 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Acoustic Radiance Transfer
Sep 19, 2025Geometric acoustics is an efficient approach to room acoustics modeling, governed by the canonical time-dependent rendering equation. Acoustic radiance transfer (ART) solves the equation through discretization, modeling the time- and direction-dependent energy exchange between surface patches given with flexible material properties. We introduce DART, a differentiable and efficient implementation of ART that enables gradient-based optimization of material properties. We evaluate DART on a simpler variant of the acoustic field learning task, which aims to predict the energy responses of novel source-receiver settings. Experimental results show that DART exhibits favorable properties, e.g., better generalization under a sparse measurement scenario, compared to existing signal processing and neural network baselines, while remaining a simple, fully interpretable system.
Past, Present, and Future of Spatial Audio and Room Acoustics
Mar 17, 2025The study of spatial audio and room acoustics aims to create immersive audio experiences by modeling the physics and psychoacoustics of how sound behaves in space. In the long history of this research area, various key technologies have been developed based both on theoretical advancements and practical innovations. We highlight historical achievements, initiative activities, recent advancements, and future outlooks in the research area of spatial audio recording and reproduction, and room acoustic simulation, modeling, analysis, and control.
MoD-ART: Modal Decomposition of Acoustic Radiance Transfer
Dec 05, 2024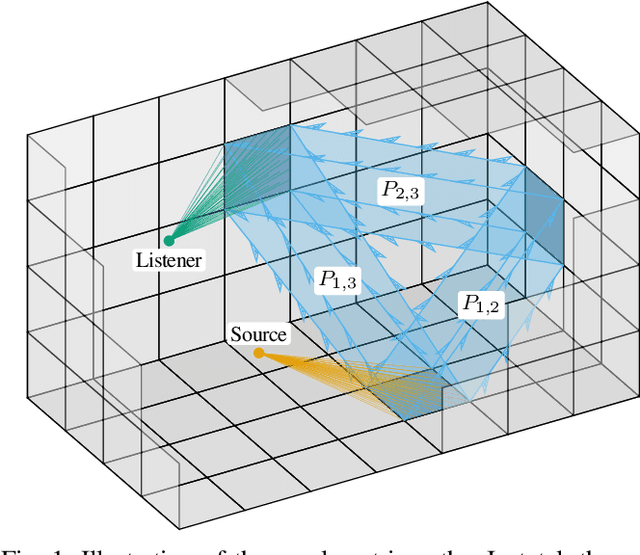
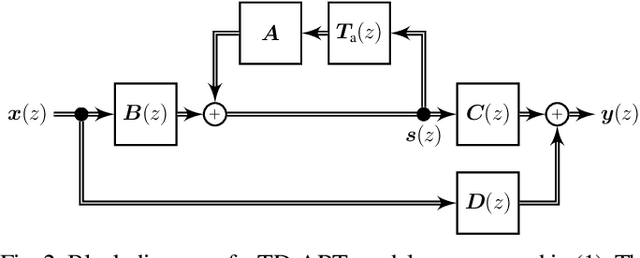
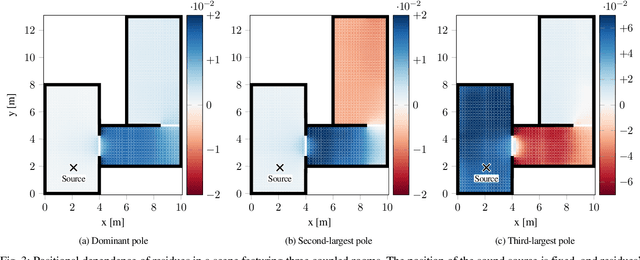
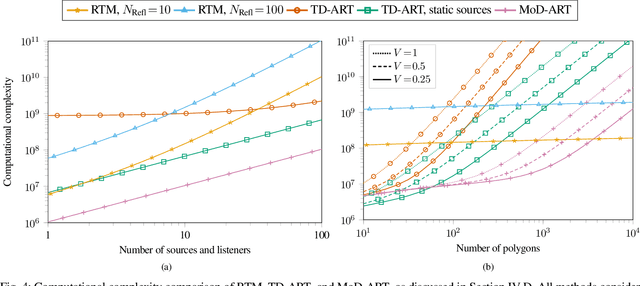
Modeling late reverberation at interactive speeds is a challenging task when multiple sound sources and listeners are present in the same environment. This is especially problematic when the environment is geometrically complex and/or features uneven energy absorption (e.g. coupled volumes), because in such cases the late reverberation is dependent on the sound sources' and listeners' positions, and therefore must be adapted to their movements in real time. We present a novel approach to the task, named modal decomposition of Acoustic Radiance Transfer (MoD-ART), which can handle highly complex scenarios with efficiency. The approach is based on the geometrical acoustics method of Acoustic Radiance Transfer, from which we extract a set of energy decay modes and their positional relationships with sources and listeners. In this paper, we describe the physical and mathematical meaningfulness of MoD-ART, highlighting its advantages and applicability to different scenarios. Through an analysis of the method's computational complexity, we show that it compares very favourably with ray-tracing. We also present simulation results showing that MoD-ART can capture multiple decay slopes and flutter echoes.
Data-Driven Room Acoustic Modeling Via Differentiable Feedback Delay Networks With Learnable Delay Lines
Mar 29, 2024Over the past few decades, extensive research has been devoted to the design of artificial reverberation algorithms aimed at emulating the room acoustics of physical environments. Despite significant advancements, automatic parameter tuning of delay-network models remains an open challenge. We introduce a novel method for finding the parameters of a Feedback Delay Network (FDN) such that its output renders the perceptual qualities of a measured room impulse response. The proposed approach involves the implementation of a differentiable FDN with trainable delay lines, which, for the first time, allows us to simultaneously learn each and every delay-network parameter via backpropagation. The iterative optimization process seeks to minimize a time-domain loss function incorporating differentiable terms accounting for energy decay and echo density. Through experimental validation, we show that the proposed method yields time-invariant frequency-independent FDNs capable of closely matching the desired acoustical characteristics, and outperforms existing methods based on genetic algorithms and analytical filter design.
Room Acoustic Rendering Networks with Control of Scattering and Early Reflections
Dec 22, 2023Room acoustic synthesis can be used in Virtual Reality (VR), Augmented Reality (AR) and gaming applications to enhance listeners' sense of immersion, realism and externalisation. A common approach is to use Geometrical Acoustics (GA) models to compute impulse responses at interactive speed, and fast convolution methods to apply said responses in real time. Alternatively, delay-network-based models are capable of modeling certain aspects of room acoustics, but with a significantly lower computational cost. In order to bridge the gap between these classes of models, recent work introduced delay network designs that approximate Acoustic Radiance Transfer (ART), a GA model that simulates the transfer of acoustic energy between discrete surface patches in an environment. This paper presents two key extensions of such designs. The first extension involves a new physically-based and stability-preserving design of the feedback matrices, enabling more accurate control of scattering and, more in general, of late reverberation properties. The second extension allows an arbitrary number of early reflections to be modeled with high accuracy, meaning the network can be scaled at will between computational cost and early reverb precision. The proposed extensions are compared to the baseline ART-approximating delay network as well as two reference GA models. The evaluation is based on objective measures of perceptually-relevant features, including frequency-dependent reverberation times, echo density build-up, and early decay time. Results show how the proposed extensions result in a significant improvement over the baseline model, especially for the case of non-convex geometries or the case of unevenly distributed wall absorption, both scenarios of broad practical interest.
Low-Complexity Steered Response Power Mapping based on Low-Rank and Sparse Interpolation
Jun 14, 2023For acoustic source localization, a map of the acoustic scene as obtained by the steered response power (SRP) approach can be employed. In SRP, the frequency-weighted output power of a beamformer steered towards a set of candidate locations is obtained from generalized cross-correlations (GCCs). Due to the dense grid of candidate locations, conventional SRP exhibits a high computational complexity. While a number of low-complexity SRP-based localization approaches using non-exhaustive spatial search have been proposed, few studies aim to construct a full SRP map at reduced computational cost. In this paper, we propose two scalable approaches to this problem. Expressing the SRP map as a matrix transform of frequency-domain GCCs, we decompose the SRP matrix into a sampling matrix and an interpolation matrix. While the sampling operation can be implemented efficiently by the inverse fast Fourier transform (iFFT), we propose to use optimal low-rank or sparse approximations of the interpolation matrix for further complexity reduction. The proposed approaches, refered to as sampling + low-rank interpolation-based SRP (SLRI-SRP) and sampling + sparse interpolation-based SRP (SSPI-SRP), are evaluated in a near-field (NF) and a far-field (FF) localization scenario and compared to a state-of-the-art low-rank-based SRP approach (LR-SRP). The results indicate that SSPI-SRP outperforms both SLRI-SRP and LR-SRP over a wide complexity range in terms of approximation error and localization accuracy, achieving a complexity reduction of two to three orders of magnitude as compared to conventional SRP. A MATLAB implementation is available online.