 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDiff: Spatio-temporal Diffusion for Continuous Stochastic Video Prediction
Paper and Code
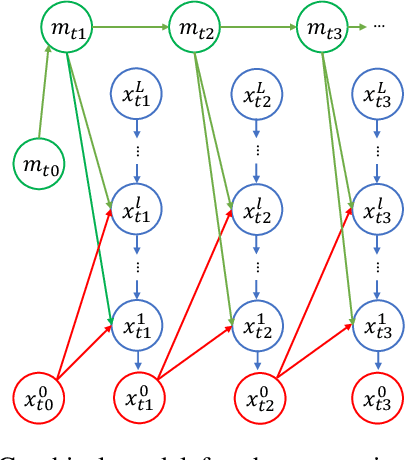



Predicting future frames of a video is challenging because it is difficult to learn the uncertainty of the underlying factors influencing their contents. In this paper, we propose a novel video prediction model, which has infinite-dimensional latent variables over the spatio-temporal domain. Specifically, we first decompose the video motion and content information, then take a neural stochastic differential equation to predict the temporal motion information, and finally, an image diffusion model autoregressively generates the video frame by conditioning on the predicted motion feature and the previous frame. The better expressiveness and stronger stochasticity learning capability of our model lead to state-of-the-art video prediction performances. As well, our model is able to achieve temporal continuous prediction, i.e., predicting in an unsupervised way the future video frames with an arbitrarily high frame rate. Our code is available at \url{https://github.com/XiYe20/STDiffProject}.