 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeanimal2vec and MeerKAT: A self-supervised transformer for rare-event raw audio input and a large-scale reference dataset for bioacoustics
Jun 03, 2024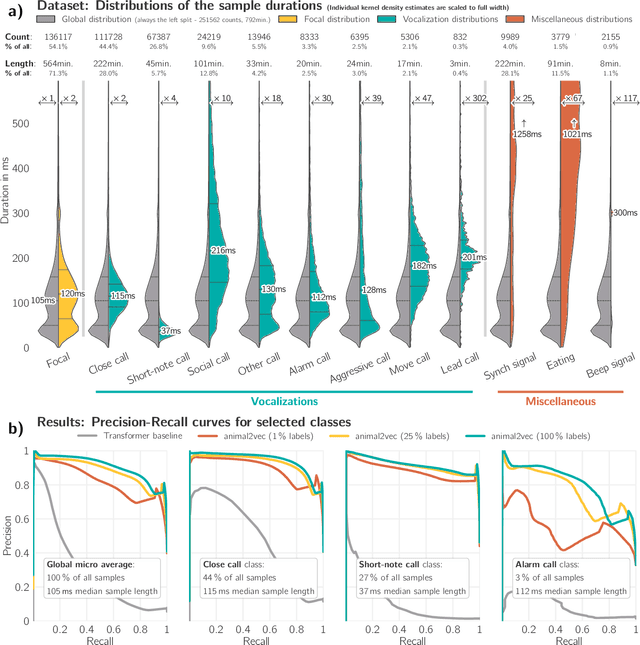

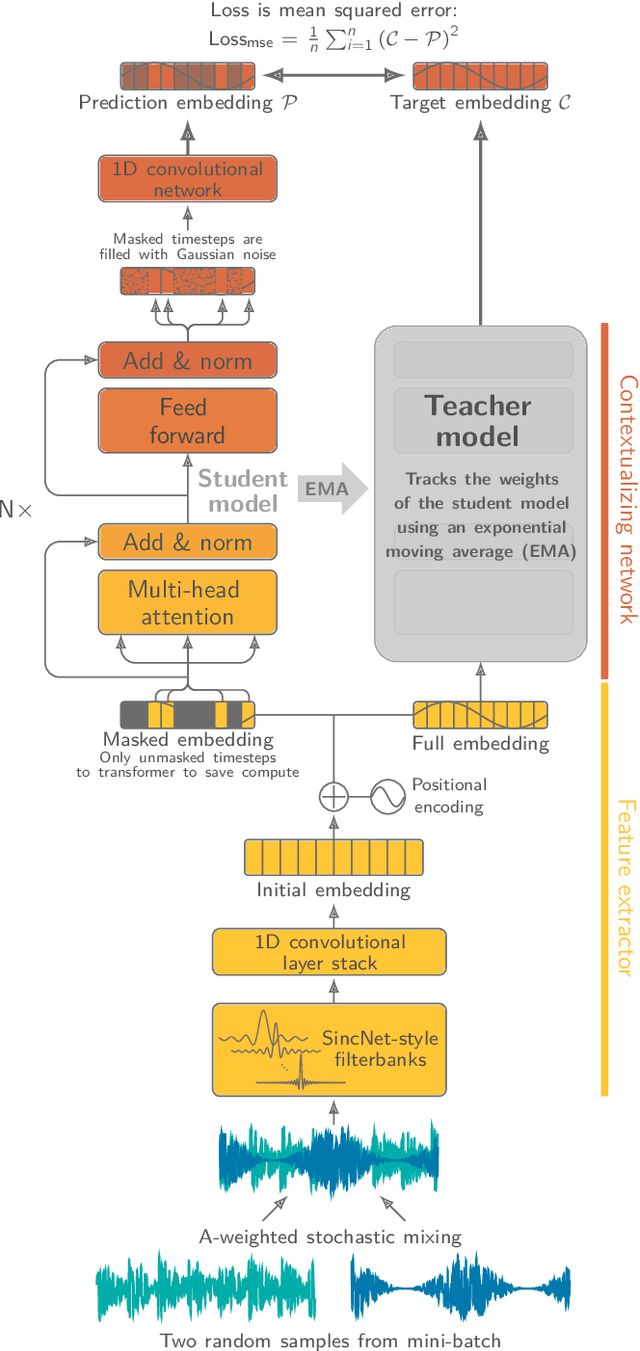
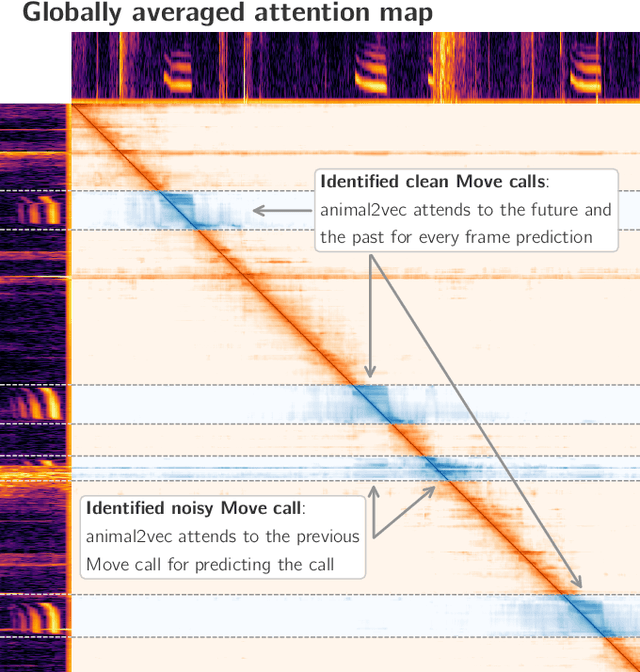
Bioacoustic research provides invaluable insights into the behavior, ecology, and conservation of animals. Most bioacoustic datasets consist of long recordings where events of interest, such as vocalizations, are exceedingly rare. Analyzing these datasets poses a monumental challenge to researchers, where deep learning techniques have emerged as a standard method. Their adaptation remains challenging, focusing on models conceived for computer vision, where the audio waveforms are engineered into spectrographic representations for training and inference. We improve the current state of deep learning in bioacoustics in two ways: First, we present the animal2vec framework: a fully interpretable transformer model and self-supervised training scheme tailored for sparse and unbalanced bioacoustic data. Second, we openly publish MeerKAT: Meerkat Kalahari Audio Transcripts, a large-scale dataset containing audio collected via biologgers deployed on free-ranging meerkats with a length of over 1068h, of which 184h have twelve time-resolved vocalization-type classes, each with ms-resolution, making it the largest publicly-available labeled dataset on terrestrial mammals. Further, we benchmark animal2vec against the NIPS4Bplus birdsong dataset. We report new state-of-the-art results on both datasets and evaluate the few-shot capabilities of animal2vec of labeled training data. Finally, we perform ablation studies to highlight the differences between our architecture and a vanilla transformer baseline for human-produced sounds. animal2vec allows researchers to classify massive amounts of sparse bioacoustic data even with little ground truth information available. In addition, the MeerKAT dataset is the first large-scale, millisecond-resolution corpus for benchmarking bioacoustic models in the pretrain/finetune paradigm. We believe this sets the stage for a new reference point for bioacoustics.
Machine learning in acoustics: a review
May 11, 2019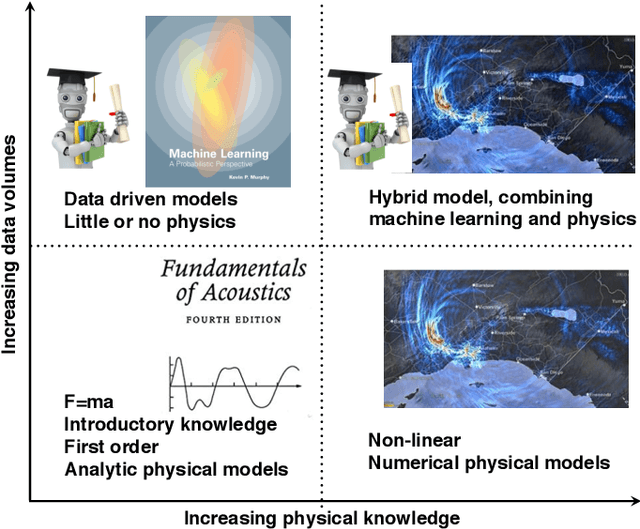
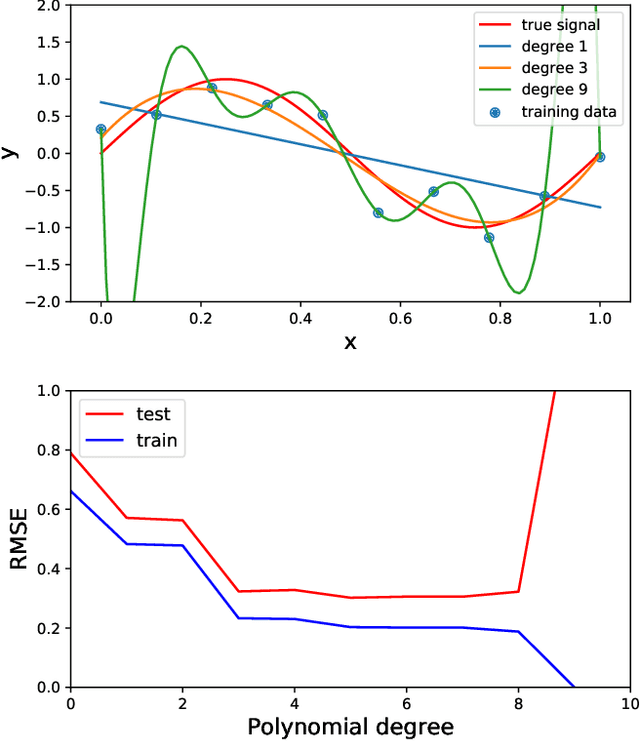
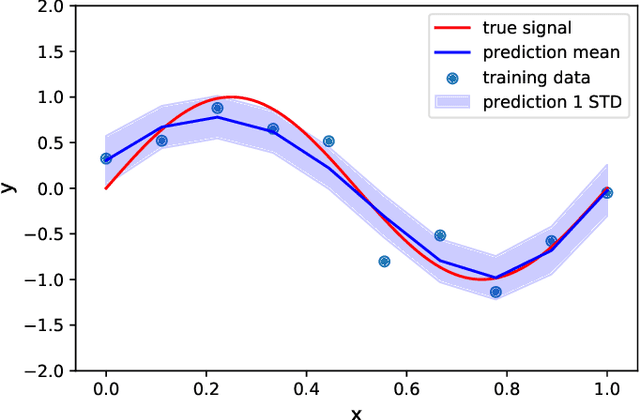
Acoustic data provide scientific and engineering insights in fields ranging from biology and communications to ocean and Earth science. We survey the recent advances and transformative potential of machine learning (ML), including deep learning, in the field of acoustics. ML is a broad family of statistical techniques for automatically detecting and utilizing patterns in data. Relative to conventional acoustics and signal processing, ML is data-driven. Given sufficient training data, ML can discover complex relationships between features. With large volumes of training data, ML can discover models describing complex acoustic phenomena such as human speech and reverberation. ML in acoustics is rapidly developing with compelling results and significant future promise. We first introduce ML, then highlight ML developments in five acoustics research areas: source localization in speech processing, source localization in ocean acoustics, bioacoustics, seismic exploration, and environmental sounds in everyday scenes.