 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Back When Surprised: Stabilizing Reverse Experience Replay for Neural Approximation
Paper and Code
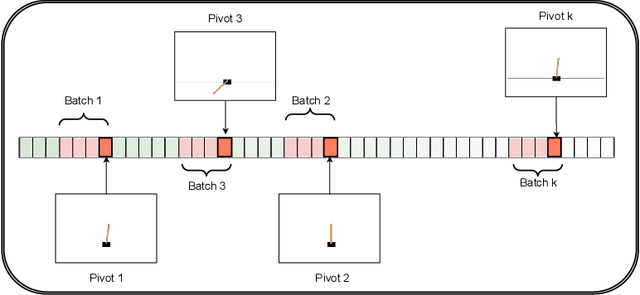

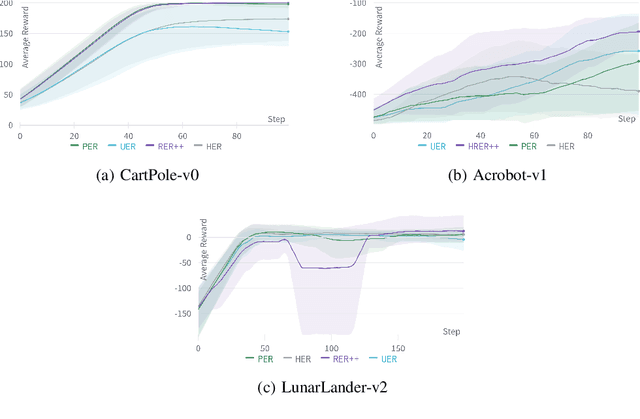

Experience replay methods, which are an essential part of reinforcement learning(RL) algorithms, are designed to mitigate spurious correlations and biases while learning from temporally dependent data. Roughly speaking, these methods allow us to draw batched data from a large buffer such that these temporal correlations do not hinder the performance of descent algorithms. In this experimental work, we consider the recently developed and theoretically rigorous reverse experience replay (RER), which has been shown to remove such spurious biases in simplified theoretical settings. We combine RER with optimistic experience replay (OER) to obtain RER++, which is stable under neural function approximation. We show via experiments that this has a better performance than techniques like prioritized experience replay (PER) on various tasks, with a significantly smaller computational complexity. It is well known in the RL literature that choosing examples greedily with the largest TD error (as in OER) or forming mini-batches with consecutive data points (as in RER) leads to poor performance. However, our method, which combines these techniques, works very well.