 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building efficient Routed systems for Retrieval
Jan 10, 2026Late-interaction retrieval models like ColBERT achieve superior accuracy by enabling token-level interactions, but their computational cost hinders scalability and integration with Approximate Nearest Neighbor Search (ANNS). We introduce FastLane, a novel retrieval framework that dynamically routes queries to their most informative representations, eliminating redundant token comparisons. FastLane employs a learnable routing mechanism optimized alongside the embedding model, leveraging self-attention and differentiable selection to maximize efficiency. Our approach reduces computational complexity by up to 30x while maintaining competitive retrieval performance. By bridging late-interaction models with ANNS, FastLane enables scalable, low-latency retrieval, making it feasible for large-scale applications such as search engines, recommendation systems, and question-answering platforms. This work opens pathways for multi-lingual, multi-modal, and long-context retrieval, pushing the frontier of efficient and adaptive information retrieval.
FlexAct: Why Learn when you can Pick?
Jan 10, 2026Learning activation functions has emerged as a promising direction in deep learning, allowing networks to adapt activation mechanisms to task-specific demands. In this work, we introduce a novel framework that employs the Gumbel-Softmax trick to enable discrete yet differentiable selection among a predefined set of activation functions during training. Our method dynamically learns the optimal activation function independently of the input, thereby enhancing both predictive accuracy and architectural flexibility. Experiments on synthetic datasets show that our model consistently selects the most suitable activation function, underscoring its effectiveness. These results connect theoretical advances with practical utility, paving the way for more adaptive and modular neural architectures in complex learning scenarios.
On the Limits of Multi-modal Meta-Learning with Auxiliary Task Modulation Using Conditional Batch Normalization
May 29, 2024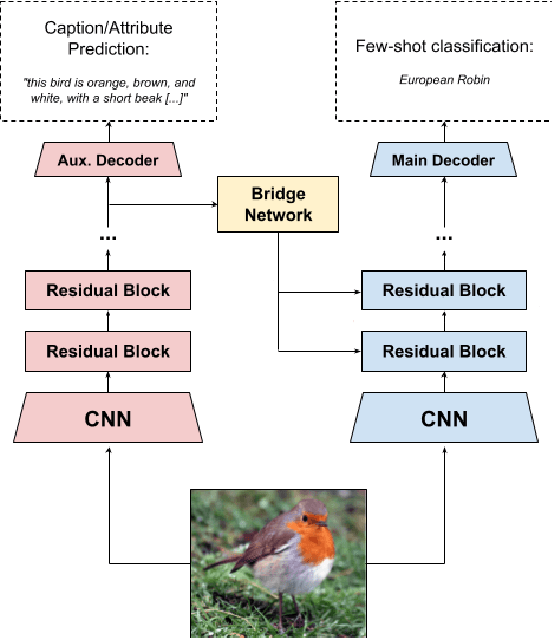


Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that cross-modal learning can improve representations for few-shot classification. More specifically, language is a rich modality that can be used to guide visual learning. In this work, we experiment with a multi-modal architecture for few-shot learning that consists of three components: a classifier, an auxiliary network, and a bridge network. While the classifier performs the main classification task, the auxiliary network learns to predict language representations from the same input, and the bridge network transforms high-level features of the auxiliary network into modulation parameters for layers of the few-shot classifier using conditional batch normalization. The bridge should encourage a form of lightweight semantic alignment between language and vision which could be useful for the classifier. However, after evaluating the proposed approach on two popular few-shot classification benchmarks we find that a) the improvements do not reproduce across benchmarks, and b) when they do, the improvements are due to the additional compute and parameters introduced by the bridge network. We contribute insights and recommendations for future work in multi-modal meta-learning, especially when using language representations.
EHI: End-to-end Learning of Hierarchical Index for Efficient Dense Retrieval
Oct 13, 2023Dense embedding-based retrieval is now the industry standard for semantic search and ranking problems, like obtaining relevant web documents for a given query. Such techniques use a two-stage process: (a) contrastive learning to train a dual encoder to embed both the query and documents and (b) approximate nearest neighbor search (ANNS) for finding similar documents for a given query. These two stages are disjoint; the learned embeddings might be ill-suited for the ANNS method and vice-versa, leading to suboptimal performance. In this work, we propose End-to-end Hierarchical Indexing -- EHI -- that jointly learns both the embeddings and the ANNS structure to optimize retrieval performance. EHI uses a standard dual encoder model for embedding queries and documents while learning an inverted file index (IVF) style tree structure for efficient ANNS. To ensure stable and efficient learning of discrete tree-based ANNS structure, EHI introduces the notion of dense path embedding that captures the position of a query/document in the tree. We demonstrate the effectiveness of EHI on several benchmarks, including de-facto industry standard MS MARCO (Dev set and TREC DL19) datasets. For example, with the same compute budget, EHI outperforms state-of-the-art (SOTA) in by 0.6% (MRR@10) on MS MARCO dev set and by 4.2% (nDCG@10) on TREC DL19 benchmarks.
Stochastic Re-weighted Gradient Descent via Distributionally Robust Optimization
Jun 15, 2023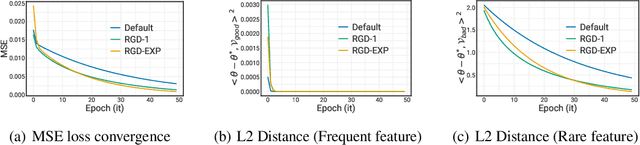


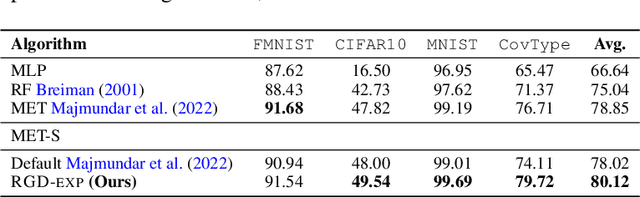
We develop a re-weighted gradient descent technique for boosting the performance of deep neural networks. Our algorithm involves the importance weighting of data points during each optimization step. Our approach is inspired by distributionally robust optimization with $f$-divergences, which has been known to result in models with improved generalization guarantees. Our re-weighting scheme is simple, computationally efficient, and can be combined with any popular optimization algorithms such as SGD and Adam. Empirically, we demonstrate our approach's superiority on various tasks, including vanilla classification, classification with label imbalance, noisy labels, domain adaptation, and tabular representation learning. Notably, we obtain improvements of +0.7% and +1.44% over SOTA on DomainBed and Tabular benchmarks, respectively. Moreover, our algorithm boosts the performance of BERT on GLUE benchmarks by +1.94%, and ViT on ImageNet-1K by +0.9%. These results demonstrate the effectiveness of the proposed approach, indicating its potential for improving performance in diverse domains.
Look Back When Surprised: Stabilizing Reverse Experience Replay for Neural Approximation
Jun 07, 2022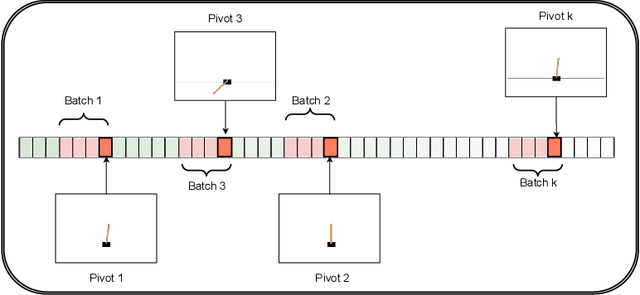

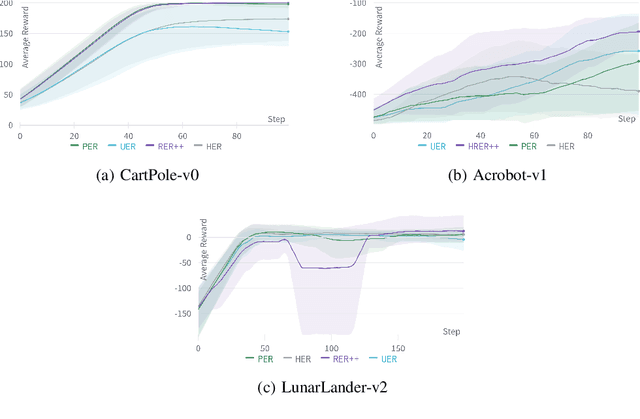

Experience replay methods, which are an essential part of reinforcement learning(RL) algorithms, are designed to mitigate spurious correlations and biases while learning from temporally dependent data. Roughly speaking, these methods allow us to draw batched data from a large buffer such that these temporal correlations do not hinder the performance of descent algorithms. In this experimental work, we consider the recently developed and theoretically rigorous reverse experience replay (RER), which has been shown to remove such spurious biases in simplified theoretical settings. We combine RER with optimistic experience replay (OER) to obtain RER++, which is stable under neural function approximation. We show via experiments that this has a better performance than techniques like prioritized experience replay (PER) on various tasks, with a significantly smaller computational complexity. It is well known in the RL literature that choosing examples greedily with the largest TD error (as in OER) or forming mini-batches with consecutive data points (as in RER) leads to poor performance. However, our method, which combines these techniques, works very well.
Rethinking Learning Dynamics in RL using Adversarial Networks
Jan 27, 2022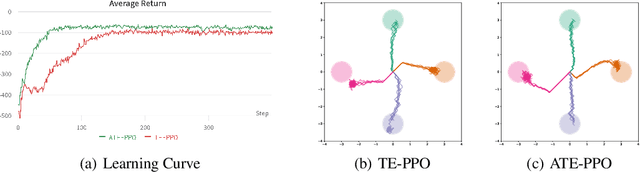

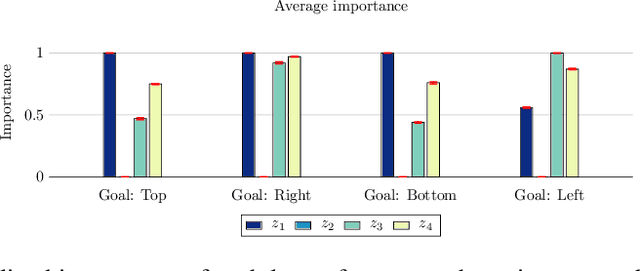

We present a learning mechanism for reinforcement learning of closely related skills parameterized via a skill embedding space. Our approach is grounded on the intuition that nothing makes you learn better than a coevolving adversary. The main contribution of our work is to formulate an adversarial training regime for reinforcement learning with the help of entropy-regularized policy gradient formulation. We also adapt existing measures of causal attribution to draw insights from the skills learned. Our experiments demonstrate that the adversarial process leads to a better exploration of multiple solutions and understanding the minimum number of different skills necessary to solve a given set of tasks.
The Effect of Diversity in Meta-Learning
Jan 27, 2022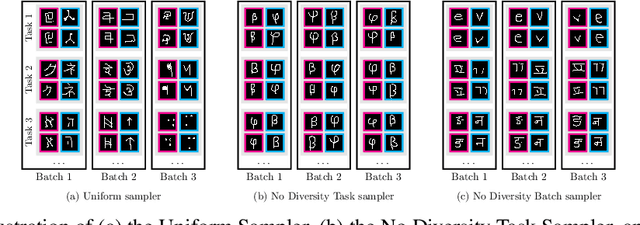
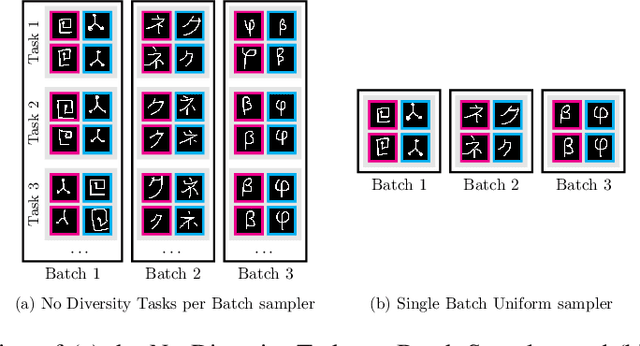
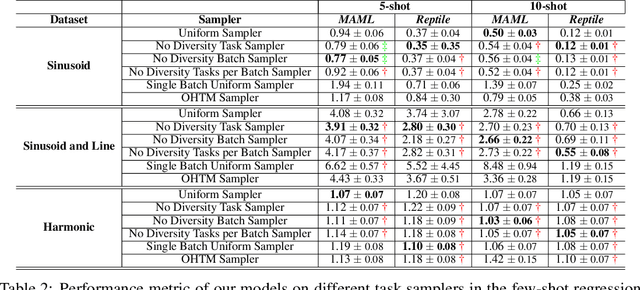
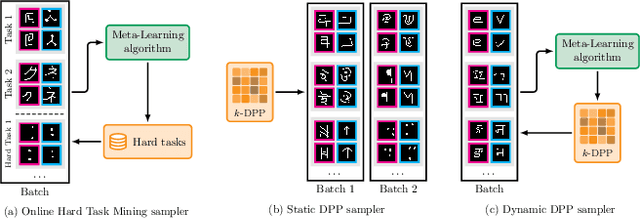
Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that task distribution plays a vital role in the model's performance. Conventional wisdom is that task diversity should improve the performance of meta-learning. In this work, we find evidence to the contrary; we study different task distributions on a myriad of models and datasets to evaluate the effect of task diversity on meta-learning algorithms. For this experiment, we train on multiple datasets, and with three broad classes of meta-learning models - Metric-based (i.e., Protonet, Matching Networks), Optimization-based (i.e., MAML, Reptile, and MetaOptNet), and Bayesian meta-learning models (i.e., CNAPs). Our experiments demonstrate that the effect of task diversity on all these algorithms follows a similar trend, and task diversity does not seem to offer any benefits to the learning of the model. Furthermore, we also demonstrate that even a handful of tasks, repeated over multiple batches, would be sufficient to achieve a performance similar to uniform sampling and draws into question the need for additional tasks to create better models.