 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInceptoFormer: A Multi-Signal Neural Framework for Parkinson's Disease Severity Evaluation from Gait
Aug 06, 2025We present InceptoFormer, a multi-signal neural framework designed for Parkinson's Disease (PD) severity evaluation via gait dynamics analysis. Our architecture introduces a 1D adaptation of the Inception model, which we refer to as Inception1D, along with a Transformer-based framework to stage PD severity according to the Hoehn and Yahr (H&Y) scale. The Inception1D component captures multi-scale temporal features by employing parallel 1D convolutional filters with varying kernel sizes, thereby extracting features across multiple temporal scales. The transformer component efficiently models long-range dependencies within gait sequences, providing a comprehensive understanding of both local and global patterns. To address the issue of class imbalance in PD severity staging, we propose a data structuring and preprocessing strategy based on oversampling to enhance the representation of underrepresented severity levels. The overall design enables to capture fine-grained temporal variations and global dynamics in gait signal, significantly improving classification performance for PD severity evaluation. Through extensive experimentation, InceptoFormer achieves an accuracy of 96.6%, outperforming existing state-of-the-art methods in PD severity assessment. The source code for our implementation is publicly available at https://github.com/SafwenNaimi/InceptoFormer
ReL-SAR: Representation Learning for Skeleton Action Recognition with Convolutional Transformers and BYOL
Sep 09, 2024To extract robust and generalizable skeleton action recognition features, large amounts of well-curated data are typically required, which is a challenging task hindered by annotation and computation costs. Therefore, unsupervised representation learning is of prime importance to leverage unlabeled skeleton data. In this work, we investigate unsupervised representation learning for skeleton action recognition. For this purpose, we designed a lightweight convolutional transformer framework, named ReL-SAR, exploiting the complementarity of convolutional and attention layers for jointly modeling spatial and temporal cues in skeleton sequences. We also use a Selection-Permutation strategy for skeleton joints to ensure more informative descriptions from skeletal data. Finally, we capitalize on Bootstrap Your Own Latent (BYOL) to learn robust representations from unlabeled skeleton sequence data. We achieved very competitive results on limited-size datasets: MCAD, IXMAS, JHMDB, and NW-UCLA, showing the effectiveness of our proposed method against state-of-the-art methods in terms of both performance and computational efficiency. To ensure reproducibility and reusability, the source code including all implementation parameters is provided at: https://github.com/SafwenNaimi/Representation-Learning-for-Skeleton-Action-Recognition-with-Convolutional-Transformers-and-BYOL
1D-Convolutional transformer for Parkinson disease diagnosis from gait
Nov 06, 2023



This paper presents an efficient deep neural network model for diagnosing Parkinson's disease from gait. More specifically, we introduce a hybrid ConvNet-Transformer architecture to accurately diagnose the disease by detecting the severity stage. The proposed architecture exploits the strengths of both Convolutional Neural Networks and Transformers in a single end-to-end model, where the former is able to extract relevant local features from Vertical Ground Reaction Force (VGRF) signal, while the latter allows to capture long-term spatio-temporal dependencies in data. In this manner, our hybrid architecture achieves an improved performance compared to using either models individually. Our experimental results show that our approach is effective for detecting the different stages of Parkinson's disease from gait data, with a final accuracy of 88%, outperforming other state-of-the-art AI methods on the Physionet gait dataset. Moreover, our method can be generalized and adapted for other classification problems to jointly address the feature relevance and spatio-temporal dependency problems in 1D signals. Our source code and pre-trained models are publicly available at https://github.com/SafwenNaimi/1D-Convolutional-transformer-for-Parkinson-disease-diagnosis-from-gait.
Automating lichen monitoring in ecological studies using instance segmentation of time-lapse images
Oct 26, 2023Lichens are symbiotic organisms composed of fungi, algae, and/or cyanobacteria that thrive in a variety of environments. They play important roles in carbon and nitrogen cycling, and contribute directly and indirectly to biodiversity. Ecologists typically monitor lichens by using them as indicators to assess air quality and habitat conditions. In particular, epiphytic lichens, which live on trees, are key markers of air quality and environmental health. A new method of monitoring epiphytic lichens involves using time-lapse cameras to gather images of lichen populations. These cameras are used by ecologists in Newfoundland and Labrador to subsequently analyze and manually segment the images to determine lichen thalli condition and change. These methods are time-consuming and susceptible to observer bias. In this work, we aim to automate the monitoring of lichens over extended periods and to estimate their biomass and condition to facilitate the task of ecologists. To accomplish this, our proposed framework uses semantic segmentation with an effective training approach to automate monitoring and biomass estimation of epiphytic lichens on time-lapse images. We show that our method has the potential to significantly improve the accuracy and efficiency of lichen population monitoring, making it a valuable tool for forest ecologists and environmental scientists to evaluate the impact of climate change on Canada's forests. To the best of our knowledge, this is the first time that such an approach has been used to assist ecologists in monitoring and analyzing epiphytic lichens.
HCT: Hybrid Convnet-Transformer for Parkinson's disease detection and severity prediction from gait
Oct 26, 2023



In this paper, we propose a novel deep learning method based on a new Hybrid ConvNet-Transformer architecture to detect and stage Parkinson's disease (PD) from gait data. We adopt a two-step approach by dividing the problem into two sub-problems. Our Hybrid ConvNet-Transformer model first distinguishes healthy versus parkinsonian patients. If the patient is parkinsonian, a multi-class Hybrid ConvNet-Transformer model determines the Hoehn and Yahr (H&Y) score to assess the PD severity stage. Our hybrid architecture exploits the strengths of both Convolutional Neural Networks (ConvNets) and Transformers to accurately detect PD and determine the severity stage. In particular, we take advantage of ConvNets to capture local patterns and correlations in the data, while we exploit Transformers for handling long-term dependencies in the input signal. We show that our hybrid method achieves superior performance when compared to other state-of-the-art methods, with a PD detection accuracy of 97% and a severity staging accuracy of 87%. Our source code is available at: https://github.com/SafwenNaimi
Hybrid BYOL-ViT: Efficient approach to deal with small datasets
Nov 15, 2021

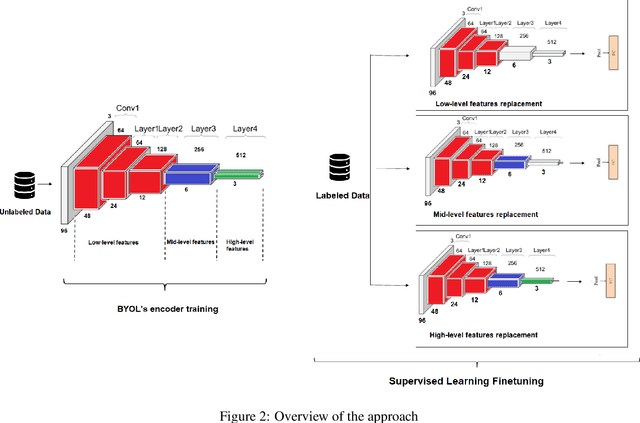
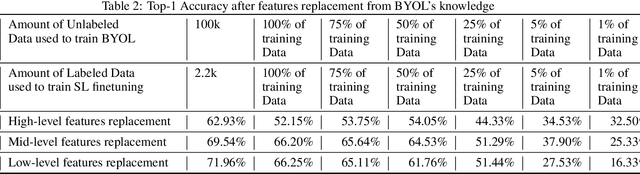
Supervised learning can learn large representational spaces, which are crucial for handling difficult learning tasks. However, due to the design of the model, classical image classification approaches struggle to generalize to new problems and new situations when dealing with small datasets. In fact, supervised learning can lose the location of image features which leads to supervision collapse in very deep architectures. In this paper, we investigate how self-supervision with strong and sufficient augmentation of unlabeled data can train effectively the first layers of a neural network even better than supervised learning, with no need for millions of labeled data. The main goal is to disconnect pixel data from annotation by getting generic task-agnostic low-level features. Furthermore, we look into Vision Transformers (ViT) and show that the low-level features derived from a self-supervised architecture can improve the robustness and the overall performance of this emergent architecture. We evaluated our method on one of the smallest open-source datasets STL-10 and we obtained a significant boost of performance from 41.66% to 83.25% when inputting low-level features from a self-supervised learning architecture to the ViT instead of the raw images.