 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention is All You Need in Speech Separation
Paper and Code
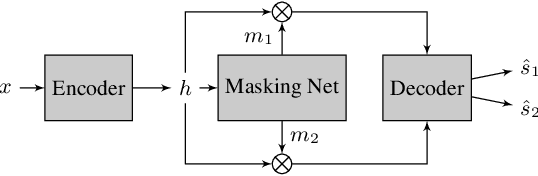
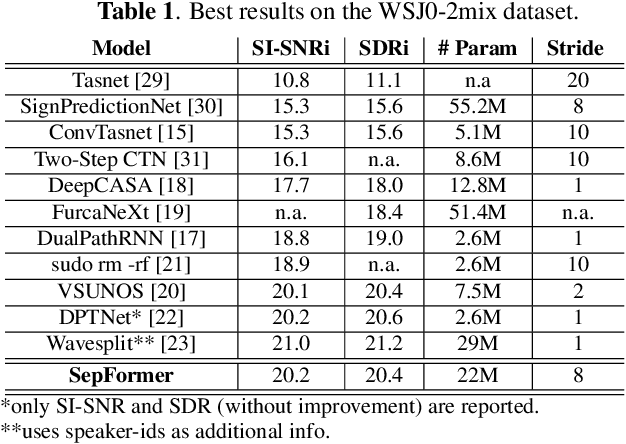
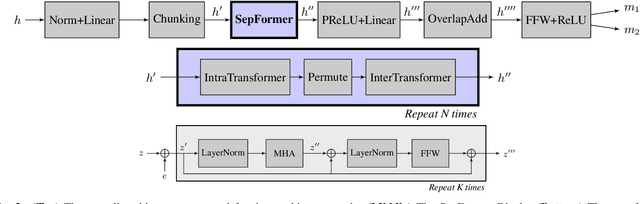
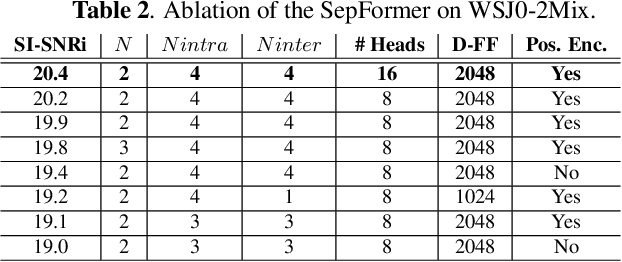
Recurrent Neural Networks (RNNs) have long been the dominant architecture in sequence-to-sequence learning. RNNs, however, are inherently sequential models that do not allow parallelization of their computations. Transformers are emerging as a natural alternative to standard RNNs, replacing recurrent computations with a multi-head attention mechanism. In this paper, we propose the `SepFormer', a novel RNN-free Transformer-based neural network for speech separation. The SepFormer learns short and long-term dependencies with a multi-scale approach that employs transformers. The proposed model matches or overtakes the state-of-the-art (SOTA) performance on the standard WSJ0-2/3mix datasets. It indeed achieves an SI-SNRi of 20.2 dB on WSJ0-2mix matching the SOTA, and an SI-SNRi of 17.6 dB on WSJ0-3mix, a SOTA result. The SepFormer inherits the parallelization advantages of Transformers and achieves a competitive performance even when downsampling the encoded representation by a factor of 8. It is thus significantly faster and it is less memory-demanding than the latest RNN-based systems.