 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid BYOL-ViT: Efficient approach to deal with small datasets
Paper and Code
Nov 15, 2021

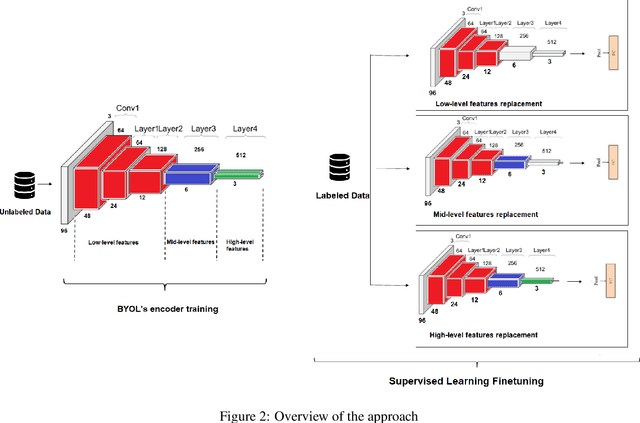
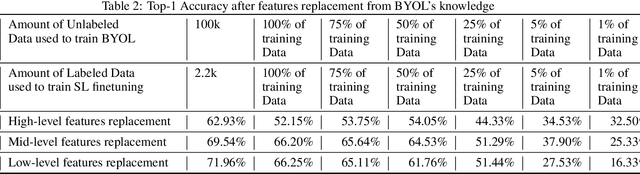
Supervised learning can learn large representational spaces, which are crucial for handling difficult learning tasks. However, due to the design of the model, classical image classification approaches struggle to generalize to new problems and new situations when dealing with small datasets. In fact, supervised learning can lose the location of image features which leads to supervision collapse in very deep architectures. In this paper, we investigate how self-supervision with strong and sufficient augmentation of unlabeled data can train effectively the first layers of a neural network even better than supervised learning, with no need for millions of labeled data. The main goal is to disconnect pixel data from annotation by getting generic task-agnostic low-level features. Furthermore, we look into Vision Transformers (ViT) and show that the low-level features derived from a self-supervised architecture can improve the robustness and the overall performance of this emergent architecture. We evaluated our method on one of the smallest open-source datasets STL-10 and we obtained a significant boost of performance from 41.66% to 83.25% when inputting low-level features from a self-supervised learning architecture to the ViT instead of the raw images.