 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Joint Minimization of Regularization Loss Functions in Deep Variational Bayesian Methods for Attribute-Controlled Symbolic Music Generation
Nov 10, 2025Explicit latent variable models provide a flexible yet powerful framework for data synthesis, enabling controlled manipulation of generative factors. With latent variables drawn from a tractable probability density function that can be further constrained, these models enable continuous and semantically rich exploration of the output space by navigating their latent spaces. Structured latent representations are typically obtained through the joint minimization of regularization loss functions. In variational information bottleneck models, reconstruction loss and Kullback-Leibler Divergence (KLD) are often linearly combined with an auxiliary Attribute-Regularization (AR) loss. However, balancing KLD and AR turns out to be a very delicate matter. When KLD dominates over AR, generative models tend to lack controllability; when AR dominates over KLD, the stochastic encoder is encouraged to violate the standard normal prior. We explore this trade-off in the context of symbolic music generation with explicit control over continuous musical attributes. We show that existing approaches struggle to jointly minimize both regularization objectives, whereas suitable attribute transformations can help achieve both controllability and regularization of the target latent dimensions.
* IEEE Catalog No.: CFP2540S-ART ISBN: 978-9-46-459362-4
Conditional Diffusion as Latent Constraints for Controllable Symbolic Music Generation
Nov 10, 2025



Recent advances in latent diffusion models have demonstrated state-of-the-art performance in high-dimensional time-series data synthesis while providing flexible control through conditioning and guidance. However, existing methodologies primarily rely on musical context or natural language as the main modality of interacting with the generative process, which may not be ideal for expert users who seek precise fader-like control over specific musical attributes. In this work, we explore the application of denoising diffusion processes as plug-and-play latent constraints for unconditional symbolic music generation models. We focus on a framework that leverages a library of small conditional diffusion models operating as implicit probabilistic priors on the latents of a frozen unconditional backbone. While previous studies have explored domain-specific use cases, this work, to the best of our knowledge, is the first to demonstrate the versatility of such an approach across a diverse array of musical attributes, such as note density, pitch range, contour, and rhythm complexity. Our experiments show that diffusion-driven constraints outperform traditional attribute regularization and other latent constraints architectures, achieving significantly stronger correlations between target and generated attributes while maintaining high perceptual quality and diversity.
On the Extension of Differential Beamforming Theory to Arbitrary Planar Arrays of First-Order Elements
Aug 17, 2025Small-size acoustic arrays exploit spatial diversity to achieve capabilities beyond those of single-element devices, with applications ranging from teleconferencing to immersive multimedia. A key requirement for broadband array processing is a frequency-invariant spatial response, which ensures consistent directivity across wide bandwidths and prevents spectral coloration. Differential beamforming offers an inherently frequency-invariant solution by leveraging pressure differences between closely spaced elements of small-size arrays. Traditional approaches, however, assume the array elements to be omnidirectional, whereas real transducers exhibit frequency-dependent directivity that can degrade performance if not properly modeled. To address this limitation, we propose a generalized modal matching framework for frequency-invariant differential beamforming, applicable to unconstrained planar arrays of first-order directional elements. By representing the desired beampattern as a truncated circular harmonic expansion and fitting it to the actual element responses, our method accommodates arbitrary planar geometries and element orientations. This approach enables the synthesis of beampatterns of any order and steering direction without imposing rigid layout requirements. Simulations confirm that accounting for sensor directivity at the design stage yields accurate and robust performance across varying frequencies, geometries, and noise conditions.
A Zero-Shot Physics-Informed Dictionary Learning Approach for Sound Field Reconstruction
Dec 24, 2024


Sound field reconstruction aims to estimate pressure fields in areas lacking direct measurements. Existing techniques often rely on strong assumptions or face challenges related to data availability or the explicit modeling of physical properties. To bridge these gaps, this study introduces a zero-shot, physics-informed dictionary learning approach to perform sound field reconstruction. Our method relies only on a few sparse measurements to learn a dictionary, without the need for additional training data. Moreover, by enforcing the Helmholtz equation during the optimization process, the proposed approach ensures that the reconstructed sound field is represented as a linear combination of a few physically meaningful atoms. Evaluations on real-world data show that our approach achieves comparable performance to state-of-the-art dictionary learning techniques, with the advantage of requiring only a few observations of the sound field and no training on a dataset.
The IEEE-IS2 2024 Music Packet Loss Concealment Challenge
Sep 27, 2024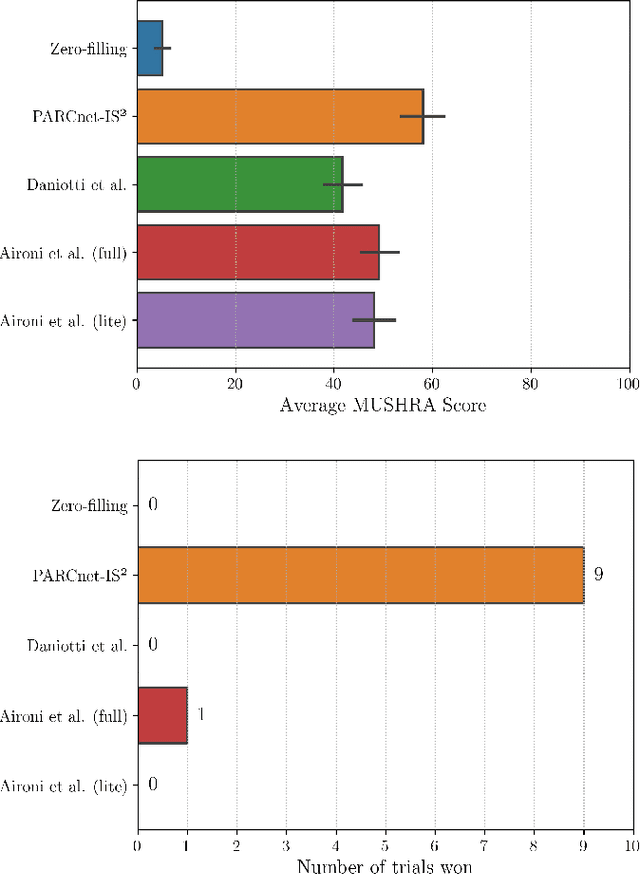
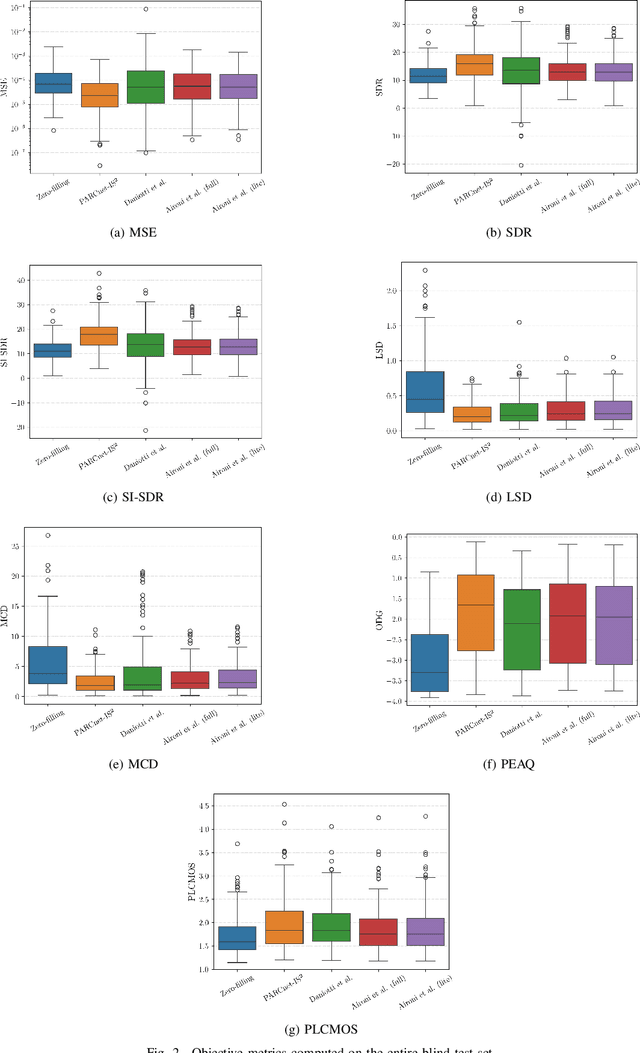
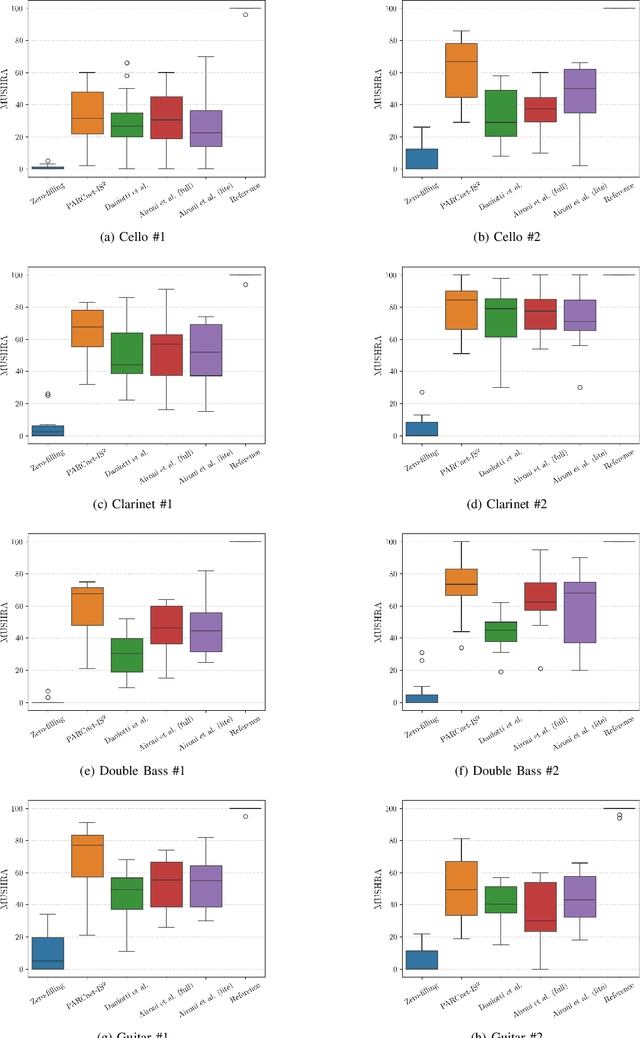
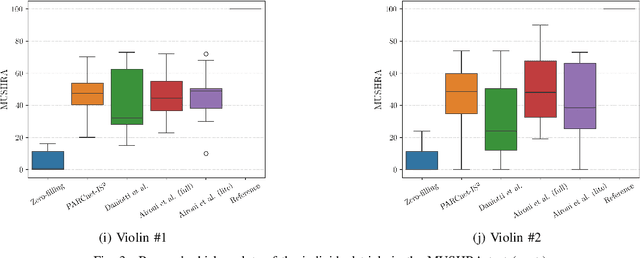
We present the IEEE-IS2 2024 Music Packet Loss Concealment Challenge. We begin by detailing the challenge rules, followed by an overview of the provided baseline system, the blind test set, and the evaluation methodology used to determine the final ranking. This inaugural edition aimed to foster collaboration between researchers and practitioners from the fields of signal processing, machine learning, and networked music performance, while also laying the groundwork for future advancements in packet loss concealment for music signals.
A Physics-Informed Neural Network-Based Approach for the Spatial Upsampling of Spherical Microphone Arrays
Jul 26, 2024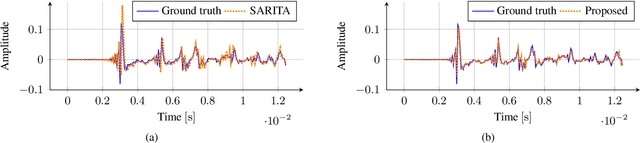
Spherical microphone arrays are convenient tools for capturing the spatial characteristics of a sound field. However, achieving superior spatial resolution requires arrays with numerous capsules, consequently leading to expensive devices. To address this issue, we present a method for spatially upsampling spherical microphone arrays with a limited number of capsules. Our approach exploits a physics-informed neural network with Rowdy activation functions, leveraging physical constraints to provide high-order microphone array signals, starting from low-order devices. Results show that, within its domain of application, our approach outperforms a state of the art method based on signal processing for spherical microphone arrays upsampling.
Data-Driven Room Acoustic Modeling Via Differentiable Feedback Delay Networks With Learnable Delay Lines
Mar 29, 2024Over the past few decades, extensive research has been devoted to the design of artificial reverberation algorithms aimed at emulating the room acoustics of physical environments. Despite significant advancements, automatic parameter tuning of delay-network models remains an open challenge. We introduce a novel method for finding the parameters of a Feedback Delay Network (FDN) such that its output renders the perceptual qualities of a measured room impulse response. The proposed approach involves the implementation of a differentiable FDN with trainable delay lines, which, for the first time, allows us to simultaneously learn each and every delay-network parameter via backpropagation. The iterative optimization process seeks to minimize a time-domain loss function incorporating differentiable terms accounting for energy decay and echo density. Through experimental validation, we show that the proposed method yields time-invariant frequency-independent FDNs capable of closely matching the desired acoustical characteristics, and outperforms existing methods based on genetic algorithms and analytical filter design.
HOMULA-RIR: A Room Impulse Response Dataset for Teleconferencing and Spatial Audio Applications Acquired Through Higher-Order Microphones and Uniform Linear Microphone Arrays
Feb 21, 2024
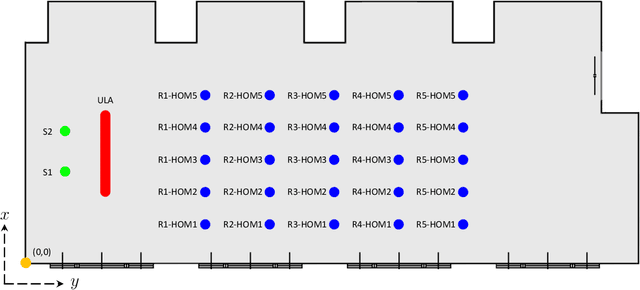
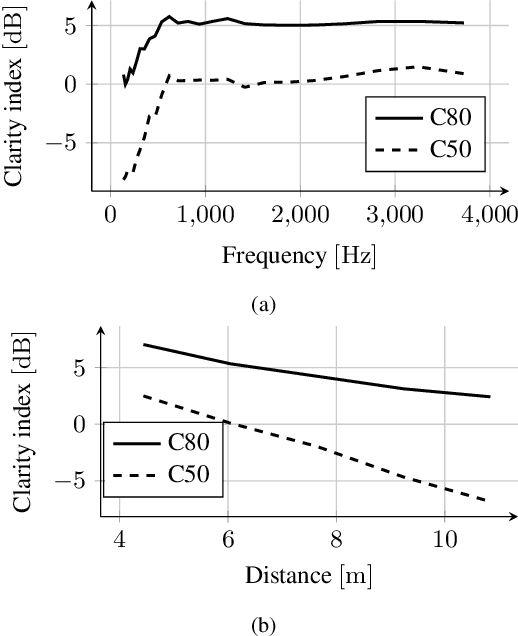
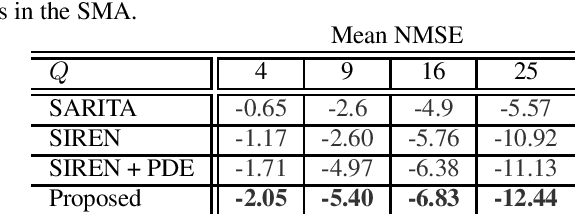
In this paper, we present HOMULA-RIR, a dataset of room impulse responses (RIRs) acquired using both higher-order microphones (HOMs) and a uniform linear array (ULA), in order to model a remote attendance teleconferencing scenario. Specifically, measurements were performed in a seminar room, where a 64-microphone ULA was used as a multichannel audio acquisition system in the proximity of the speakers, while HOMs were used to model 25 attendees actually present in the seminar room. The HOMs cover a wide area of the room, making the dataset suitable also for applications of virtual acoustics. Through the measurement of the reverberation time and clarity index, and sample applications such as source localization and separation, we demonstrate the effectiveness of the HOMULA-RIR dataset.
Toward Deep Drum Source Separation
Dec 15, 2023
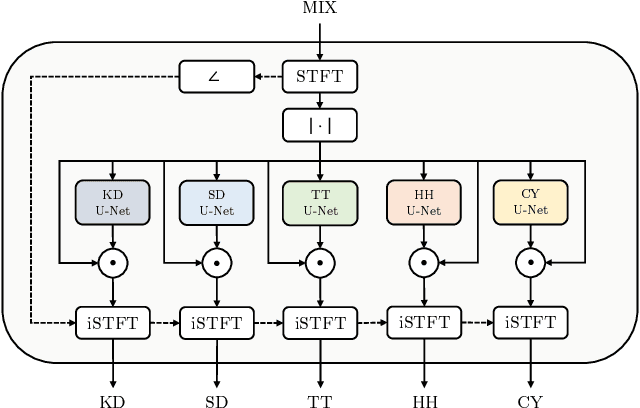
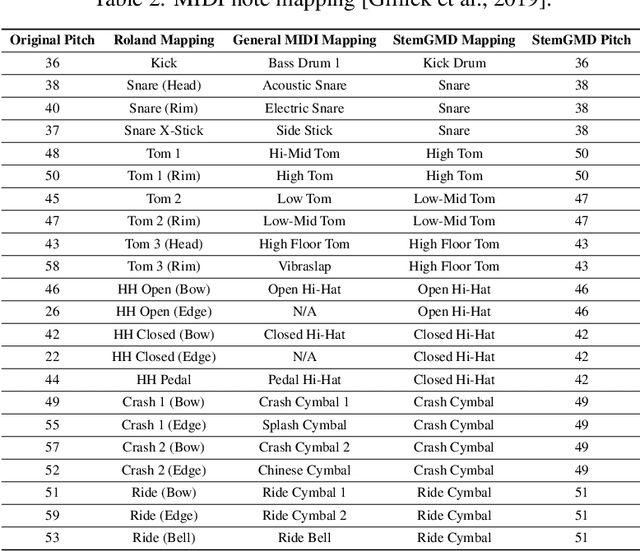
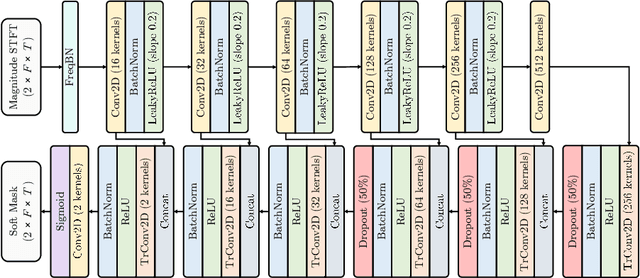
In the past, the field of drum source separation faced significant challenges due to limited data availability, hindering the adoption of cutting-edge deep learning methods that have found success in other related audio applications. In this manuscript, we introduce StemGMD, a large-scale audio dataset of isolated single-instrument drum stems. Each audio clip is synthesized from MIDI recordings of expressive drums performances using ten real-sounding acoustic drum kits. Totaling 1224 hours, StemGMD is the largest audio dataset of drums to date and the first to comprise isolated audio clips for every instrument in a canonical nine-piece drum kit. We leverage StemGMD to develop LarsNet, a novel deep drum source separation model. Through a bank of dedicated U-Nets, LarsNet can separate five stems from a stereo drum mixture faster than real-time and is shown to significantly outperform state-of-the-art nonnegative spectro-temporal factorization methods.
Reconstruction of Sound Field through Diffusion Models
Dec 14, 2023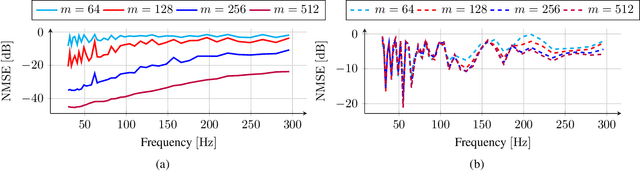

Reconstructing the sound field in a room is an important task for several applications, such as sound control and augmented (AR) or virtual reality (VR). In this paper, we propose a data-driven generative model for reconstructing the magnitude of acoustic fields in rooms with a focus on the modal frequency range. We introduce, for the first time, the use of a conditional Denoising Diffusion Probabilistic Model (DDPM) trained in order to reconstruct the sound field (SF-Diff) over an extended domain. The architecture is devised in order to be conditioned on a set of limited available measurements at different frequencies and generate the sound field in target, unknown, locations. The results show that SF-Diff is able to provide accurate reconstructions, outperforming a state-of-the-art baseline based on kernel interpolation.