 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicted Variables in Programming
Oct 01, 2018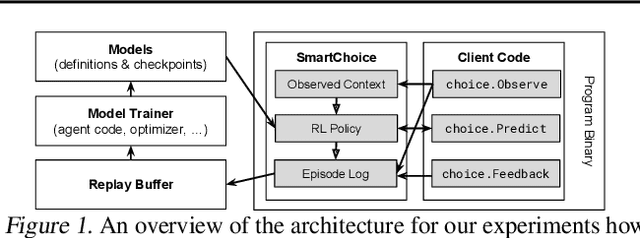
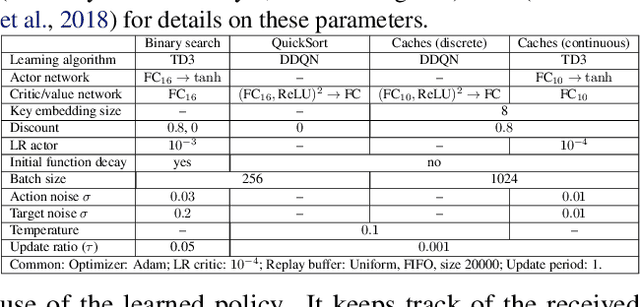
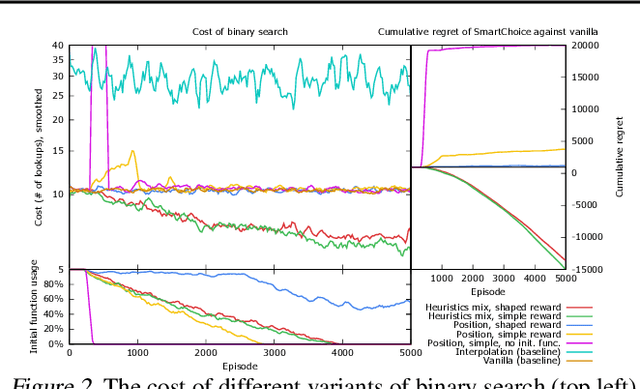
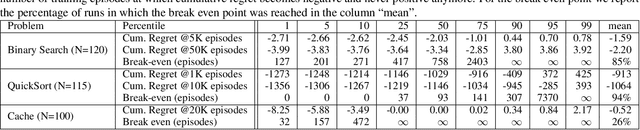
We present Predicted Variables (PVars), an approach to making machine learning (ML) a first class citizen in programming languages. There is a growing divide in approaches to building systems: using human experts (e.g. programming) on the one hand, and using behavior learned from data (e.g. ML) on the other hand. PVars aim to make ML in programming as easy as `if' statements and with that hybridize ML with programming. We leverage the existing concept of variables and create a new type, a predicted variable. PVars are akin to native variables with one important distinction: PVars determine their value using ML when evaluated. We describe PVars and their interface, how they can be used in programming, and demonstrate the feasibility of our approach on three algorithmic problems: binary search, Quicksort, and caches. We show experimentally that PVars are able to improve over the commonly used heuristics and lead to a better performance than the original algorithms. As opposed to previous work applying ML to algorithmic problems, PVars have the advantage that they can be used within the existing frameworks and do not require the existing domain knowledge to be replaced. PVars allow for a seamless integration of ML into existing systems and algorithms. Our PVars implementation currently relies on standard Reinforcement Learning (RL) methods. To learn faster, PVars use the heuristic function, which they are replacing, as an initial function. We show that PVars quickly pick up the behavior of the initial function and then improve performance beyond that without ever performing substantially worse -- allowing for a safe deployment in critical applications.
Deep Networks With Large Output Spaces
Apr 10, 2015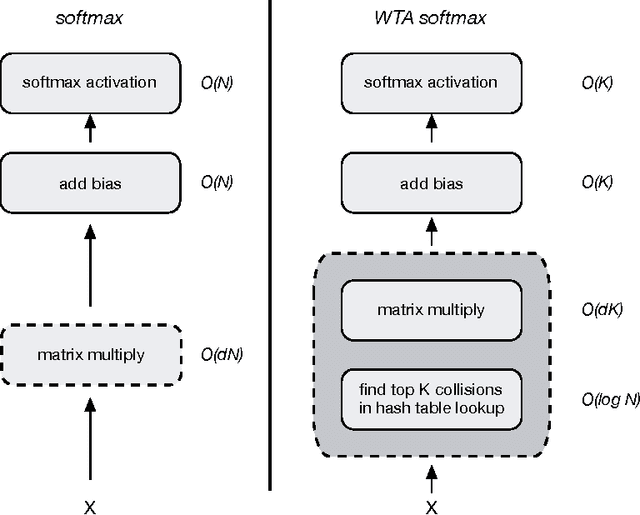
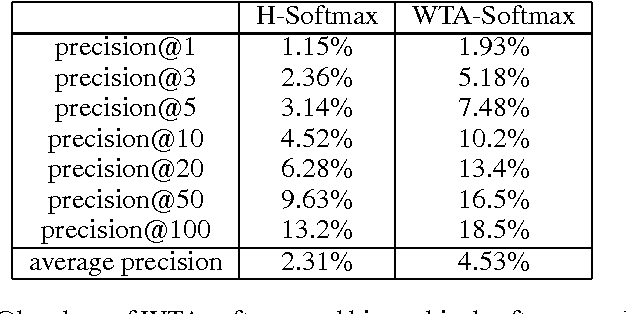
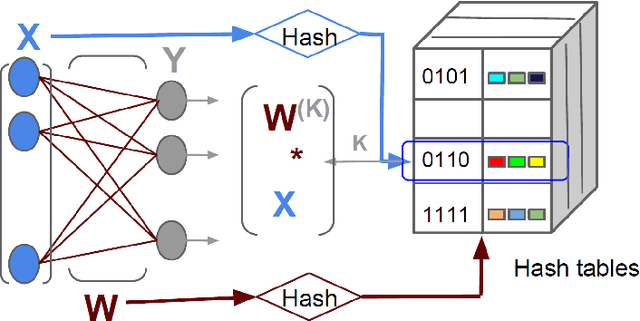
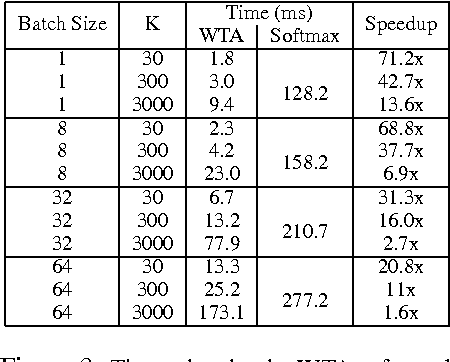
Deep neural networks have been extremely successful at various image, speech, video recognition tasks because of their ability to model deep structures within the data. However, they are still prohibitively expensive to train and apply for problems containing millions of classes in the output layer. Based on the observation that the key computation common to most neural network layers is a vector/matrix product, we propose a fast locality-sensitive hashing technique to approximate the actual dot product enabling us to scale up the training and inference to millions of output classes. We evaluate our technique on three diverse large-scale recognition tasks and show that our approach can train large-scale models at a faster rate (in terms of steps/total time) compared to baseline methods.