 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Clinicians with Medical Decision Transformers: A Framework for Sepsis Treatment
Jul 28, 2024Offline reinforcement learning has shown promise for solving tasks in safety-critical settings, such as clinical decision support. Its application, however, has been limited by the lack of interpretability and interactivity for clinicians. To address these challenges, we propose the medical decision transformer (MeDT), a novel and versatile framework based on the goal-conditioned reinforcement learning paradigm for sepsis treatment recommendation. MeDT uses the decision transformer architecture to learn a policy for drug dosage recommendation. During offline training, MeDT utilizes collected treatment trajectories to predict administered treatments for each time step, incorporating known treatment outcomes, target acuity scores, past treatment decisions, and current and past medical states. This analysis enables MeDT to capture complex dependencies among a patient's medical history, treatment decisions, outcomes, and short-term effects on stability. Our proposed conditioning uses acuity scores to address sparse reward issues and to facilitate clinician-model interactions, enhancing decision-making. Following training, MeDT can generate tailored treatment recommendations by conditioning on the desired positive outcome (survival) and user-specified short-term stability improvements. We carry out rigorous experiments on data from the MIMIC-III dataset and use off-policy evaluation to demonstrate that MeDT recommends interventions that outperform or are competitive with existing offline reinforcement learning methods while enabling a more interpretable, personalized and clinician-directed approach.
Transformers in Reinforcement Learning: A Survey
Jul 12, 2023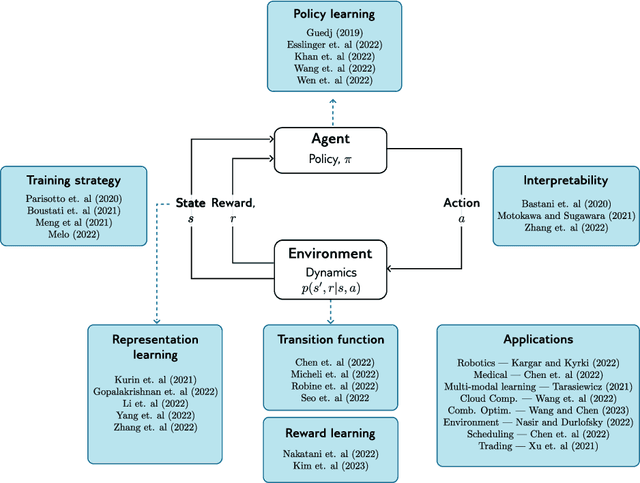
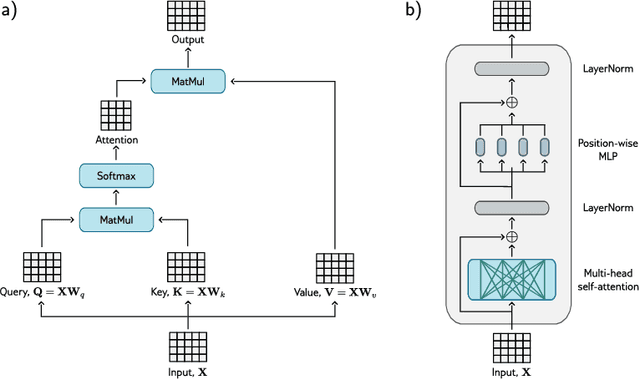

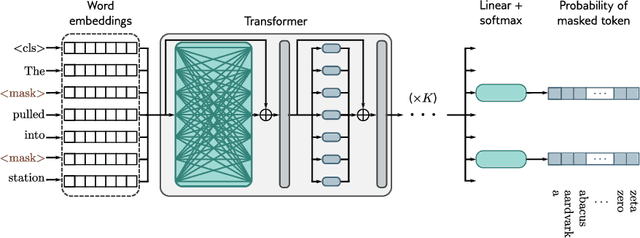
Transformers have significantly impacted domains like natural language processing, computer vision, and robotics, where they improve performance compared to other neural networks. This survey explores how transformers are used in reinforcement learning (RL), where they are seen as a promising solution for addressing challenges such as unstable training, credit assignment, lack of interpretability, and partial observability. We begin by providing a brief domain overview of RL, followed by a discussion on the challenges of classical RL algorithms. Next, we delve into the properties of the transformer and its variants and discuss the characteristics that make them well-suited to address the challenges inherent in RL. We examine the application of transformers to various aspects of RL, including representation learning, transition and reward function modeling, and policy optimization. We also discuss recent research that aims to enhance the interpretability and efficiency of transformers in RL, using visualization techniques and efficient training strategies. Often, the transformer architecture must be tailored to the specific needs of a given application. We present a broad overview of how transformers have been adapted for several applications, including robotics, medicine, language modeling, cloud computing, and combinatorial optimization. We conclude by discussing the limitations of using transformers in RL and assess their potential for catalyzing future breakthroughs in this field.
Pitfalls of Conditional Batch Normalization for Contextual Multi-Modal Learning
Nov 28, 2022Humans have perfected the art of learning from multiple modalities through sensory organs. Despite their impressive predictive performance on a single modality, neural networks cannot reach human level accuracy with respect to multiple modalities. This is a particularly challenging task due to variations in the structure of respective modalities. Conditional Batch Normalization (CBN) is a popular method that was proposed to learn contextual features to aid deep learning tasks. This technique uses auxiliary data to improve representational power by learning affine transformations for convolutional neural networks. Despite the boost in performance observed by using CBN layers, our work reveals that the visual features learned by introducing auxiliary data via CBN deteriorates. We perform comprehensive experiments to evaluate the brittleness of CBN networks to various datasets, suggesting that learning from visual features alone could often be superior for generalization. We evaluate CBN models on natural images for bird classification and histology images for cancer type classification. We observe that the CBN network learns close to no visual features on the bird classification dataset and partial visual features on the histology dataset. Our extensive experiments reveal that CBN may encourage shortcut learning between the auxiliary data and labels.