 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Video Prediction from a Single Frame for Video Anomaly Detection
Paper and Code
Aug 15, 2023


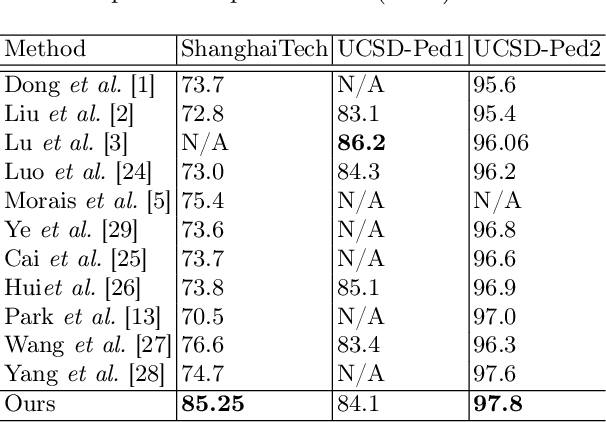
Video anomaly detection (VAD) is an important but challenging task in computer vision. The main challenge rises due to the rarity of training samples to model all anomaly cases. Hence, semi-supervised anomaly detection methods have gotten more attention, since they focus on modeling normals and they detect anomalies by measuring the deviations from normal patterns. Despite impressive advances of these methods in modeling normal motion and appearance, long-term motion modeling has not been effectively explored so far. Inspired by the abilities of the future frame prediction proxy-task, we introduce the task of future video prediction from a single frame, as a novel proxy-task for video anomaly detection. This proxy-task alleviates the challenges of previous methods in learning longer motion patterns. Moreover, we replace the initial and future raw frames with their corresponding semantic segmentation map, which not only makes the method aware of object class but also makes the prediction task less complex for the model. Extensive experiments on the benchmark datasets (ShanghaiTech, UCSD-Ped1, and UCSD-Ped2) show the effectiveness of the method and the superiority of its performance compared to SOTA prediction-based VAD methods.