 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh based segmentation for automated margin line generation on incisors receiving crown treatment
Jul 30, 2025



Dental crowns are essential dental treatments for restoring damaged or missing teeth of patients. Recent design approaches of dental crowns are carried out using commercial dental design software. Once a scan of a preparation is uploaded to the software, a dental technician needs to manually define a precise margin line on the preparation surface, which constitutes a non-repeatable and inconsistent procedure. This work proposes a new framework to determine margin lines automatically and accurately using deep learning. A dataset of incisor teeth was provided by a collaborating dental laboratory to train a deep learning segmentation model. A mesh-based neural network was modified by changing its input channels and used to segment the prepared tooth into two regions such that the margin line is contained within the boundary faces separating the two regions. Next, k-fold cross-validation was used to train 5 models, and a voting classifier technique was used to combine their results to enhance the segmentation. After that, boundary smoothing and optimization using the graph cut method were applied to refine the segmentation results. Then, boundary faces separating the two regions were selected to represent the margin line faces. A spline was approximated to best fit the centers of the boundary faces to predict the margin line. Our results show that an ensemble model combined with maximum probability predicted the highest number of successful test cases (7 out of 13) based on a maximum distance threshold of 200 m (representing human error) between the predicted and ground truth point clouds. It was also demonstrated that the better the quality of the preparation, the smaller the divergence between the predicted and ground truth margin lines (Spearman's rank correlation coefficient of -0.683). We provide the train and test datasets for the community.
From Mesh Completion to AI Designed Crown
Jan 09, 2025Designing a dental crown is a time-consuming and labor intensive process. Our goal is to simplify crown design and minimize the tediousness of making manual adjustments while still ensuring the highest level of accuracy and consistency. To this end, we present a new end- to-end deep learning approach, coined Dental Mesh Completion (DMC), to generate a crown mesh conditioned on a point cloud context. The dental context includes the tooth prepared to receive a crown and its surroundings, namely the two adjacent teeth and the three closest teeth in the opposing jaw. We formulate crown generation in terms of completing this point cloud context. A feature extractor first converts the input point cloud into a set of feature vectors that represent local regions in the point cloud. The set of feature vectors is then fed into a transformer to predict a new set of feature vectors for the missing region (crown). Subsequently, a point reconstruction head, followed by a multi-layer perceptron, is used to predict a dense set of points with normals. Finally, a differentiable point-to-mesh layer serves to reconstruct the crown surface mesh. We compare our DMC method to a graph-based convolutional neural network which learns to deform a crown mesh from a generic crown shape to the target geometry. Extensive experiments on our dataset demonstrate the effectiveness of our method, which attains an average of 0.062 Chamfer Distance.The code is available at:https://github.com/Golriz-code/DMC.gi
Improving the quality of dental crown using a Transformer-based method
Mar 04, 2023Designing a synthetic crown is a time-consuming, inconsistent, and labor-intensive process. In this work, we present a fully automatic method that not only learns human design dental crowns, but also improves the consistency, functionality, and esthetic of the crowns. Following success in point cloud completion using the transformer-based network, we tackle the problem of the crown generation as a point-cloud completion around a prepared tooth. To this end, we use a geometry-aware transformer to generate dental crowns. Our main contribution is to add a margin line information to the network, as the accuracy of generating a precise margin line directly,determines whether the designed crown and prepared tooth are closely matched to allowappropriateadhesion.Using our ground truth crown, we can extract the margin line as a spline and sample the spline into 1000 points. We feed the obtained margin line along with two neighbor teeth of the prepared tooth and three closest teeth in the opposing jaw. We also add the margin line points to our ground truth crown to increase the resolution at the margin line. Our experimental results show an improvement in the quality of the designed crown when considering the actual context composed of the prepared tooth along with the margin line compared with a crown generated in an empty space as was done by other studies in the literature.
Semi-supervised segmentation of tooth from 3D Scanned Dental Arches
Aug 10, 2022Teeth segmentation is an important topic in dental restorations that is essential for crown generation, diagnosis, and treatment planning. In the dental field, the variability of input data is high and there are no publicly available 3D dental arch datasets. Although there has been improvement in the field provided by recent deep learning architectures on 3D data, there still exists some problems such as properly identifying missing teeth in an arch. We propose to use spectral clustering as a self-supervisory signal to joint-train neural networks for segmentation of 3D arches. Our approach is motivated by the observation that K-means clustering provides cues to capture margin lines related to human perception. The main idea is to automatically generate training data by decomposing unlabeled 3D arches into segments relying solely on geometric information. The network is then trained using a joint loss that combines a supervised loss of annotated input and a self-supervised loss of non-labeled input. Our collected data has a variety of arches including arches with missing teeth. Our experimental results show improvement over the fully supervised state-of-the-art MeshSegNet when using semi-supervised learning. Finally, we contribute code and a dataset.
Adversarial Mixup Resynthesizers
Apr 04, 2019
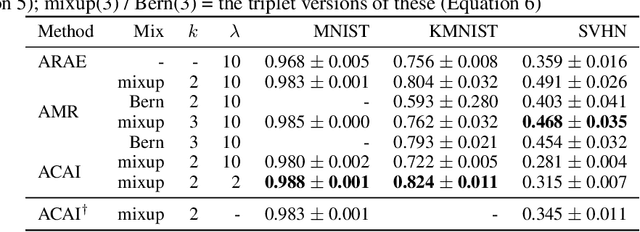
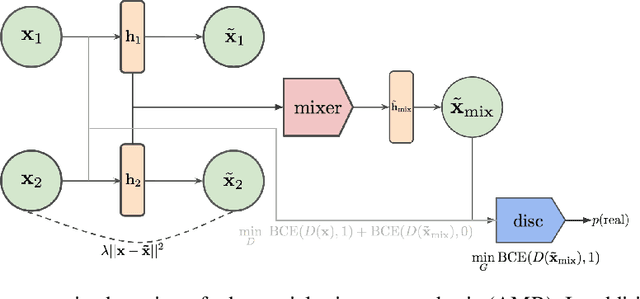
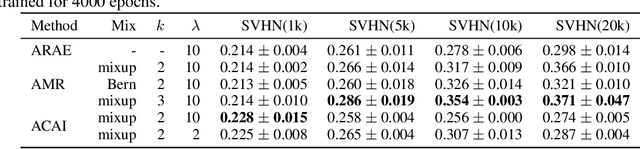
In this paper, we explore new approaches to combining information encoded within the learned representations of autoencoders. We explore models that are capable of combining the attributes of multiple inputs such that a resynthesised output is trained to fool an adversarial discriminator for real versus synthesised data. Furthermore, we explore the use of such an architecture in the context of semi-supervised learning, where we learn a mixing function whose objective is to produce interpolations of hidden states, or masked combinations of latent representations that are consistent with a conditioned class label. We show quantitative and qualitative evidence that such a formulation is an interesting avenue of research.
From Superpixel to Human Shape Modelling for Carried Object Detection
Jan 10, 2018


Detecting carried objects is one of the requirements for developing systems to reason about activities involving people and objects. We present an approach to detect carried objects from a single video frame with a novel method that incorporates features from multiple scales. Initially, a foreground mask in a video frame is segmented into multi-scale superpixels. Then the human-like regions in the segmented area are identified by matching a set of extracted features from superpixels against learned features in a codebook. A carried object probability map is generated using the complement of the matching probabilities of superpixels to human-like regions and background information. A group of superpixels with high carried object probability and strong edge support is then merged to obtain the shape of the carried object. We applied our method to two challenging datasets, and results show that our method is competitive with or better than the state-of-the-art.
An adaptive thresholding approach for automatic optic disk segmentation
Oct 14, 2017
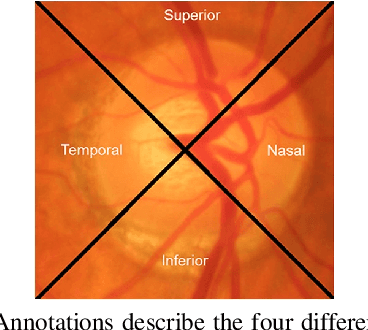
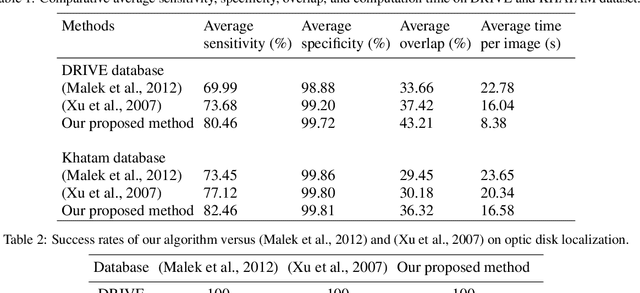
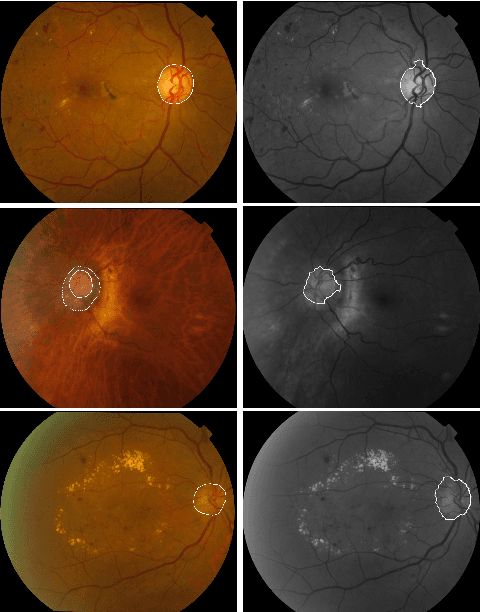
Optic disk segmentation is a prerequisite step in automatic retinal screening systems. In this paper, we propose an algorithm for optic disk segmentation based on a local adaptive thresholding method. Location of the optic disk is validated by intensity and average vessel width of retinal images. Then an adaptive thresholding is applied on the temporal and nasal part of the optic disc separately. Adaptive thresholding, makes our algorithm robust to illumination variations and various image acquisition conditions. Moreover, experimental results on the DRIVE and KHATAM databases show promising results compared to the recent literature. In the DRIVE database, the optic disk in all images is correctly located and the mean overlap reached to 43.21%. The optic disk is correctly detected in 98% of the images with the mean overlap of 36.32% in the KHATAM database.