 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInceptoFormer: A Multi-Signal Neural Framework for Parkinson's Disease Severity Evaluation from Gait
Aug 06, 2025We present InceptoFormer, a multi-signal neural framework designed for Parkinson's Disease (PD) severity evaluation via gait dynamics analysis. Our architecture introduces a 1D adaptation of the Inception model, which we refer to as Inception1D, along with a Transformer-based framework to stage PD severity according to the Hoehn and Yahr (H&Y) scale. The Inception1D component captures multi-scale temporal features by employing parallel 1D convolutional filters with varying kernel sizes, thereby extracting features across multiple temporal scales. The transformer component efficiently models long-range dependencies within gait sequences, providing a comprehensive understanding of both local and global patterns. To address the issue of class imbalance in PD severity staging, we propose a data structuring and preprocessing strategy based on oversampling to enhance the representation of underrepresented severity levels. The overall design enables to capture fine-grained temporal variations and global dynamics in gait signal, significantly improving classification performance for PD severity evaluation. Through extensive experimentation, InceptoFormer achieves an accuracy of 96.6%, outperforming existing state-of-the-art methods in PD severity assessment. The source code for our implementation is publicly available at https://github.com/SafwenNaimi/InceptoFormer
Dual-Stream Attention with Multi-Modal Queries for Object Detection in Transportation Applications
Aug 06, 2025Transformer-based object detectors often struggle with occlusions, fine-grained localization, and computational inefficiency caused by fixed queries and dense attention. We propose DAMM, Dual-stream Attention with Multi-Modal queries, a novel framework introducing both query adaptation and structured cross-attention for improved accuracy and efficiency. DAMM capitalizes on three types of queries: appearance-based queries from vision-language models, positional queries using polygonal embeddings, and random learned queries for general scene coverage. Furthermore, a dual-stream cross-attention module separately refines semantic and spatial features, boosting localization precision in cluttered scenes. We evaluated DAMM on four challenging benchmarks, and it achieved state-of-the-art performance in average precision (AP) and recall, demonstrating the effectiveness of multi-modal query adaptation and dual-stream attention. Source code is at: \href{https://github.com/DET-LIP/DAMM}{GitHub}.
How good are deep learning methods for automated road safety analysis using video data? An experimental study
Mar 12, 2025Image-based multi-object detection (MOD) and multi-object tracking (MOT) are advancing at a fast pace. A variety of 2D and 3D MOD and MOT methods have been developed for monocular and stereo cameras. Road safety analysis can benefit from those advancements. As crashes are rare events, surrogate measures of safety (SMoS) have been developed for safety analyses. (Semi-)Automated safety analysis methods extract road user trajectories to compute safety indicators, for example, Time-to-Collision (TTC) and Post-encroachment Time (PET). Inspired by the success of deep learning in MOD and MOT, we investigate three MOT methods, including one based on a stereo-camera, using the annotated KITTI traffic video dataset. Two post-processing steps, IDsplit and SS, are developed to improve the tracking results and investigate the factors influencing the TTC. The experimental results show that, despite some advantages in terms of the numbers of interactions or similarity to the TTC distributions, all the tested methods systematically over-estimate the number of interactions and under-estimate the TTC: they report more interactions and more severe interactions, making the road user interactions appear less safe than they are. Further efforts will be directed towards testing more methods and more data, in particular from roadside sensors, to verify the results and improve the performance.
ReL-SAR: Representation Learning for Skeleton Action Recognition with Convolutional Transformers and BYOL
Sep 09, 2024To extract robust and generalizable skeleton action recognition features, large amounts of well-curated data are typically required, which is a challenging task hindered by annotation and computation costs. Therefore, unsupervised representation learning is of prime importance to leverage unlabeled skeleton data. In this work, we investigate unsupervised representation learning for skeleton action recognition. For this purpose, we designed a lightweight convolutional transformer framework, named ReL-SAR, exploiting the complementarity of convolutional and attention layers for jointly modeling spatial and temporal cues in skeleton sequences. We also use a Selection-Permutation strategy for skeleton joints to ensure more informative descriptions from skeletal data. Finally, we capitalize on Bootstrap Your Own Latent (BYOL) to learn robust representations from unlabeled skeleton sequence data. We achieved very competitive results on limited-size datasets: MCAD, IXMAS, JHMDB, and NW-UCLA, showing the effectiveness of our proposed method against state-of-the-art methods in terms of both performance and computational efficiency. To ensure reproducibility and reusability, the source code including all implementation parameters is provided at: https://github.com/SafwenNaimi/Representation-Learning-for-Skeleton-Action-Recognition-with-Convolutional-Transformers-and-BYOL
Learning Data Association for Multi-Object Tracking using Only Coordinates
Mar 12, 2024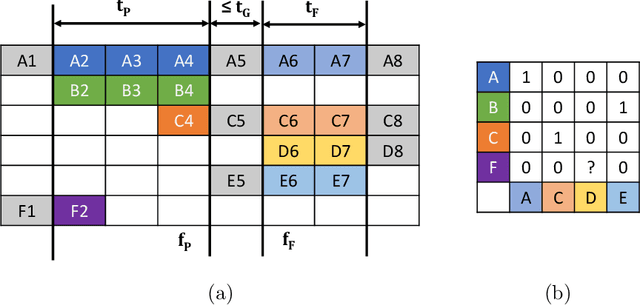

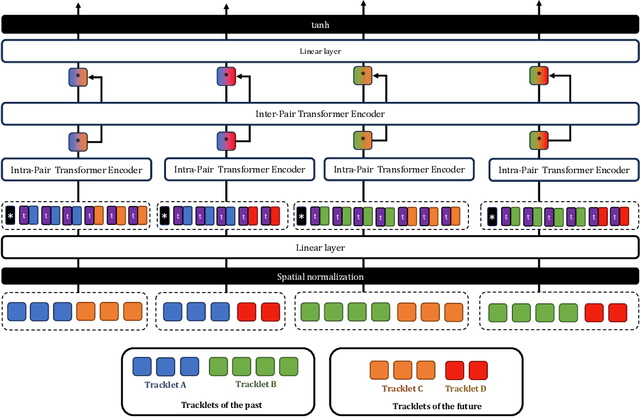
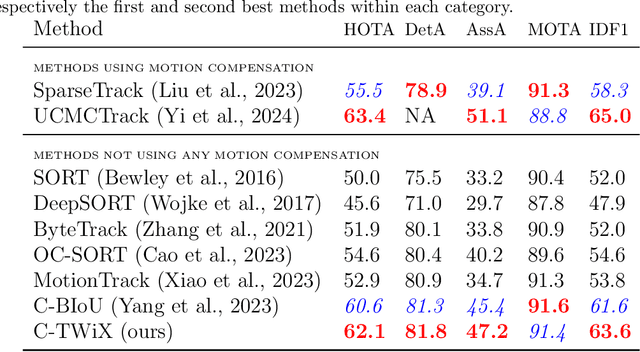
We propose a novel Transformer-based module to address the data association problem for multi-object tracking. From detections obtained by a pretrained detector, this module uses only coordinates from bounding boxes to estimate an affinity score between pairs of tracks extracted from two distinct temporal windows. This module, named TWiX, is trained on sets of tracks with the objective of discriminating pairs of tracks coming from the same object from those which are not. Our module does not use the intersection over union measure, nor does it requires any motion priors or any camera motion compensation technique. By inserting TWiX within an online cascade matching pipeline, our tracker C-TWiX achieves state-of-the-art performance on the DanceTrack and KITTIMOT datasets, and gets competitive results on the MOT17 dataset. The code will be made available upon publication.
CenterDisks: Real-time instance segmentation with disk covering
Mar 05, 2024



Increasing the accuracy of instance segmentation methods is often done at the expense of speed. Using coarser representations, we can reduce the number of parameters and thus obtain real-time masks. In this paper, we take inspiration from the set cover problem to predict mask approximations. Given ground-truth binary masks of objects of interest as training input, our method learns to predict the approximate coverage of these objects by disks without supervision on their location or radius. Each object is represented by a fixed number of disks with different radii. In the learning phase, we consider the radius as proportional to a standard deviation in order to compute the error to propagate on a set of two-dimensional Gaussian functions rather than disks. We trained and tested our instance segmentation method on challenging datasets showing dense urban settings with various road users. Our method achieve state-of-the art results on the IDD and KITTI dataset with an inference time of 0.040 s on a single RTX 3090 GPU.
Detection of Micromobility Vehicles in Urban Traffic Videos
Feb 28, 2024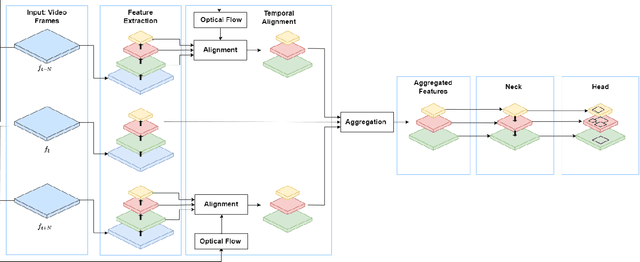

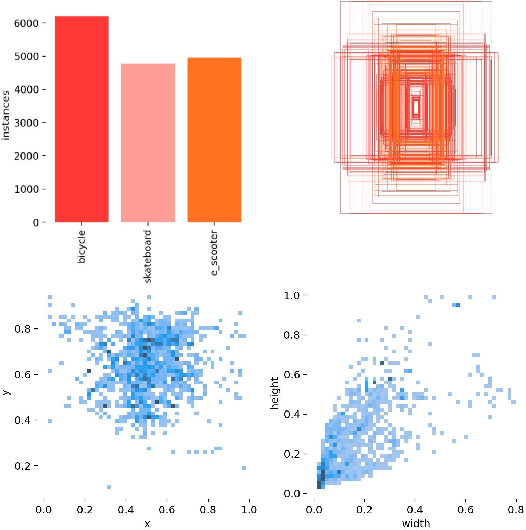

Urban traffic environments present unique challenges for object detection, particularly with the increasing presence of micromobility vehicles like e-scooters and bikes. To address this object detection problem, this work introduces an adapted detection model that combines the accuracy and speed of single-frame object detection with the richer features offered by video object detection frameworks. This is done by applying aggregated feature maps from consecutive frames processed through motion flow to the YOLOX architecture. This fusion brings a temporal perspective to YOLOX detection abilities, allowing for a better understanding of urban mobility patterns and substantially improving detection reliability. Tested on a custom dataset curated for urban micromobility scenarios, our model showcases substantial improvement over existing state-of-the-art methods, demonstrating the need to consider spatio-temporal information for detecting such small and thin objects. Our approach enhances detection in challenging conditions, including occlusions, ensuring temporal consistency, and effectively mitigating motion blur.
STF: Spatio-Temporal Fusion Module for Improving Video Object Detection
Feb 16, 2024



Consecutive frames in a video contain redundancy, but they may also contain relevant complementary information for the detection task. The objective of our work is to leverage this complementary information to improve detection. Therefore, we propose a spatio-temporal fusion framework (STF). We first introduce multi-frame and single-frame attention modules that allow a neural network to share feature maps between nearby frames to obtain more robust object representations. Second, we introduce a dual-frame fusion module that merges feature maps in a learnable manner to improve them. Our evaluation is conducted on three different benchmarks including video sequences of moving road users. The performed experiments demonstrate that the proposed spatio-temporal fusion module leads to improved detection performance compared to baseline object detectors. Code is available at https://github.com/noreenanwar/STF-module
STDiff: Spatio-temporal Diffusion for Continuous Stochastic Video Prediction
Dec 11, 2023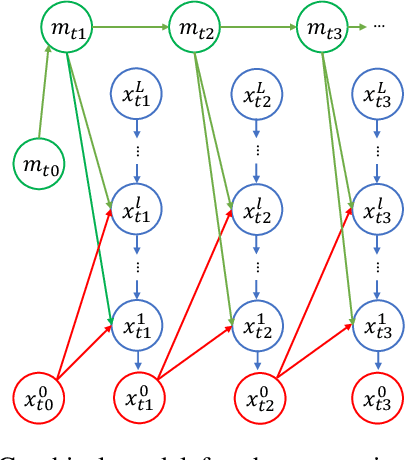



Predicting future frames of a video is challenging because it is difficult to learn the uncertainty of the underlying factors influencing their contents. In this paper, we propose a novel video prediction model, which has infinite-dimensional latent variables over the spatio-temporal domain. Specifically, we first decompose the video motion and content information, then take a neural stochastic differential equation to predict the temporal motion information, and finally, an image diffusion model autoregressively generates the video frame by conditioning on the predicted motion feature and the previous frame. The better expressiveness and stronger stochasticity learning capability of our model lead to state-of-the-art video prediction performances. As well, our model is able to achieve temporal continuous prediction, i.e., predicting in an unsupervised way the future video frames with an arbitrarily high frame rate. Our code is available at \url{https://github.com/XiYe20/STDiffProject}.
1D-Convolutional transformer for Parkinson disease diagnosis from gait
Nov 06, 2023



This paper presents an efficient deep neural network model for diagnosing Parkinson's disease from gait. More specifically, we introduce a hybrid ConvNet-Transformer architecture to accurately diagnose the disease by detecting the severity stage. The proposed architecture exploits the strengths of both Convolutional Neural Networks and Transformers in a single end-to-end model, where the former is able to extract relevant local features from Vertical Ground Reaction Force (VGRF) signal, while the latter allows to capture long-term spatio-temporal dependencies in data. In this manner, our hybrid architecture achieves an improved performance compared to using either models individually. Our experimental results show that our approach is effective for detecting the different stages of Parkinson's disease from gait data, with a final accuracy of 88%, outperforming other state-of-the-art AI methods on the Physionet gait dataset. Moreover, our method can be generalized and adapted for other classification problems to jointly address the feature relevance and spatio-temporal dependency problems in 1D signals. Our source code and pre-trained models are publicly available at https://github.com/SafwenNaimi/1D-Convolutional-transformer-for-Parkinson-disease-diagnosis-from-gait.