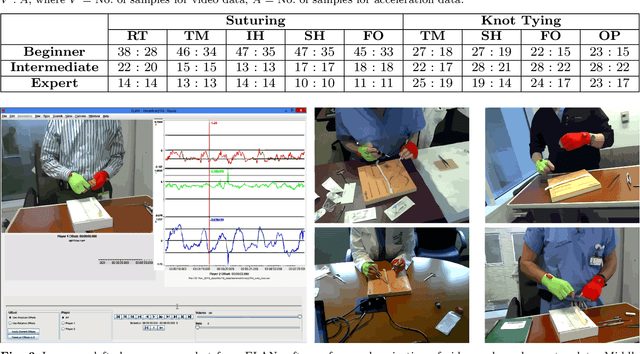

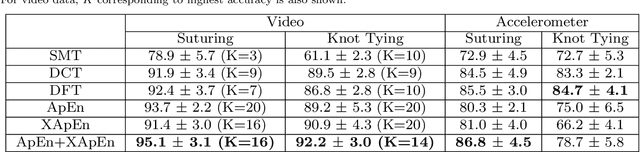
Purpose: Basic surgical skills of suturing and knot tying are an essential part of medical training. Having an automated system for surgical skills assessment could help save experts time and improve training efficiency. There have been some recent attempts at automated surgical skills assessment using either video analysis or acceleration data. In this paper, we present a novel approach for automated assessment of OSATS based surgical skills and provide an analysis of different features on multi-modal data (video and accelerometer data). Methods: We conduct the largest study, to the best of our knowledge, for basic surgical skills assessment on a dataset that contained video and accelerometer data for suturing and knot-tying tasks. We introduce "entropy based" features - Approximate Entropy (ApEn) and Cross-Approximate Entropy (XApEn), which quantify the amount of predictability and regularity of fluctuations in time-series data. The proposed features are compared to existing methods of Sequential Motion Texture (SMT), Discrete Cosine Transform (DCT) and Discrete Fourier Transform (DFT), for surgical skills assessment. Results: We report average performance of different features across all applicable OSATS criteria for suturing and knot tying tasks. Our analysis shows that the proposed entropy based features out-perform previous state-of-the-art methods using video data. For accelerometer data, our method performs better for suturing only. We also show that fusion of video and acceleration features can improve overall performance with the proposed entropy features achieving highest accuracy. Conclusions: Automated surgical skills assessment can be achieved with high accuracy using the proposed entropy features. Such a system can significantly improve the efficiency of surgical training in medical schools and teaching hospitals.
Discovering Picturesque Highlights from Egocentric Vacation Videos
Jan 18, 2016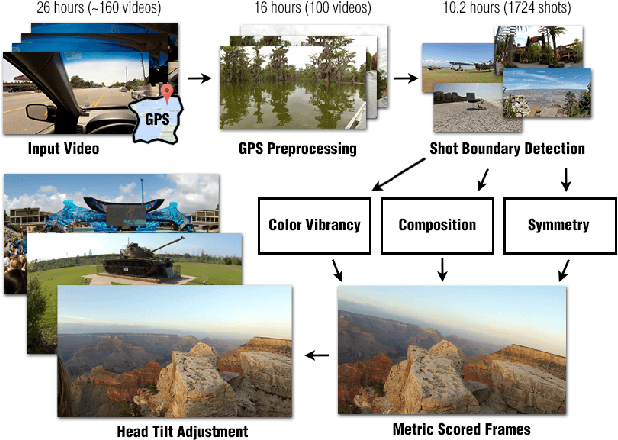



We present an approach for identifying picturesque highlights from large amounts of egocentric video data. Given a set of egocentric videos captured over the course of a vacation, our method analyzes the videos and looks for images that have good picturesque and artistic properties. We introduce novel techniques to automatically determine aesthetic features such as composition, symmetry and color vibrancy in egocentric videos and rank the video frames based on their photographic qualities to generate highlights. Our approach also uses contextual information such as GPS, when available, to assess the relative importance of each geographic location where the vacation videos were shot. Furthermore, we specifically leverage the properties of egocentric videos to improve our highlight detection. We demonstrate results on a new egocentric vacation dataset which includes 26.5 hours of videos taken over a 14 day vacation that spans many famous tourist destinations and also provide results from a user-study to access our results.
Leveraging Context to Support Automated Food Recognition in Restaurants
Oct 07, 2015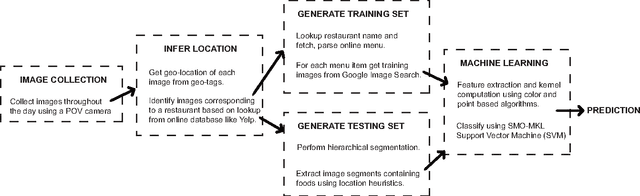
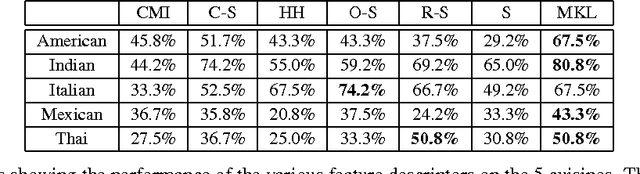


The pervasiveness of mobile cameras has resulted in a dramatic increase in food photos, which are pictures reflecting what people eat. In this paper, we study how taking pictures of what we eat in restaurants can be used for the purpose of automating food journaling. We propose to leverage the context of where the picture was taken, with additional information about the restaurant, available online, coupled with state-of-the-art computer vision techniques to recognize the food being consumed. To this end, we demonstrate image-based recognition of foods eaten in restaurants by training a classifier with images from restaurant's online menu databases. We evaluate the performance of our system in unconstrained, real-world settings with food images taken in 10 restaurants across 5 different types of food (American, Indian, Italian, Mexican and Thai).
Egocentric Field-of-View Localization Using First-Person Point-of-View Devices
Oct 07, 2015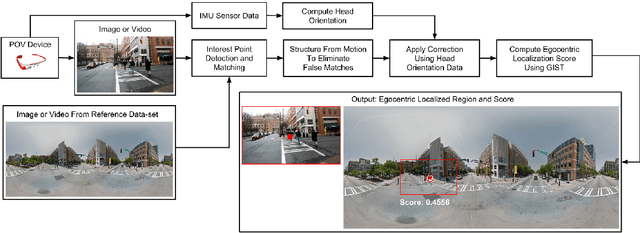
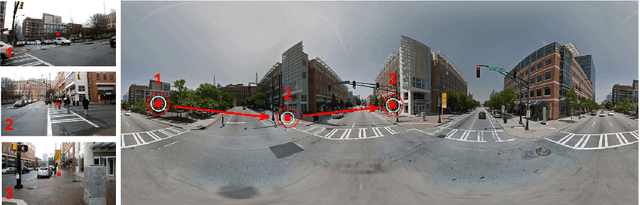


We present a technique that uses images, videos and sensor data taken from first-person point-of-view devices to perform egocentric field-of-view (FOV) localization. We define egocentric FOV localization as capturing the visual information from a person's field-of-view in a given environment and transferring this information onto a reference corpus of images and videos of the same space, hence determining what a person is attending to. Our method matches images and video taken from the first-person perspective with the reference corpus and refines the results using the first-person's head orientation information obtained using the device sensors. We demonstrate single and multi-user egocentric FOV localization in different indoor and outdoor environments with applications in augmented reality, event understanding and studying social interactions.
Augmenting Bag-of-Words: Data-Driven Discovery of Temporal and Structural Information for Activity Recognition
Oct 07, 2015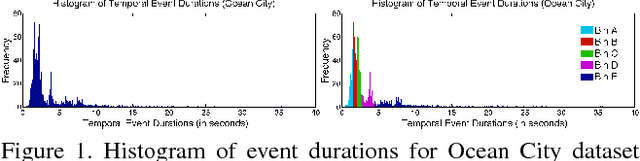

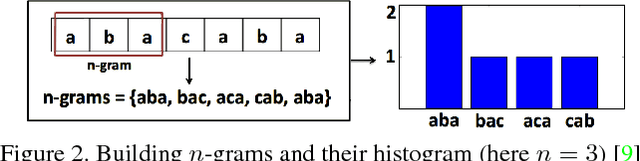
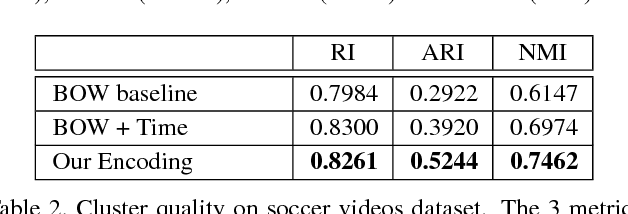
We present data-driven techniques to augment Bag of Words (BoW) models, which allow for more robust modeling and recognition of complex long-term activities, especially when the structure and topology of the activities are not known a priori. Our approach specifically addresses the limitations of standard BoW approaches, which fail to represent the underlying temporal and causal information that is inherent in activity streams. In addition, we also propose the use of randomly sampled regular expressions to discover and encode patterns in activities. We demonstrate the effectiveness of our approach in experimental evaluations where we successfully recognize activities and detect anomalies in four complex datasets.
* 8 pages
Predicting Daily Activities From Egocentric Images Using Deep Learning
Oct 06, 2015
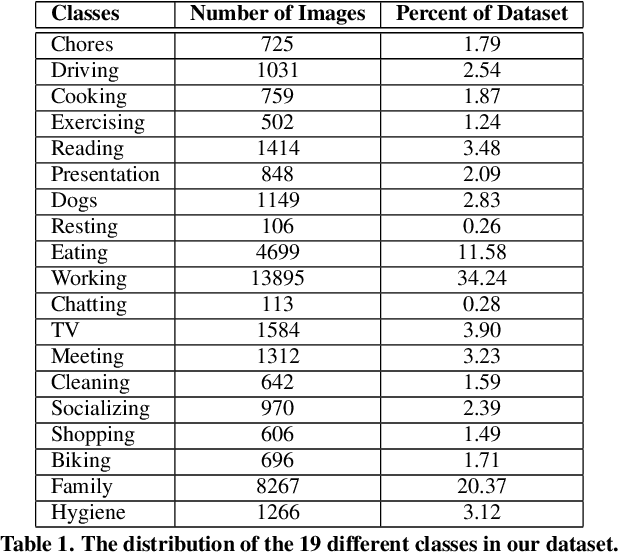

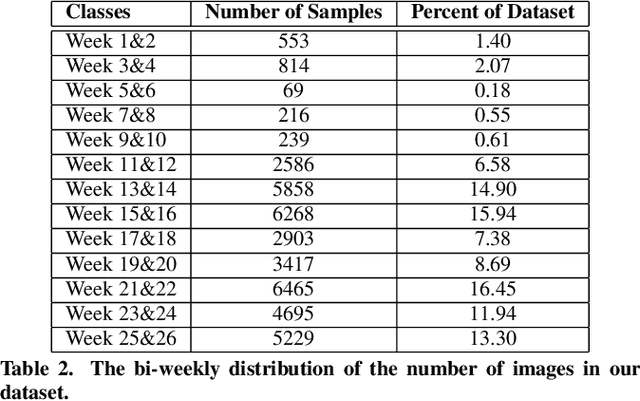
We present a method to analyze images taken from a passive egocentric wearable camera along with the contextual information, such as time and day of week, to learn and predict everyday activities of an individual. We collected a dataset of 40,103 egocentric images over a 6 month period with 19 activity classes and demonstrate the benefit of state-of-the-art deep learning techniques for learning and predicting daily activities. Classification is conducted using a Convolutional Neural Network (CNN) with a classification method we introduce called a late fusion ensemble. This late fusion ensemble incorporates relevant contextual information and increases our classification accuracy. Our technique achieves an overall accuracy of 83.07% in predicting a person's activity across the 19 activity classes. We also demonstrate some promising results from two additional users by fine-tuning the classifier with one day of training data.
* 8 pages
Face Expression Recognition and Analysis: The State of the Art
Mar 30, 2012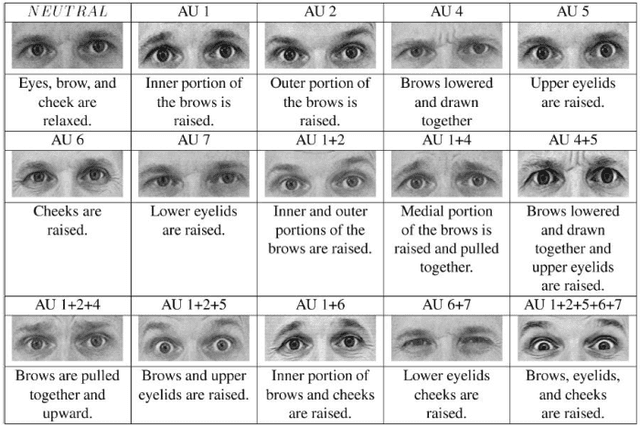
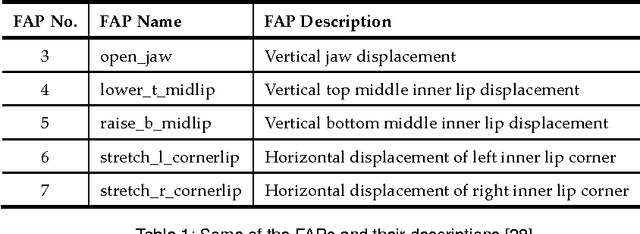


The automatic recognition of facial expressions has been an active research topic since the early nineties. There have been several advances in the past few years in terms of face detection and tracking, feature extraction mechanisms and the techniques used for expression classification. This paper surveys some of the published work since 2001 till date. The paper presents a time-line view of the advances made in this field, the applications of automatic face expression recognizers, the characteristics of an ideal system, the databases that have been used and the advances made in terms of their standardization and a detailed summary of the state of the art. The paper also discusses facial parameterization using FACS Action Units (AUs) and MPEG-4 Facial Animation Parameters (FAPs) and the recent advances in face detection, tracking and feature extraction methods. Notes have also been presented on emotions, expressions and facial features, discussion on the six prototypic expressions and the recent studies on expression classifiers. The paper ends with a note on the challenges and the future work. This paper has been written in a tutorial style with the intention of helping students and researchers who are new to this field.