 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA machine learning approach for Premature Coronary Artery Disease Diagnosis according to Different Ethnicities in Iran
Jan 31, 2025Premature coronary artery disease (PCAD) refers to the early onset of the disease, usually before the age of 55 for men and 65 for women. Coronary Artery Disease (CAD) develops when coronary arteries, the major blood vessels supplying the heart with blood, oxygen, and nutrients, become clogged or diseased. This is often due to many risk factors, including lifestyle and cardiometabolic ones, but few studies were done on ethnicity as one of these risk factors, especially in PCAD. In this study, we tested the rank of ethnicity among the major risk factors of PCAD, including age, gender, body mass index (BMI), visceral obesity presented as waist circumference (WC), diabetes mellitus (DM), high blood pressure (HBP), high low-density lipoprotein cholesterol (LDL-C), and smoking in a large national sample of patients with PCAD from different ethnicities. All patients who met the age criteria underwent coronary angiography to confirm CAD diagnosis. The weight of ethnicity was compared to the other eight features using feature weighting algorithms in PCAD diagnosis. In addition, we conducted an experiment where we ran predictive models (classification algorithms) to predict PCAD. We compared the performance of these models under two conditions: we trained the classification algorithms, including or excluding ethnicity. This study analyzed various factors to determine their predictive power influencing PCAD prediction. Among these factors, gender and age were the most significant predictors, with ethnicity being the third most important. The results also showed that if ethnicity is used as one of the input risk factors for classification algorithms, it can improve their efficiency. Our results show that ethnicity ranks as an influential factor in predicting PCAD. Therefore, it needs to be addressed in the PCAD diagnostic and preventive measures.
$β$-Multivariational Autoencoder for Entangled Representation Learning in Video Frames
Nov 22, 2022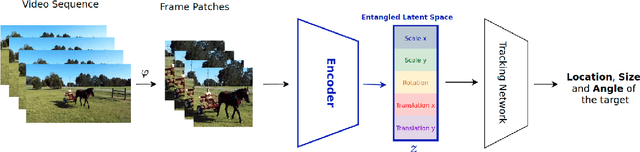
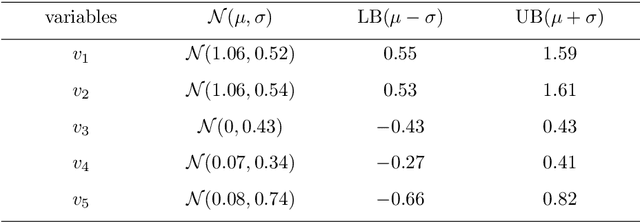
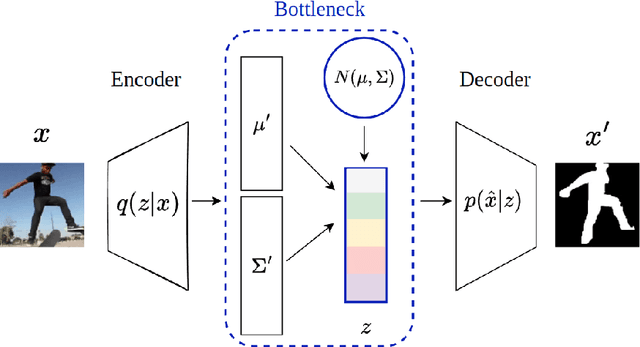
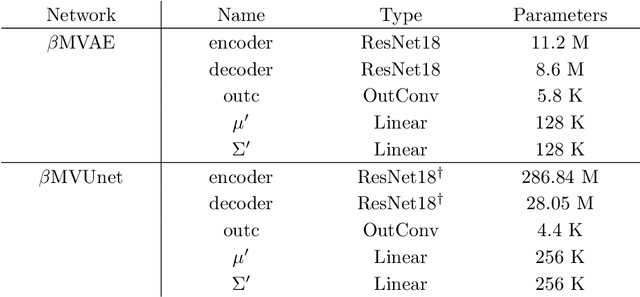
It is crucial to choose actions from an appropriate distribution while learning a sequential decision-making process in which a set of actions is expected given the states and previous reward. Yet, if there are more than two latent variables and every two variables have a covariance value, learning a known prior from data becomes challenging. Because when the data are big and diverse, many posterior estimate methods experience posterior collapse. In this paper, we propose the $\beta$-Multivariational Autoencoder ($\beta$MVAE) to learn a Multivariate Gaussian prior from video frames for use as part of a single object-tracking in form of a decision-making process. We present a novel formulation for object motion in videos with a set of dependent parameters to address a single object-tracking task. The true values of the motion parameters are obtained through data analysis on the training set. The parameters population is then assumed to have a Multivariate Gaussian distribution. The $\beta$MVAE is developed to learn this entangled prior $p = N(\mu, \Sigma)$ directly from frame patches where the output is the object masks of the frame patches. We devise a bottleneck to estimate the posterior's parameters, i.e. $\mu', \Sigma'$. Via a new reparameterization trick, we learn the likelihood $p(\hat{x}|z)$ as the object mask of the input. Furthermore, we alter the neural network of $\beta$MVAE with the U-Net architecture and name the new network $\beta$Multivariational U-Net ($\beta$MVUnet). Our networks are trained from scratch via over 85k video frames for 24 ($\beta$MVUnet) and 78 ($\beta$MVAE) million steps. We show that $\beta$MVUnet enhances both posterior estimation and segmentation functioning over the test set. Our code and the trained networks are publicly released.