 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Data Association for Multi-Object Tracking using Only Coordinates
Mar 12, 2024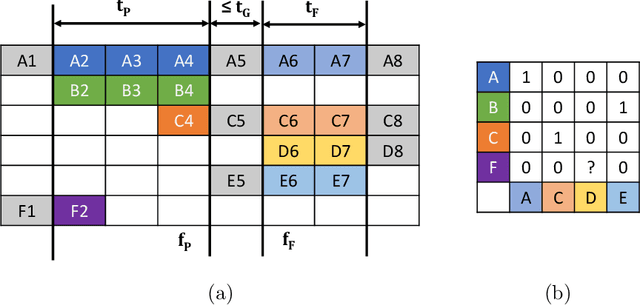

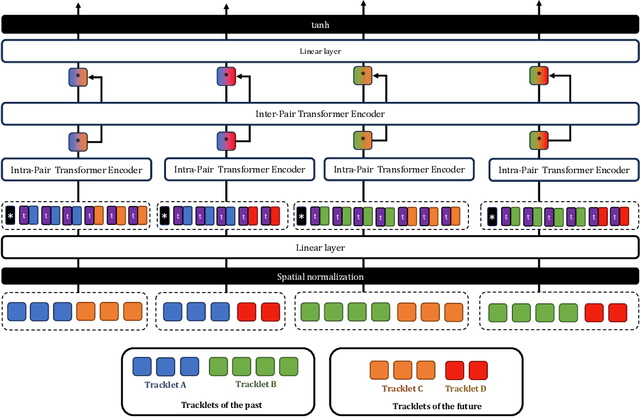
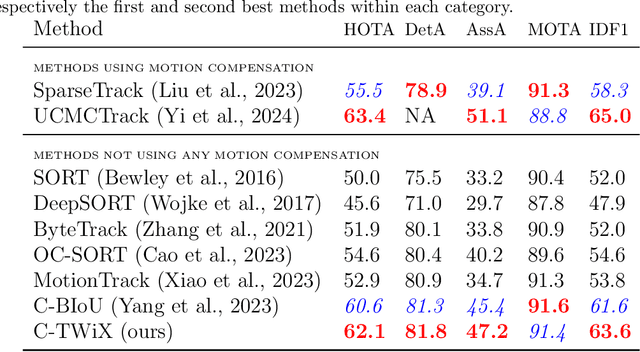
We propose a novel Transformer-based module to address the data association problem for multi-object tracking. From detections obtained by a pretrained detector, this module uses only coordinates from bounding boxes to estimate an affinity score between pairs of tracks extracted from two distinct temporal windows. This module, named TWiX, is trained on sets of tracks with the objective of discriminating pairs of tracks coming from the same object from those which are not. Our module does not use the intersection over union measure, nor does it requires any motion priors or any camera motion compensation technique. By inserting TWiX within an online cascade matching pipeline, our tracker C-TWiX achieves state-of-the-art performance on the DanceTrack and KITTIMOT datasets, and gets competitive results on the MOT17 dataset. The code will be made available upon publication.
Transformers for 1D Signals in Parkinson's Disease Detection from Gait
Apr 01, 2022



This paper focuses on the detection of Parkinson's disease based on the analysis of a patient's gait. The growing popularity and success of Transformer networks in natural language processing and image recognition motivated us to develop a novel method for this problem based on an automatic features extraction via Transformers. The use of Transformers in 1D signal is not really widespread yet, but we show in this paper that they are effective in extracting relevant features from 1D signals. As Transformers require a lot of memory, we decoupled temporal and spatial information to make the model smaller. Our architecture used temporal Transformers, dimension reduction layers to reduce the dimension of the data, a spatial Transformer, two fully connected layers and an output layer for the final prediction. Our model outperforms the current state-of-the-art algorithm with 95.2\% accuracy in distinguishing a Parkinsonian patient from a healthy one on the Physionet dataset. A key learning from this work is that Transformers allow for greater stability in results. The source code and pre-trained models are released in https://github.com/DucMinhDimitriNguyen/Transformers-for-1D-signals-in-Parkinson-s-disease-detection-from-gait.git
Multi-Object Tracking and Segmentation with a Space-Time Memory Network
Oct 21, 2021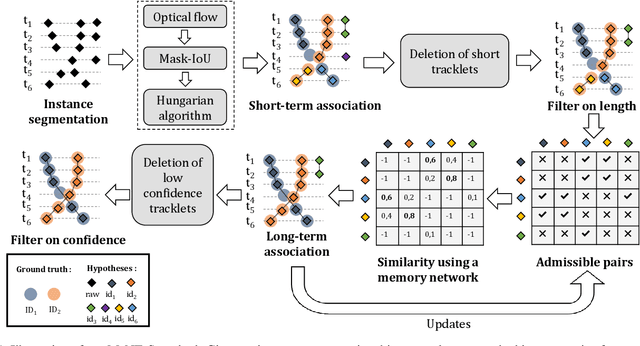
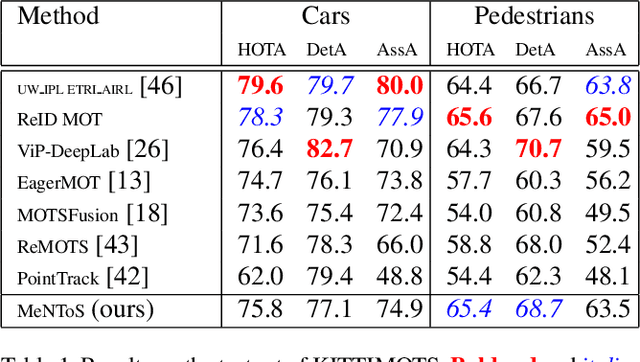
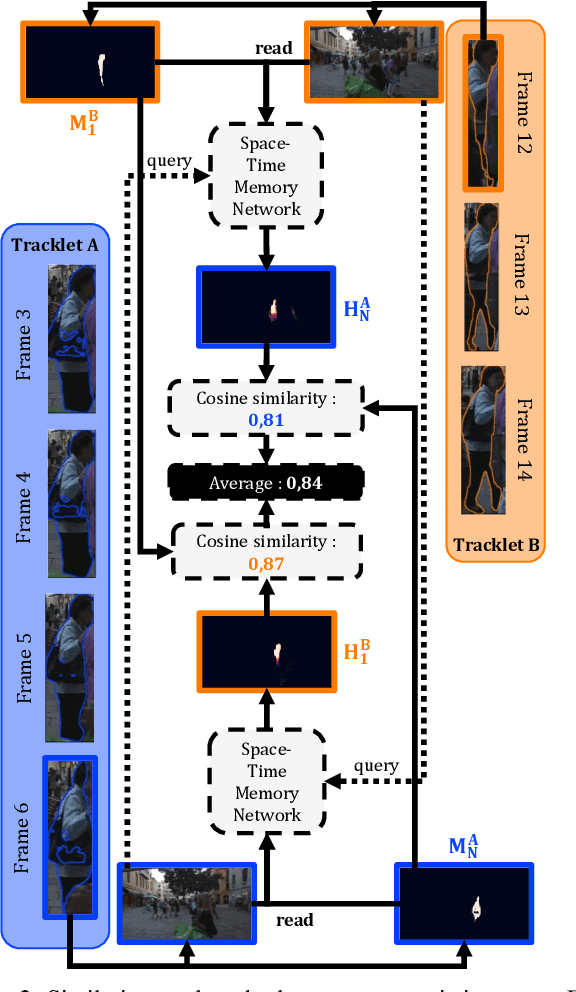
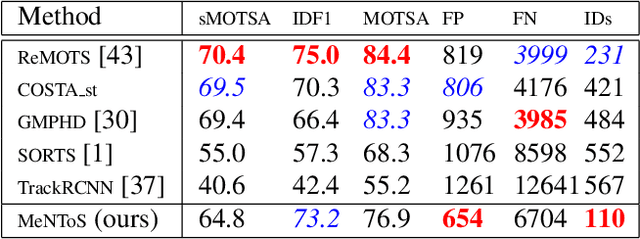
We propose a method for multi-object tracking and segmentation that does not require fine-tuning or per benchmark hyper-parameter selection. The proposed tracker, MeNToS, addresses particularly the data association problem. Indeed, the recently introduced HOTA metric, which has a better alignment with the human visual assessment by evenly balancing detections and associations quality, has shown that improvements are still needed for data association. After creating tracklets using instance segmentation and optical flow, the proposed method relies on a space-time memory network developed for one-shot video object segmentation to improve the association of tracklets with temporal gaps. We evaluated our tracker on KITTIMOTS and MOTSChallenge and show the benefit of our data association strategy with the HOTA metric. The project page is \url{www.mehdimiah.com/mentos+}.
MeNToS: Tracklets Association with a Space-Time Memory Network
Jul 15, 2021


We propose a method for multi-object tracking and segmentation (MOTS) that does not require fine-tuning or per benchmark hyperparameter selection. The proposed method addresses particularly the data association problem. Indeed, the recently introduced HOTA metric, that has a better alignment with the human visual assessment by evenly balancing detections and associations quality, has shown that improvements are still needed for data association. After creating tracklets using instance segmentation and optical flow, the proposed method relies on a space-time memory network (STM) developed for one-shot video object segmentation to improve the association of tracklets with temporal gaps. To the best of our knowledge, our method, named MeNToS, is the first to use the STM network to track object masks for MOTS. We took the 4th place in the RobMOTS challenge. The project page is https://mehdimiah.com/mentos.html.
An Empirical Analysis of Visual Features for Multiple Object Tracking in Urban Scenes
Oct 15, 2020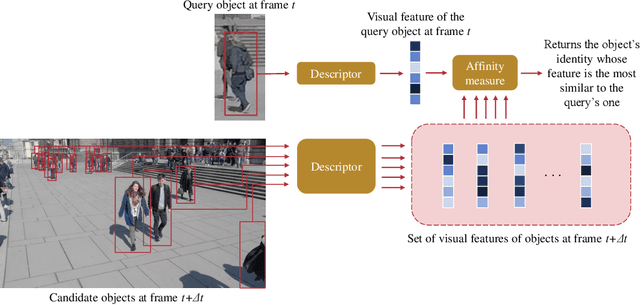
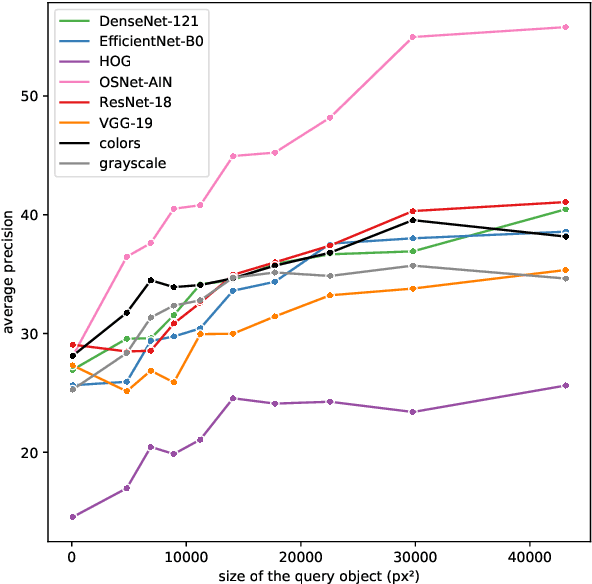

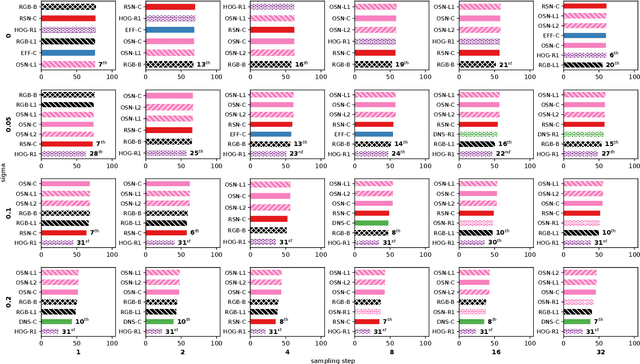
This paper addresses the problem of selecting appearance features for multiple object tracking (MOT) in urban scenes. Over the years, a large number of features has been used for MOT. However, it is not clear whether some of them are better than others. Commonly used features are color histograms, histograms of oriented gradients, deep features from convolutional neural networks and re-identification (ReID) features. In this study, we assess how good these features are at discriminating objects enclosed by a bounding box in urban scene tracking scenarios. Several affinity measures, namely the $\mathrm{L}_1$, $\mathrm{L}_2$ and the Bhattacharyya distances, Rank-1 counts and the cosine similarity, are also assessed for their impact on the discriminative power of the features. Results on several datasets show that features from ReID networks are the best for discriminating instances from one another regardless of the quality of the detector. If a ReID model is not available, color histograms may be selected if the detector has a good recall and there are few occlusions; otherwise, deep features are more robust to detectors with lower recall. The project page is http://www.mehdimiah.com/visual_features.