 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Video Prediction from a Single Frame for Video Anomaly Detection
Aug 15, 2023


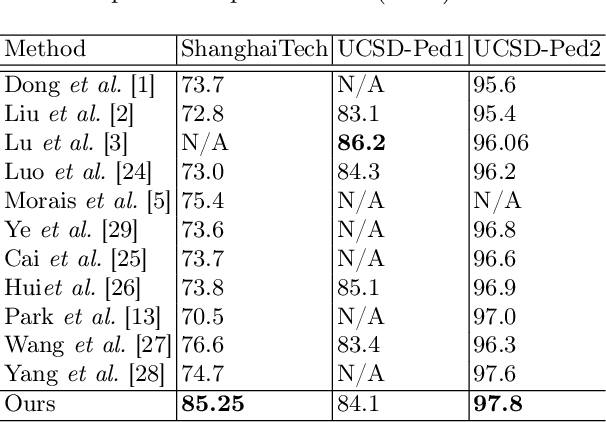
Video anomaly detection (VAD) is an important but challenging task in computer vision. The main challenge rises due to the rarity of training samples to model all anomaly cases. Hence, semi-supervised anomaly detection methods have gotten more attention, since they focus on modeling normals and they detect anomalies by measuring the deviations from normal patterns. Despite impressive advances of these methods in modeling normal motion and appearance, long-term motion modeling has not been effectively explored so far. Inspired by the abilities of the future frame prediction proxy-task, we introduce the task of future video prediction from a single frame, as a novel proxy-task for video anomaly detection. This proxy-task alleviates the challenges of previous methods in learning longer motion patterns. Moreover, we replace the initial and future raw frames with their corresponding semantic segmentation map, which not only makes the method aware of object class but also makes the prediction task less complex for the model. Extensive experiments on the benchmark datasets (ShanghaiTech, UCSD-Ped1, and UCSD-Ped2) show the effectiveness of the method and the superiority of its performance compared to SOTA prediction-based VAD methods.
$β$-Multivariational Autoencoder for Entangled Representation Learning in Video Frames
Nov 22, 2022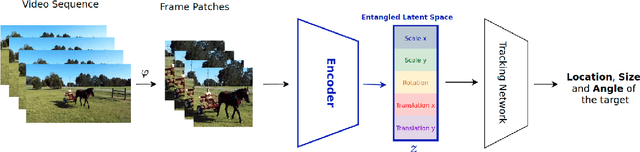
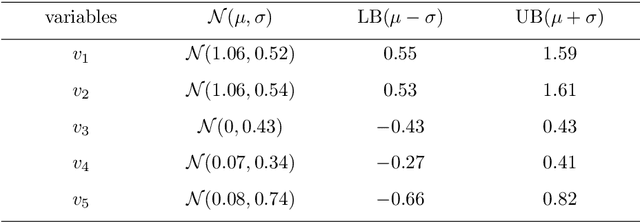
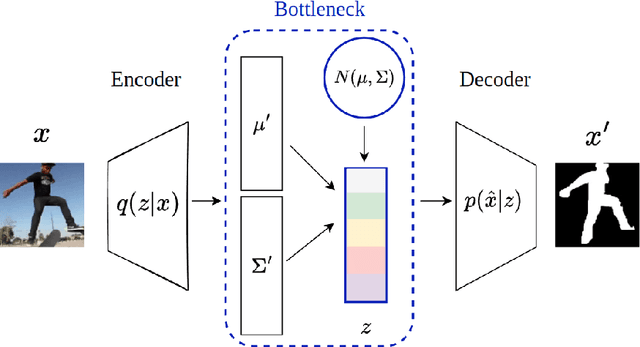
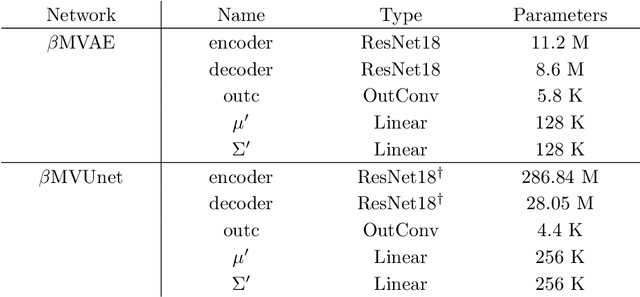
It is crucial to choose actions from an appropriate distribution while learning a sequential decision-making process in which a set of actions is expected given the states and previous reward. Yet, if there are more than two latent variables and every two variables have a covariance value, learning a known prior from data becomes challenging. Because when the data are big and diverse, many posterior estimate methods experience posterior collapse. In this paper, we propose the $\beta$-Multivariational Autoencoder ($\beta$MVAE) to learn a Multivariate Gaussian prior from video frames for use as part of a single object-tracking in form of a decision-making process. We present a novel formulation for object motion in videos with a set of dependent parameters to address a single object-tracking task. The true values of the motion parameters are obtained through data analysis on the training set. The parameters population is then assumed to have a Multivariate Gaussian distribution. The $\beta$MVAE is developed to learn this entangled prior $p = N(\mu, \Sigma)$ directly from frame patches where the output is the object masks of the frame patches. We devise a bottleneck to estimate the posterior's parameters, i.e. $\mu', \Sigma'$. Via a new reparameterization trick, we learn the likelihood $p(\hat{x}|z)$ as the object mask of the input. Furthermore, we alter the neural network of $\beta$MVAE with the U-Net architecture and name the new network $\beta$Multivariational U-Net ($\beta$MVUnet). Our networks are trained from scratch via over 85k video frames for 24 ($\beta$MVUnet) and 78 ($\beta$MVAE) million steps. We show that $\beta$MVUnet enhances both posterior estimation and segmentation functioning over the test set. Our code and the trained networks are publicly released.
Multi-Task Learning based Video Anomaly Detection with Attention
Oct 14, 2022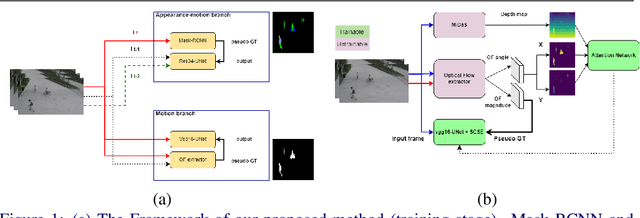
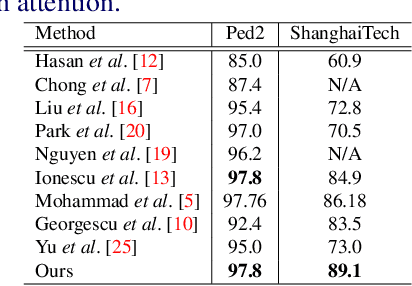
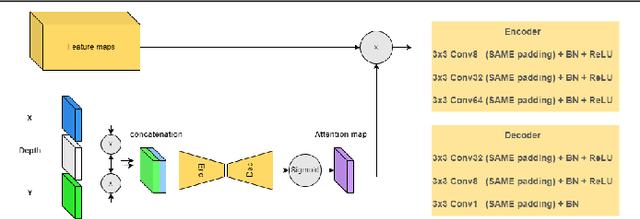

Multi-task learning based video anomaly detection methods combine multiple proxy tasks in different branches to detect video anomalies in different situations. Most existing methods either do not combine complementary tasks to effectively cover all motion patterns, or the class of the objects is not explicitly considered. To address the aforementioned shortcomings, we propose a novel multi-task learning based method that combines complementary proxy tasks to better consider the motion and appearance features. We combine the semantic segmentation and future frame prediction tasks in a single branch to learn the object class and consistent motion patterns, and to detect respective anomalies simultaneously. In the second branch, we added several attention mechanisms to detect motion anomalies with attention to object parts, the direction of motion, and the distance of the objects from the camera. Our qualitative results show that the proposed method considers the object class effectively and learns motion with attention to the aforementioned important factors which results in a precise motion modeling and a better motion anomaly detection. Additionally, quantitative results show the superiority of our method compared with state-of-the-art methods.
Object Class Aware Video Anomaly Detection through Image Translation
May 03, 2022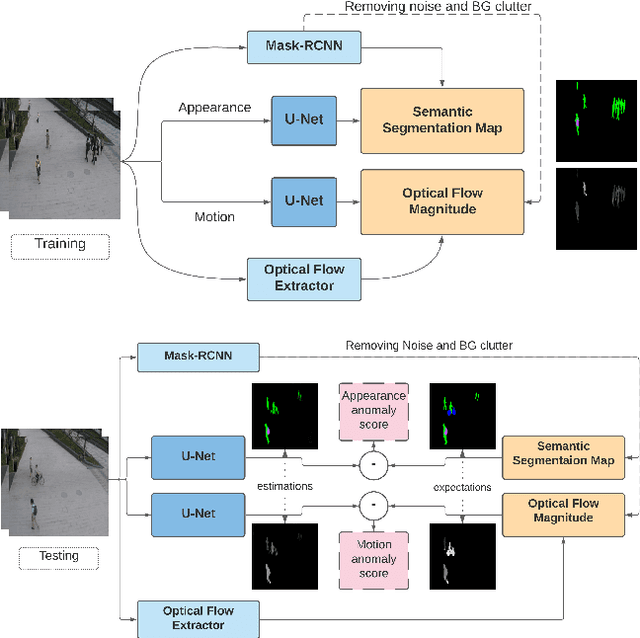
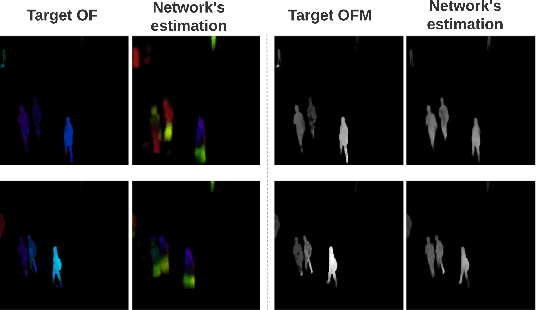
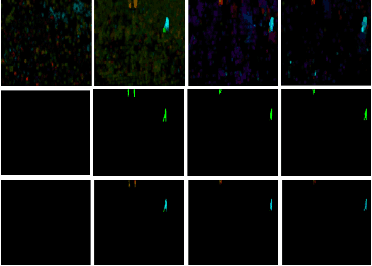
Semi-supervised video anomaly detection (VAD) methods formulate the task of anomaly detection as detection of deviations from the learned normal patterns. Previous works in the field (reconstruction or prediction-based methods) suffer from two drawbacks: 1) They focus on low-level features, and they (especially holistic approaches) do not effectively consider the object classes. 2) Object-centric approaches neglect some of the context information (such as location). To tackle these challenges, this paper proposes a novel two-stream object-aware VAD method that learns the normal appearance and motion patterns through image translation tasks. The appearance branch translates the input image to the target semantic segmentation map produced by Mask-RCNN, and the motion branch associates each frame with its expected optical flow magnitude. Any deviation from the expected appearance or motion in the inference stage shows the degree of potential abnormality. We evaluated our proposed method on the ShanghaiTech, UCSD-Ped1, and UCSD-Ped2 datasets and the results show competitive performance compared with state-of-the-art works. Most importantly, the results show that, as significant improvements to previous methods, detections by our method are completely explainable and anomalies are localized accurately in the frames.
A Critical Study on the Recent Deep Learning Based Semi-Supervised Video Anomaly Detection Methods
Nov 02, 2021

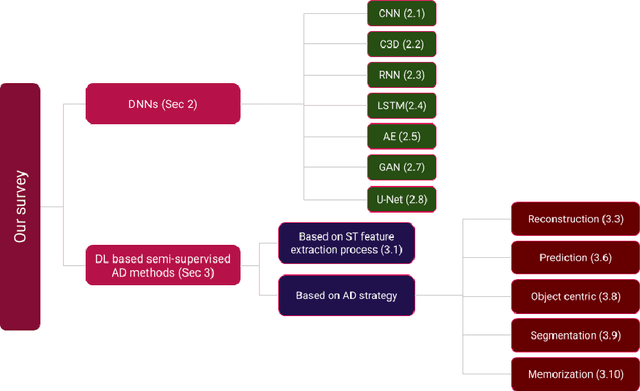
Video anomaly detection is one of the hot research topics in computer vision nowadays, as abnormal events contain a high amount of information. Anomalies are one of the main detection targets in surveillance systems, usually needing real-time actions. Regarding the availability of labeled data for training (i.e., there is not enough labeled data for abnormalities), semi-supervised anomaly detection approaches have gained interest recently. This paper introduces the researchers of the field to a new perspective and reviews the recent deep-learning based semi-supervised video anomaly detection approaches, based on a common strategy they use for anomaly detection. Our goal is to help researchers develop more effective video anomaly detection methods. As the selection of a right Deep Neural Network plays an important role for several parts of this task, a quick comparative review on DNNs is prepared first. Unlike previous surveys, DNNs are reviewed from a spatiotemporal feature extraction viewpoint, customized for video anomaly detection. This part of the review can help researchers in this field select suitable networks for different parts of their methods. Moreover, some of the state-of-the-art anomaly detection methods, based on their detection strategy, are critically surveyed. The review provides a novel and deep look at existing methods and results in stating the shortcomings of these approaches, which can be a hint for future works.
Online Mutual Foreground Segmentation for Multispectral Stereo Videos
Sep 08, 2018
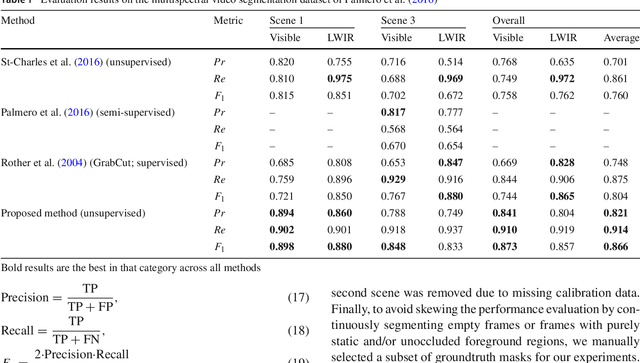
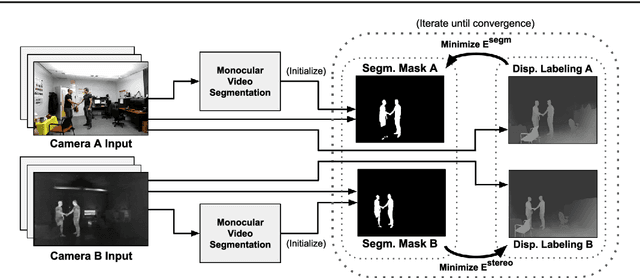
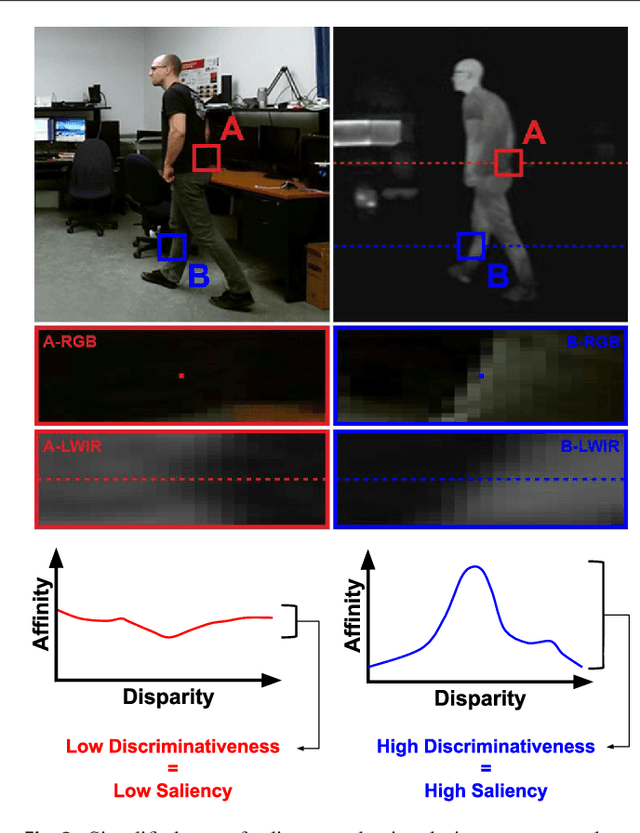
The segmentation of video sequences into foreground and background regions is a low-level process commonly used in video content analysis and smart surveillance applications. Using a multispectral camera setup can improve this process by providing more diverse data to help identify objects despite adverse imaging conditions. The registration of several data sources is however not trivial if the appearance of objects produced by each sensor differs substantially. This problem is further complicated when parallax effects cannot be ignored when using close-range stereo pairs. In this work, we present a new method to simultaneously tackle multispectral segmentation and stereo registration. Using an iterative procedure, we estimate the labeling result for one problem using the provisional result of the other. Our approach is based on the alternating minimization of two energy functions that are linked through the use of dynamic priors. We rely on the integration of shape and appearance cues to find proper multispectral correspondences, and to properly segment objects in low contrast regions. We also formulate our model as a frame processing pipeline using higher order terms to improve the temporal coherence of our results. Our method is evaluated under different configurations on multiple multispectral datasets, and our implementation is available online.
From Superpixel to Human Shape Modelling for Carried Object Detection
Jan 10, 2018


Detecting carried objects is one of the requirements for developing systems to reason about activities involving people and objects. We present an approach to detect carried objects from a single video frame with a novel method that incorporates features from multiple scales. Initially, a foreground mask in a video frame is segmented into multi-scale superpixels. Then the human-like regions in the segmented area are identified by matching a set of extracted features from superpixels against learned features in a codebook. A carried object probability map is generated using the complement of the matching probabilities of superpixels to human-like regions and background information. A group of superpixels with high carried object probability and strong edge support is then merged to obtain the shape of the carried object. We applied our method to two challenging datasets, and results show that our method is competitive with or better than the state-of-the-art.
An adaptive thresholding approach for automatic optic disk segmentation
Oct 14, 2017
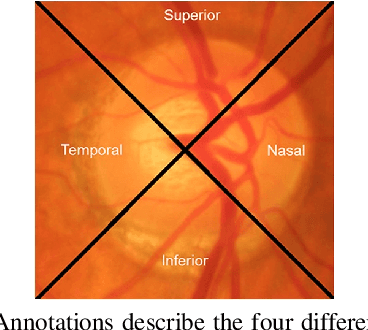
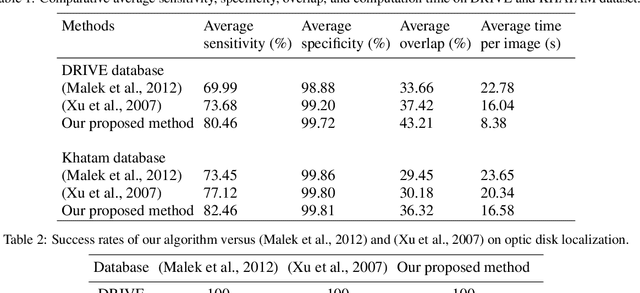
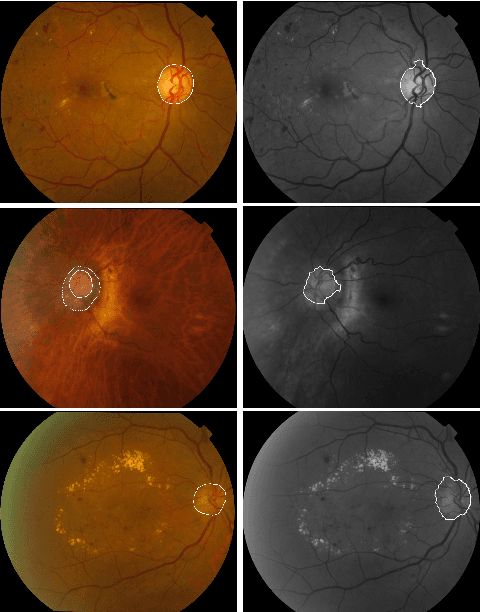
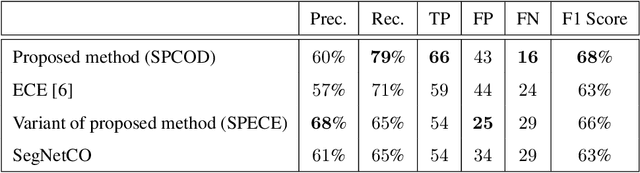
Optic disk segmentation is a prerequisite step in automatic retinal screening systems. In this paper, we propose an algorithm for optic disk segmentation based on a local adaptive thresholding method. Location of the optic disk is validated by intensity and average vessel width of retinal images. Then an adaptive thresholding is applied on the temporal and nasal part of the optic disc separately. Adaptive thresholding, makes our algorithm robust to illumination variations and various image acquisition conditions. Moreover, experimental results on the DRIVE and KHATAM databases show promising results compared to the recent literature. In the DRIVE database, the optic disk in all images is correctly located and the mean overlap reached to 43.21%. The optic disk is correctly detected in 98% of the images with the mean overlap of 36.32% in the KHATAM database.
SPiKeS: Superpixel-Keypoints Structure for Robust Visual Tracking
Oct 23, 2016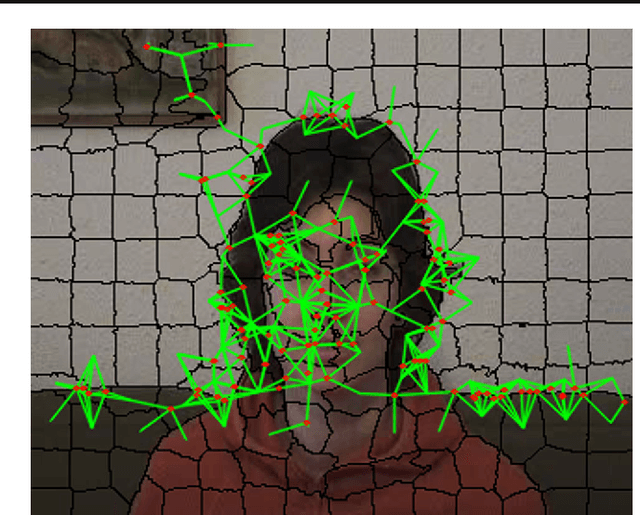
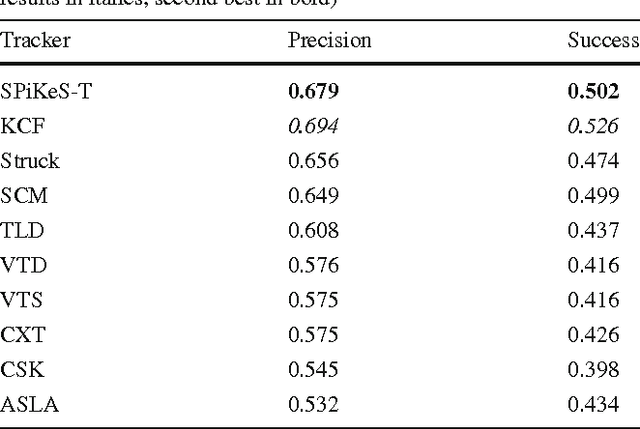
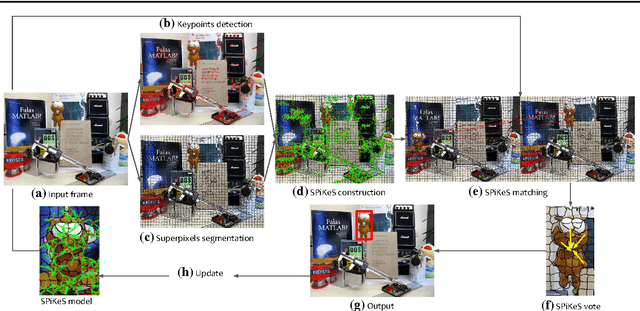
In visual tracking, part-based trackers are attractive since they are robust against occlusion and deformation. However, a part represented by a rectangular patch does not account for the shape of the target, while a superpixel does thanks to its boundary evidence. Nevertheless, tracking superpixels is difficult due to their lack of discriminative power. Therefore, to enable superpixels to be tracked discriminatively as object parts, we propose to enhance them with keypoints. By combining properties of these two features, we build a novel element designated as a Superpixel-Keypoints structure (SPiKeS). Being discriminative, these new object parts can be located efficiently by a simple nearest neighbor matching process. Then, in a tracking process, each match votes for the target's center to give its location. In addition, the interesting properties of our new feature allows the development of an efficient model update for more robust tracking. According to experimental results, our SPiKeS-based tracker proves to be robust in many challenging scenarios by performing favorably against the state-of-the-art.
Reproducible Evaluation of Pan-Tilt-Zoom Tracking
May 18, 2015
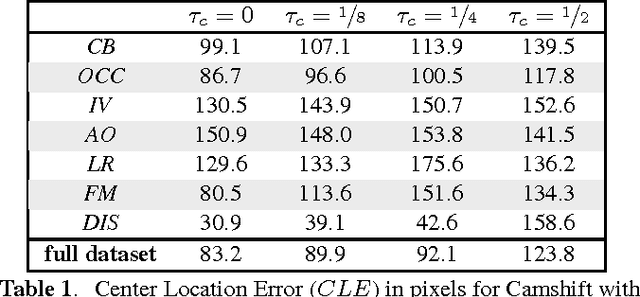
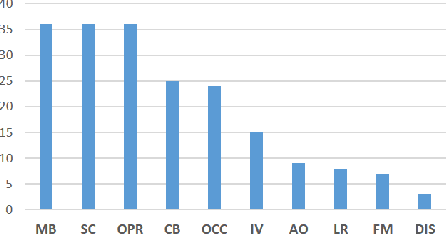

Tracking with a Pan-Tilt-Zoom (PTZ) camera has been a research topic in computer vision for many years. However, it is very difficult to assess the progress that has been made on this topic because there is no standard evaluation methodology. The difficulty in evaluating PTZ tracking algorithms arises from their dynamic nature. In contrast to other forms of tracking, PTZ tracking involves both locating the target in the image and controlling the motors of the camera to aim it so that the target stays in its field of view. This type of tracking can only be performed online. In this paper, we propose a new evaluation framework based on a virtual PTZ camera. With this framework, tracking scenarios do not change for each experiment and we are able to replicate online PTZ camera control and behavior including camera positioning delays, tracker processing delays, and numerical zoom. We tested our evaluation framework with the Camshift tracker to show its viability and to establish baseline results.