 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Re-weighted Gradient Descent via Distributionally Robust Optimization
Paper and Code
Jun 15, 2023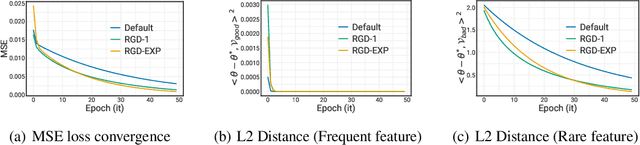


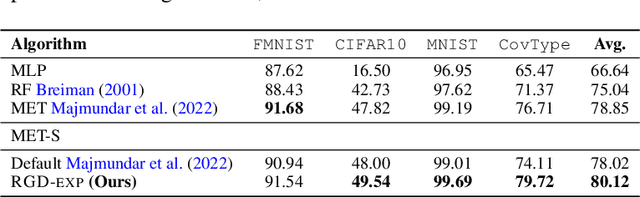
We develop a re-weighted gradient descent technique for boosting the performance of deep neural networks. Our algorithm involves the importance weighting of data points during each optimization step. Our approach is inspired by distributionally robust optimization with $f$-divergences, which has been known to result in models with improved generalization guarantees. Our re-weighting scheme is simple, computationally efficient, and can be combined with any popular optimization algorithms such as SGD and Adam. Empirically, we demonstrate our approach's superiority on various tasks, including vanilla classification, classification with label imbalance, noisy labels, domain adaptation, and tabular representation learning. Notably, we obtain improvements of +0.7% and +1.44% over SOTA on DomainBed and Tabular benchmarks, respectively. Moreover, our algorithm boosts the performance of BERT on GLUE benchmarks by +1.94%, and ViT on ImageNet-1K by +0.9%. These results demonstrate the effectiveness of the proposed approach, indicating its potential for improving performance in diverse domains.