 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Incubation -- Synthesizing Missing Data for Handwriting Recognition
Oct 13, 2021
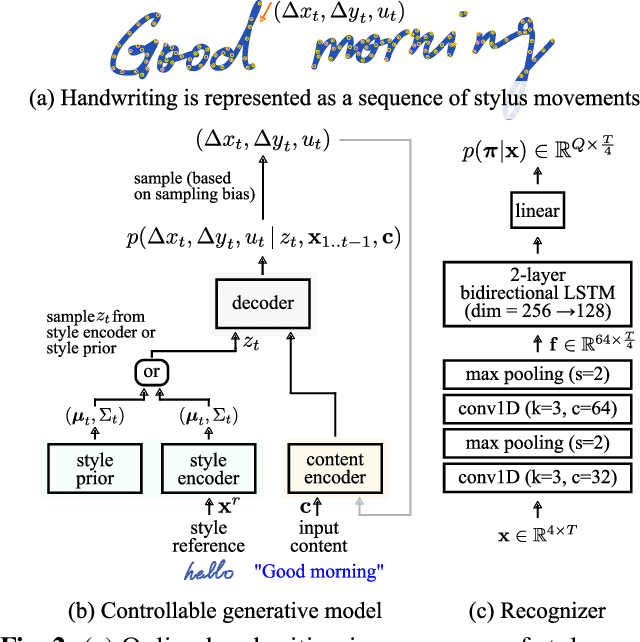
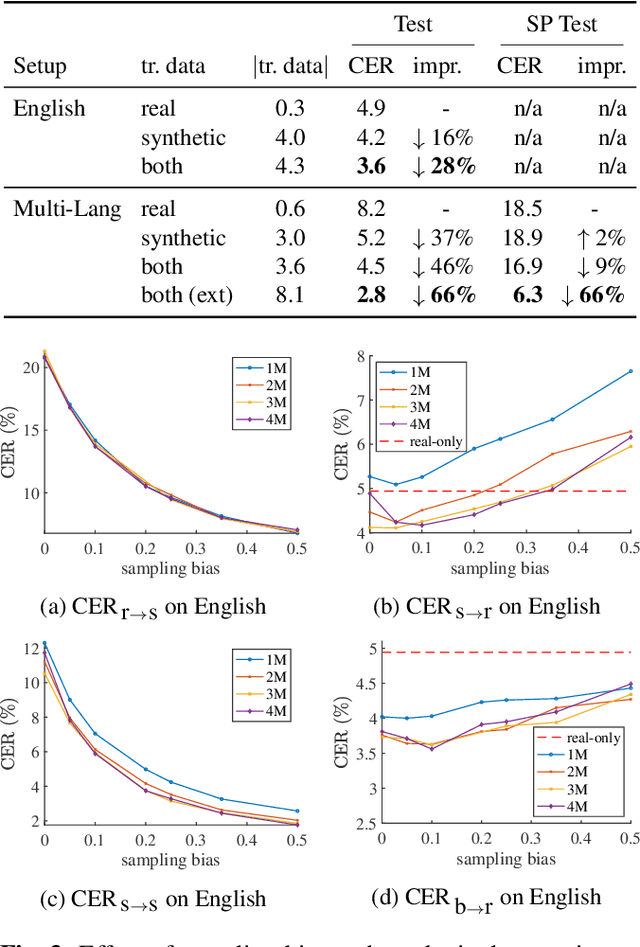
In this paper, we demonstrate how a generative model can be used to build a better recognizer through the control of content and style. We are building an online handwriting recognizer from a modest amount of training samples. By training our controllable handwriting synthesizer on the same data, we can synthesize handwriting with previously underrepresented content (e.g., URLs and email addresses) and style (e.g., cursive and slanted). Moreover, we propose a framework to analyze a recognizer that is trained with a mixture of real and synthetic training data. We use the framework to optimize data synthesis and demonstrate significant improvement on handwriting recognition over a model trained on real data only. Overall, we achieve a 66% reduction in Character Error Rate.
CoSE: Compositional Stroke Embeddings
Jun 17, 2020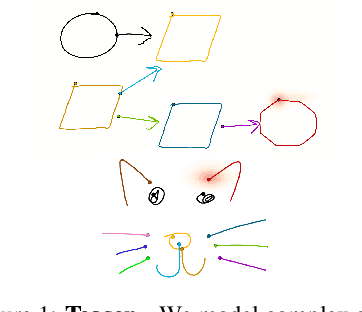
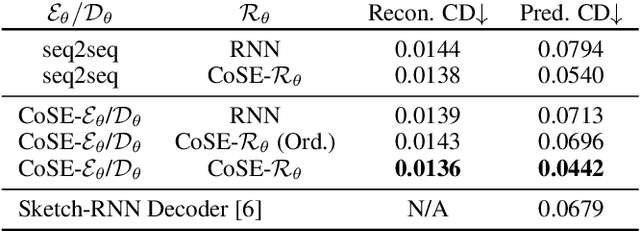
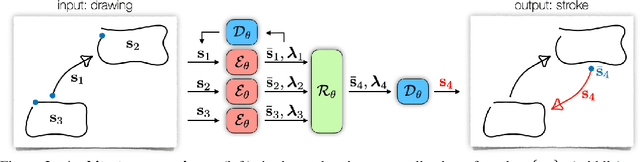
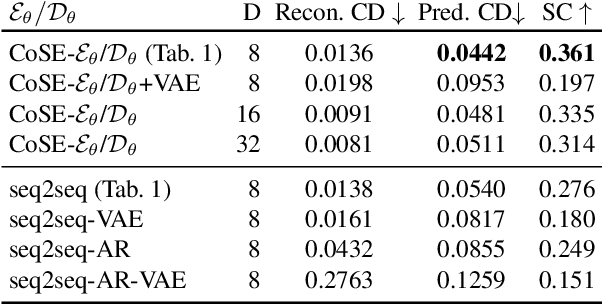
We present a generative model for stroke-based drawing tasks which is able to model complex free-form structures. While previous approaches rely on sequence-based models for drawings of basic objects or handwritten text, we propose a model that treats drawings as a collection of strokes that can be composed into complex structures such as diagrams (e.g., flow-charts). At the core of the approach lies a novel auto-encoder that projects variable-length strokes into a latent space of fixed dimension. This representation space allows a relational model, operating in latent space, to better capture the relationship between strokes and to predict subsequent strokes. We demonstrate qualitatively and quantitatively that our proposed approach is able to model the appearance of individual strokes, as well as the compositional structure of larger diagram drawings. Our approach is suitable for interactive use cases such as auto-completing diagrams.
The DIDI dataset: Digital Ink Diagram data
Feb 24, 2020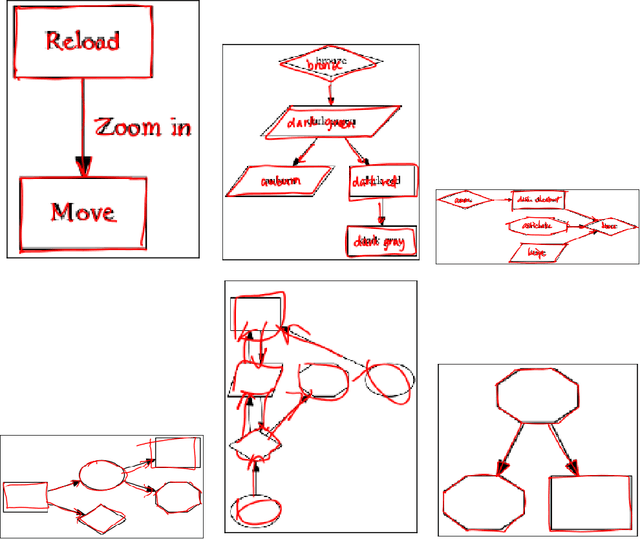
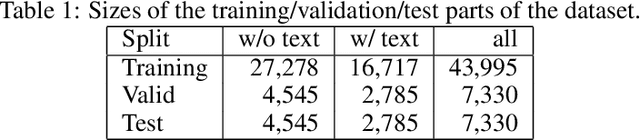
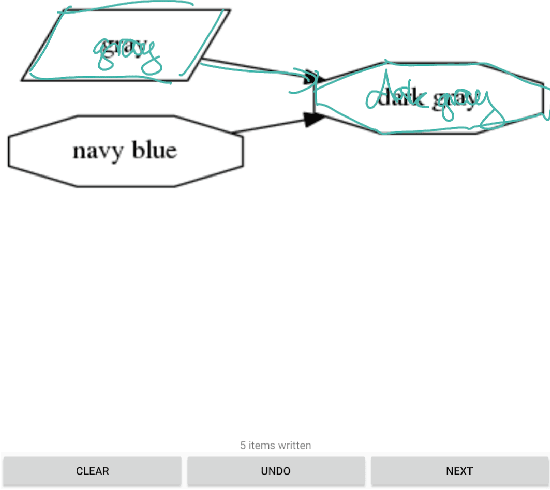
We are releasing a dataset of diagram drawings with dynamic drawing information. The dataset aims to foster research in interactive graphical symbolic understanding. The dataset was obtained using a prompted data collection effort.
A Scalable Handwritten Text Recognition System
Apr 19, 2019
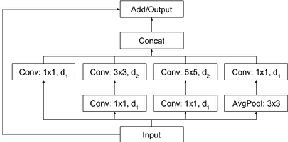


Many studies on (Offline) Handwritten Text Recognition (HTR) systems have focused on building state-of-the-art models for line recognition on small corpora. However, adding HTR capability to a large scale multilingual OCR system poses new challenges. This paper addresses three problems in building such systems: data, efficiency, and integration. Firstly, one of the biggest challenges is obtaining sufficient amounts of high quality training data. We address the problem by using online handwriting data collected for a large scale production online handwriting recognition system. We describe our image data generation pipeline and study how online data can be used to build HTR models. We show that the data improve the models significantly under the condition where only a small number of real images is available, which is usually the case for HTR models. It enables us to support a new script at substantially lower cost. Secondly, we propose a line recognition model based on neural networks without recurrent connections. The model achieves a comparable accuracy with LSTM-based models while allowing for better parallelism in training and inference. Finally, we present a simple way to integrate HTR models into an OCR system. These constitute a solution to bring HTR capability into a large scale OCR system.
IndyLSTMs: Independently Recurrent LSTMs
Mar 19, 2019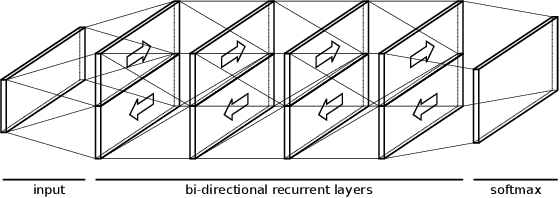
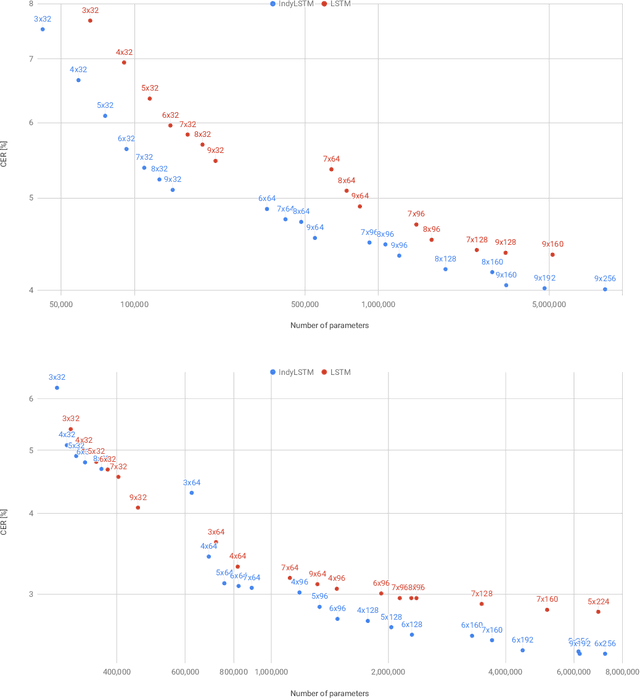
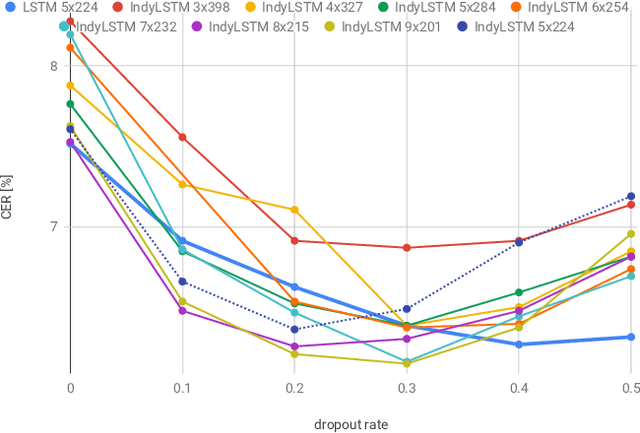
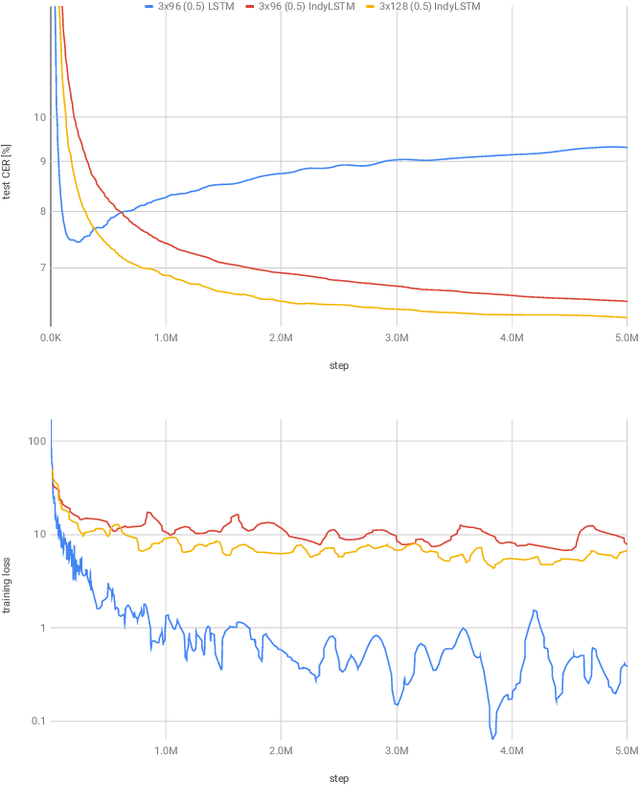
We introduce Independently Recurrent Long Short-term Memory cells: IndyLSTMs. These differ from regular LSTM cells in that the recurrent weights are not modeled as a full matrix, but as a diagonal matrix, i.e.\ the output and state of each LSTM cell depends on the inputs and its own output/state, as opposed to the input and the outputs/states of all the cells in the layer. The number of parameters per IndyLSTM layer, and thus the number of FLOPS per evaluation, is linear in the number of nodes in the layer, as opposed to quadratic for regular LSTM layers, resulting in potentially both smaller and faster models. We evaluate their performance experimentally by training several models on the popular \iamondb and CASIA online handwriting datasets, as well as on several of our in-house datasets. We show that IndyLSTMs, despite their smaller size, consistently outperform regular LSTMs both in terms of accuracy per parameter, and in best accuracy overall. We attribute this improved performance to the IndyLSTMs being less prone to overfitting.
Fast Multi-language LSTM-based Online Handwriting Recognition
Feb 22, 2019
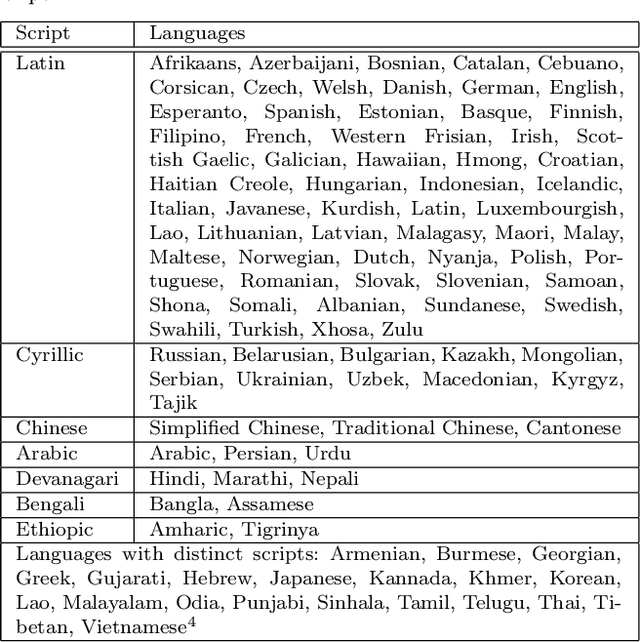
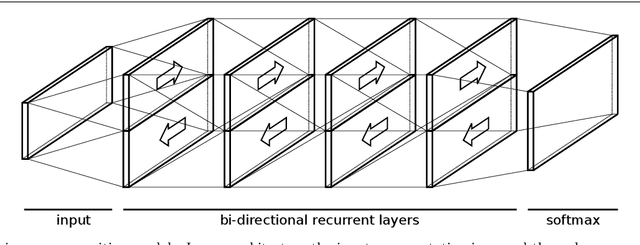
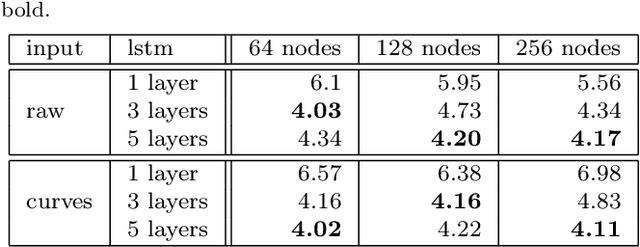
We describe an online handwriting system that is able to support 102 languages using a deep neural network architecture. This new system has completely replaced our previous Segment-and-Decode-based system and reduced the error rate by 20%-40% relative for most languages. Further, we report new state-of-the-art results on IAM-OnDB for both the open and closed dataset setting. The system combines methods from sequence recognition with a new input encoding using B\'ezier curves. This leads to up to 10x faster recognition times compared to our previous system. Through a series of experiments we determine the optimal configuration of our models and report the results of our setup on a number of additional public datasets.
Predicted Variables in Programming
Oct 01, 2018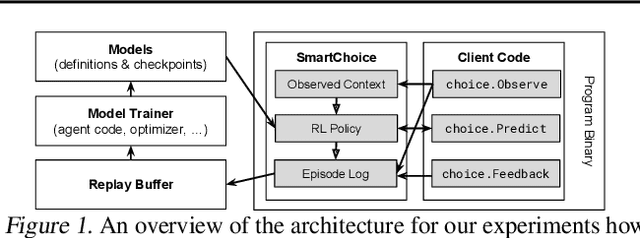
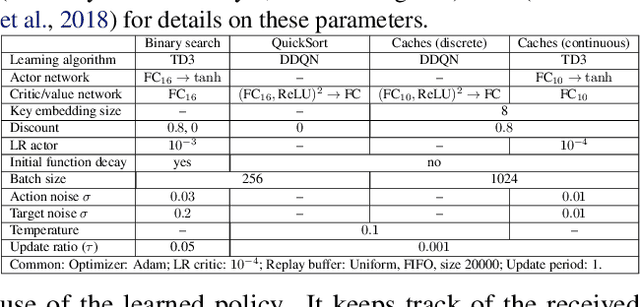
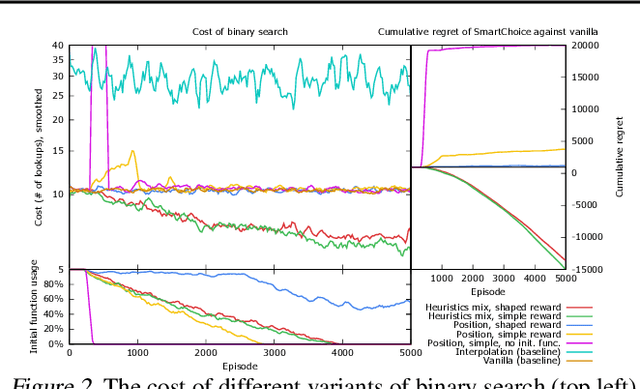
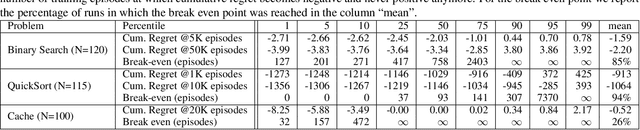
We present Predicted Variables (PVars), an approach to making machine learning (ML) a first class citizen in programming languages. There is a growing divide in approaches to building systems: using human experts (e.g. programming) on the one hand, and using behavior learned from data (e.g. ML) on the other hand. PVars aim to make ML in programming as easy as `if' statements and with that hybridize ML with programming. We leverage the existing concept of variables and create a new type, a predicted variable. PVars are akin to native variables with one important distinction: PVars determine their value using ML when evaluated. We describe PVars and their interface, how they can be used in programming, and demonstrate the feasibility of our approach on three algorithmic problems: binary search, Quicksort, and caches. We show experimentally that PVars are able to improve over the commonly used heuristics and lead to a better performance than the original algorithms. As opposed to previous work applying ML to algorithmic problems, PVars have the advantage that they can be used within the existing frameworks and do not require the existing domain knowledge to be replaced. PVars allow for a seamless integration of ML into existing systems and algorithms. Our PVars implementation currently relies on standard Reinforcement Learning (RL) methods. To learn faster, PVars use the heuristic function, which they are replacing, as an initial function. We show that PVars quickly pick up the behavior of the initial function and then improve performance beyond that without ever performing substantially worse -- allowing for a safe deployment in critical applications.