 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Incubation -- Synthesizing Missing Data for Handwriting Recognition
Oct 13, 2021
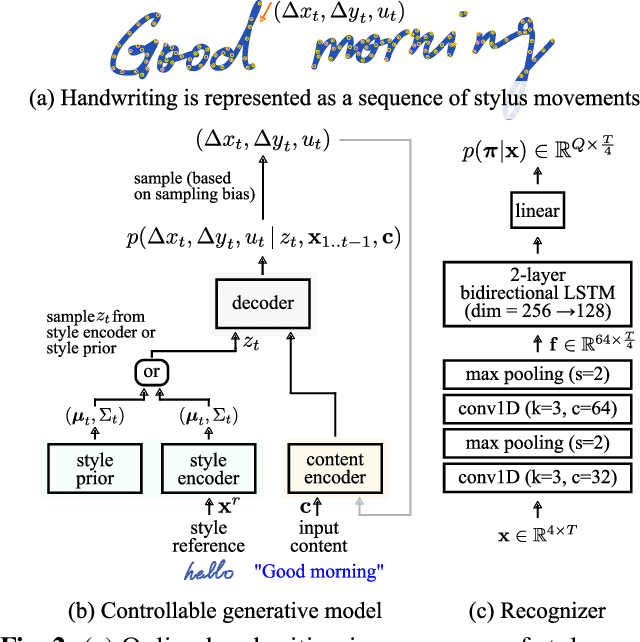
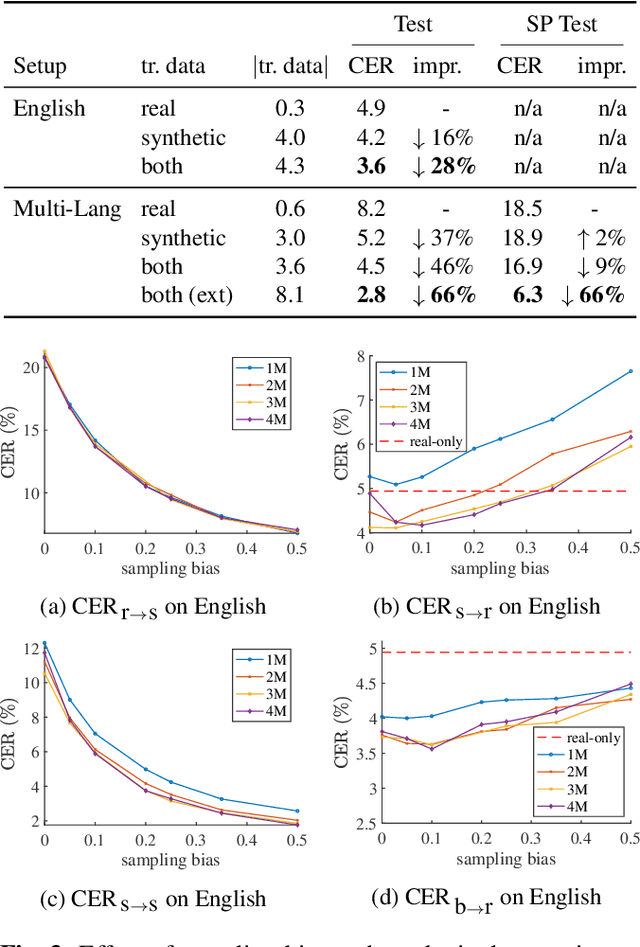
In this paper, we demonstrate how a generative model can be used to build a better recognizer through the control of content and style. We are building an online handwriting recognizer from a modest amount of training samples. By training our controllable handwriting synthesizer on the same data, we can synthesize handwriting with previously underrepresented content (e.g., URLs and email addresses) and style (e.g., cursive and slanted). Moreover, we propose a framework to analyze a recognizer that is trained with a mixture of real and synthetic training data. We use the framework to optimize data synthesis and demonstrate significant improvement on handwriting recognition over a model trained on real data only. Overall, we achieve a 66% reduction in Character Error Rate.
Embedded Large-Scale Handwritten Chinese Character Recognition
Apr 13, 2020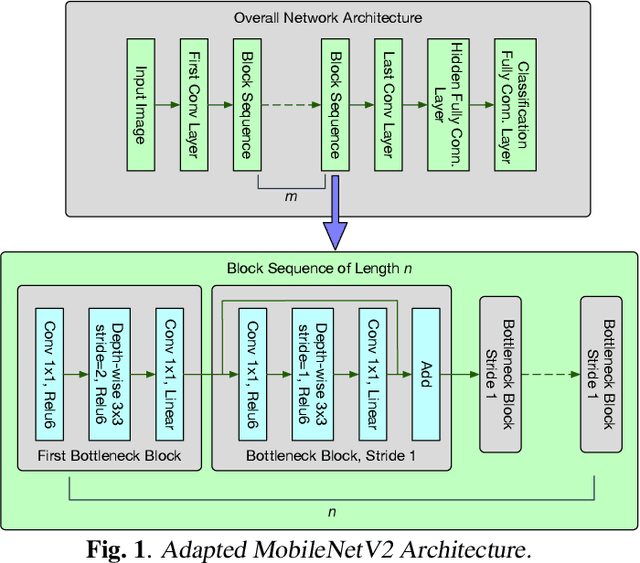


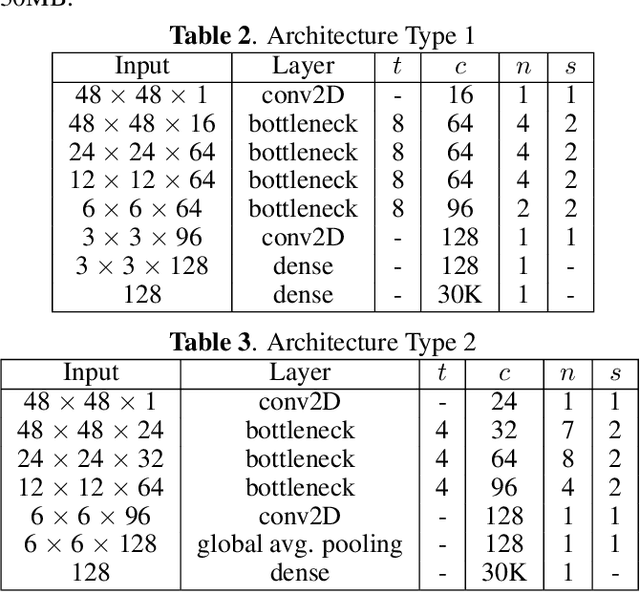
As handwriting input becomes more prevalent, the large symbol inventory required to support Chinese handwriting recognition poses unique challenges. This paper describes how the Apple deep learning recognition system can accurately handle up to 30,000 Chinese characters while running in real-time across a range of mobile devices. To achieve acceptable accuracy, we paid particular attention to data collection conditions, representativeness of writing styles, and training regimen. We found that, with proper care, even larger inventories are within reach. Our experiments show that accuracy only degrades slowly as the inventory increases, as long as we use training data of sufficient quality and in sufficient quantity.
Deep Self-Taught Learning for Handwritten Character Recognition
Sep 18, 2010



Recent theoretical and empirical work in statistical machine learning has demonstrated the importance of learning algorithms for deep architectures, i.e., function classes obtained by composing multiple non-linear transformations. Self-taught learning (exploiting unlabeled examples or examples from other distributions) has already been applied to deep learners, but mostly to show the advantage of unlabeled examples. Here we explore the advantage brought by {\em out-of-distribution examples}. For this purpose we developed a powerful generator of stochastic variations and noise processes for character images, including not only affine transformations but also slant, local elastic deformations, changes in thickness, background images, grey level changes, contrast, occlusion, and various types of noise. The out-of-distribution examples are obtained from these highly distorted images or by including examples of object classes different from those in the target test set. We show that {\em deep learners benefit more from out-of-distribution examples than a corresponding shallow learner}, at least in the area of handwritten character recognition. In fact, we show that they beat previously published results and reach human-level performance on both handwritten digit classification and 62-class handwritten character recognition.