 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
CamViG: Camera Aware Image-to-Video Generation with Multimodal Transformers
May 21, 2024



We extend multimodal transformers to include 3D camera motion as a conditioning signal for the task of video generation. Generative video models are becoming increasingly powerful, thus focusing research efforts on methods of controlling the output of such models. We propose to add virtual 3D camera controls to generative video methods by conditioning generated video on an encoding of three-dimensional camera movement over the course of the generated video. Results demonstrate that we are (1) able to successfully control the camera during video generation, starting from a single frame and a camera signal, and (2) we demonstrate the accuracy of the generated 3D camera paths using traditional computer vision methods.
Probabilistic Tracking with Deep Factors
Dec 02, 2021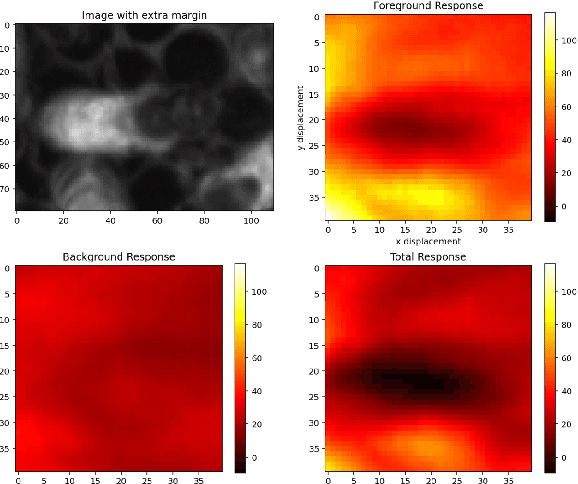
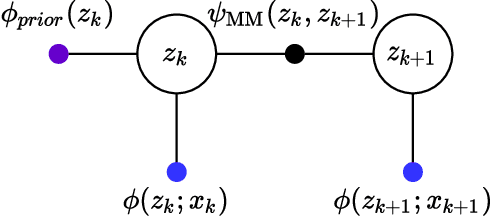

In many applications of computer vision it is important to accurately estimate the trajectory of an object over time by fusing data from a number of sources, of which 2D and 3D imagery is only one. In this paper, we show how to use a deep feature encoding in conjunction with generative densities over the features in a factor-graph based, probabilistic tracking framework. We present a likelihood model that combines a learned feature encoder with generative densities over them, both trained in a supervised manner. We also experiment with directly inferring probability through the use of image classification models that feed into the likelihood formulation. These models are used to implement deep factors that are added to the factor graph to complement other factors that represent domain-specific knowledge such as motion models and/or other prior information. Factors are then optimized together in a non-linear least-squares tracking framework that takes the form of an Extended Kalman Smoother with a Gaussian prior. A key feature of our likelihood model is that it leverages the Lie group properties of the tracked target's pose to apply the feature encoding on an image patch, extracted through a differentiable warp function inspired by spatial transformer networks. To illustrate the proposed approach we evaluate it on a challenging social insect behavior dataset, and show that using deep features does outperform these earlier linear appearance models used in this setting.