 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral-Purpose OCR Paragraph Identification by Graph Convolutional Neural Networks
Feb 01, 2021
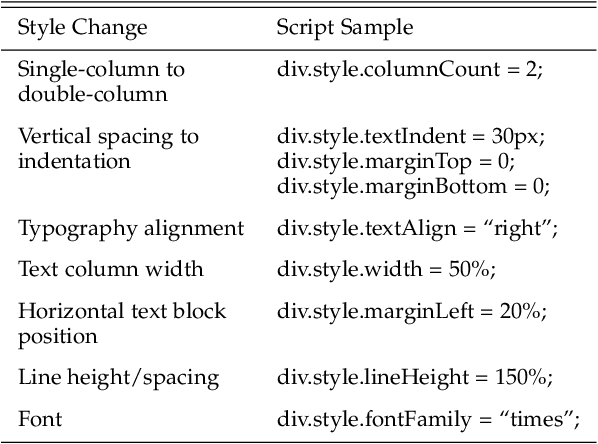
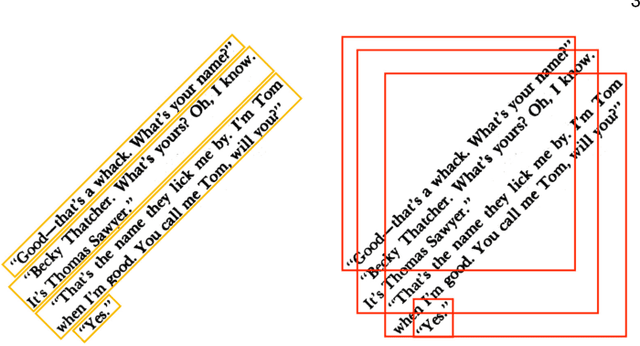
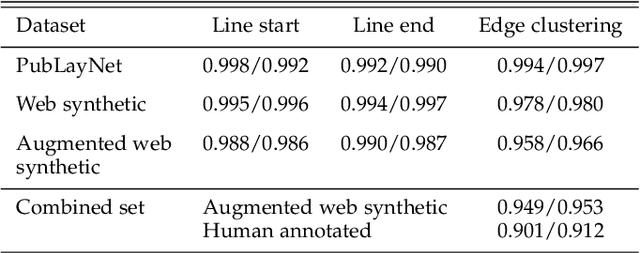
Paragraphs are an important class of document entities. We propose a new approach for paragraph identification by spatial graph convolutional neural networks (GCN) applied on OCR text boxes. Two steps, namely line splitting and line clustering, are performed to extract paragraphs from the lines in OCR results. Each step uses a beta-skeleton graph constructed from bounding boxes, where the graph edges provide efficient support for graph convolution operations. With only pure layout input features, the GCN model size is 3~4 orders of magnitude smaller compared to R-CNN based models, while achieving comparable or better accuracies on PubLayNet and other datasets. Furthermore, the GCN models show good generalization from synthetic training data to real-world images, and good adaptivity for variable document styles.
Coincidence, Categorization, and Consolidation: Learning to Recognize Sounds with Minimal Supervision
Nov 14, 2019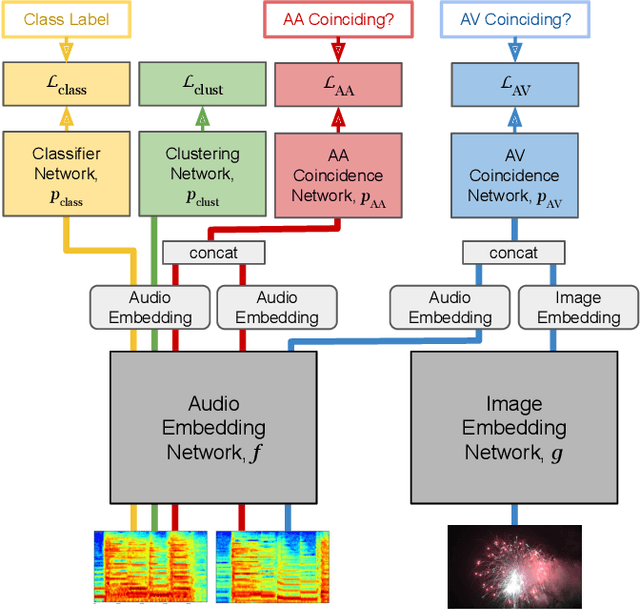
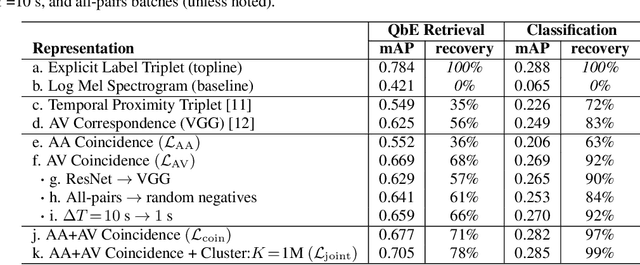
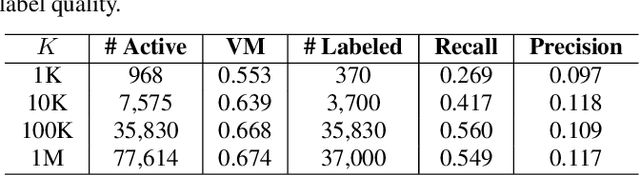
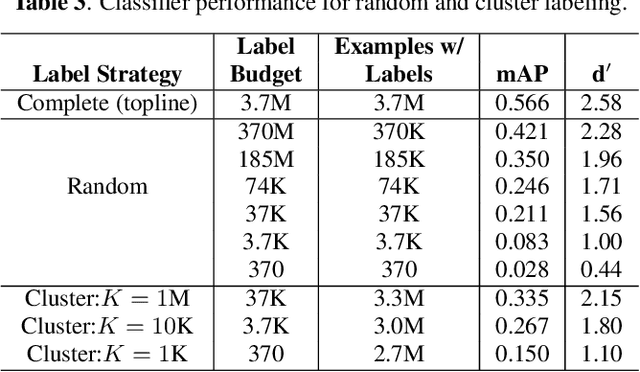
Humans do not acquire perceptual abilities in the way we train machines. While machine learning algorithms typically operate on large collections of randomly-chosen, explicitly-labeled examples, human acquisition relies more heavily on multimodal unsupervised learning (as infants) and active learning (as children). With this motivation, we present a learning framework for sound representation and recognition that combines (i) a self-supervised objective based on a general notion of unimodal and cross-modal coincidence, (ii) a clustering objective that reflects our need to impose categorical structure on our experiences, and (iii) a cluster-based active learning procedure that solicits targeted weak supervision to consolidate categories into relevant semantic classes. By training a combined sound embedding/clustering/classification network according to these criteria, we achieve a new state-of-the-art unsupervised audio representation and demonstrate up to a 20-fold reduction in the number of labels required to reach a desired classification performance.
A Scalable Handwritten Text Recognition System
Apr 19, 2019
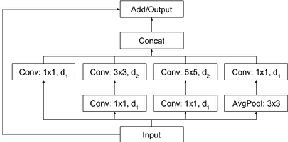


Many studies on (Offline) Handwritten Text Recognition (HTR) systems have focused on building state-of-the-art models for line recognition on small corpora. However, adding HTR capability to a large scale multilingual OCR system poses new challenges. This paper addresses three problems in building such systems: data, efficiency, and integration. Firstly, one of the biggest challenges is obtaining sufficient amounts of high quality training data. We address the problem by using online handwriting data collected for a large scale production online handwriting recognition system. We describe our image data generation pipeline and study how online data can be used to build HTR models. We show that the data improve the models significantly under the condition where only a small number of real images is available, which is usually the case for HTR models. It enables us to support a new script at substantially lower cost. Secondly, we propose a line recognition model based on neural networks without recurrent connections. The model achieves a comparable accuracy with LSTM-based models while allowing for better parallelism in training and inference. Finally, we present a simple way to integrate HTR models into an OCR system. These constitute a solution to bring HTR capability into a large scale OCR system.
Sequence-to-Label Script Identification for Multilingual OCR
Aug 17, 2017
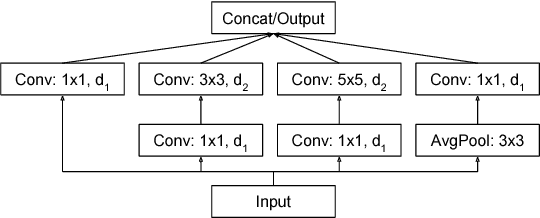

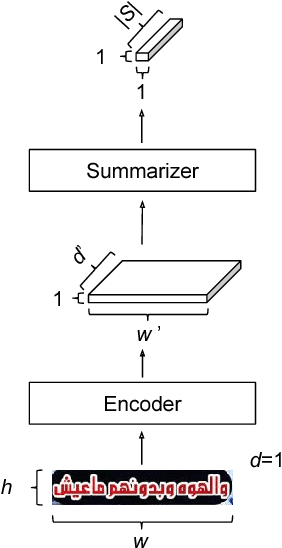
We describe a novel line-level script identification method. Previous work repurposed an OCR model generating per-character script codes, counted to obtain line-level script identification. This has two shortcomings. First, as a sequence-to-sequence model it is more complex than necessary for the sequence-to-label problem of line script identification. This makes it harder to train and inefficient to run. Second, the counting heuristic may be suboptimal compared to a learned model. Therefore we reframe line script identification as a sequence-to-label problem and solve it using two components, trained end-toend: Encoder and Summarizer. The encoder converts a line image into a feature sequence. The summarizer aggregates the sequence to classify the line. We test various summarizers with identical inception-style convolutional networks as encoders. Experiments on scanned books and photos containing 232 languages in 30 scripts show 16% reduction of script identification error rate compared to the baseline. This improved script identification reduces the character error rate attributable to script misidentification by 33%.