 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Contact Physiological Monitoring in Pediatric Intensive Care Units via Adaptive Masking and Self-Supervised Learning
Feb 17, 2026Continuous monitoring of vital signs in Pediatric Intensive Care Units (PICUs) is essential for early detection of clinical deterioration and effective clinical decision-making. However, contact-based sensors such as pulse oximeters may cause skin irritation, increase infection risk, and lead to patient discomfort. Remote photoplethysmography (rPPG) offers a contactless alternative to monitor heart rate using facial video, but remains underutilized in PICUs due to motion artifacts, occlusions, variable lighting, and domain shifts between laboratory and clinical data. We introduce a self-supervised pretraining framework for rPPG estimation in the PICU setting, based on a progressive curriculum strategy. The approach leverages the VisionMamba architecture and integrates an adaptive masking mechanism, where a lightweight Mamba-based controller assigns spatiotemporal importance scores to guide probabilistic patch sampling. This strategy dynamically increases reconstruction difficulty while preserving physiological relevance. To address the lack of labeled clinical data, we adopt a teacher-student distillation setup. A supervised expert model, trained on public datasets, provides latent physiological guidance to the student. The curriculum progresses through three stages: clean public videos, synthetic occlusion scenarios, and unlabeled videos from 500 pediatric patients. Our framework achieves a 42% reduction in mean absolute error relative to standard masked autoencoders and outperforms PhysFormer by 31%, reaching a final MAE of 3.2 bpm. Without explicit region-of-interest extraction, the model consistently attends to pulse-rich areas and demonstrates robustness under clinical occlusions and noise.
Development and Comparative Analysis of Machine Learning Models for Hypoxemia Severity Triage in CBRNE Emergency Scenarios Using Physiological and Demographic Data from Medical-Grade Devices
Oct 30, 2024



This paper presents the development of machine learning (ML) models to predict hypoxemia severity during emergency triage, especially in Chemical, Biological, Radiological, Nuclear, and Explosive (CBRNE) events, using physiological data from medical-grade sensors. Gradient Boosting Models (XGBoost, LightGBM, CatBoost) and sequential models (LSTM, GRU) were trained on physiological and demographic data from the MIMIC-III and IV datasets. A robust preprocessing pipeline addressed missing data, class imbalances, and incorporated synthetic data flagged with masks. Gradient Boosting Models (GBMs) outperformed sequential models in terms of training speed, interpretability, and reliability, making them well-suited for real-time decision-making. While their performance was comparable to that of sequential models, the GBMs used score features from six physiological variables derived from the enhanced National Early Warning Score (NEWS) 2, which we termed NEWS2+. This approach significantly improved prediction accuracy. While sequential models handled temporal data well, their performance gains did not justify the higher computational cost. A 5-minute prediction window was chosen for timely intervention, with minute-level interpolations standardizing the data. Feature importance analysis highlighted the significant role of mask and score features in enhancing both transparency and performance. Temporal dependencies proved to be less critical, as Gradient Boosting Models were able to capture key patterns effectively without relying on them. This study highlights ML's potential to improve triage and reduce alarm fatigue. Future work will integrate data from multiple hospitals to enhance model generalizability across clinical settings.
Empowering Clinicians with Medical Decision Transformers: A Framework for Sepsis Treatment
Jul 28, 2024Offline reinforcement learning has shown promise for solving tasks in safety-critical settings, such as clinical decision support. Its application, however, has been limited by the lack of interpretability and interactivity for clinicians. To address these challenges, we propose the medical decision transformer (MeDT), a novel and versatile framework based on the goal-conditioned reinforcement learning paradigm for sepsis treatment recommendation. MeDT uses the decision transformer architecture to learn a policy for drug dosage recommendation. During offline training, MeDT utilizes collected treatment trajectories to predict administered treatments for each time step, incorporating known treatment outcomes, target acuity scores, past treatment decisions, and current and past medical states. This analysis enables MeDT to capture complex dependencies among a patient's medical history, treatment decisions, outcomes, and short-term effects on stability. Our proposed conditioning uses acuity scores to address sparse reward issues and to facilitate clinician-model interactions, enhancing decision-making. Following training, MeDT can generate tailored treatment recommendations by conditioning on the desired positive outcome (survival) and user-specified short-term stability improvements. We carry out rigorous experiments on data from the MIMIC-III dataset and use off-policy evaluation to demonstrate that MeDT recommends interventions that outperform or are competitive with existing offline reinforcement learning methods while enabling a more interpretable, personalized and clinician-directed approach.
SwinFuSR: an image fusion-inspired model for RGB-guided thermal image super-resolution
Apr 22, 2024Thermal imaging plays a crucial role in various applications, but the inherent low resolution of commonly available infrared (IR) cameras limits its effectiveness. Conventional super-resolution (SR) methods often struggle with thermal images due to their lack of high-frequency details. Guided SR leverages information from a high-resolution image, typically in the visible spectrum, to enhance the reconstruction of a high-res IR image from the low-res input. Inspired by SwinFusion, we propose SwinFuSR, a guided SR architecture based on Swin transformers. In real world scenarios, however, the guiding modality (e.g. RBG image) may be missing, so we propose a training method that improves the robustness of the model in this case. Our method has few parameters and outperforms state of the art models in terms of Peak Signal to Noise Ratio (PSNR) and Structural SIMilarity (SSIM). In Track 2 of the PBVS 2024 Thermal Image Super-Resolution Challenge, it achieves 3rd place in the PSNR metric. Our code and pretained weights are available at https://github.com/VisionICLab/SwinFuSR.
Label Propagation Techniques for Artifact Detection in Imbalanced Classes using Photoplethysmogram Signals
Aug 16, 2023Photoplethysmogram (PPG) signals are widely used in healthcare for monitoring vital signs, but they are susceptible to motion artifacts that can lead to inaccurate interpretations. In this study, the use of label propagation techniques to propagate labels among PPG samples is explored, particularly in imbalanced class scenarios where clean PPG samples are significantly outnumbered by artifact-contaminated samples. With a precision of 91%, a recall of 90% and an F1 score of 90% for the class without artifacts, the results demonstrate its effectiveness in labeling a medical dataset, even when clean samples are rare. For the classification of artifacts our study compares supervised classifiers such as conventional classifiers and neural networks (MLP, Transformers, FCN) with the semi-supervised label propagation algorithm. With a precision of 89%, a recall of 95% and an F1 score of 92%, the KNN supervised model gives good results, but the semi-supervised algorithm performs better in detecting artifacts. The findings suggest that the semi-supervised algorithm label propagation hold promise for artifact detection in PPG signals, which can enhance the reliability of PPG-based health monitoring systems in real-world applications.
A Small-Scale Switch Transformer and NLP-based Model for Clinical Narratives Classification
Mar 22, 2023



In recent years, Transformer-based models such as the Switch Transformer have achieved remarkable results in natural language processing tasks. However, these models are often too complex and require extensive pre-training, which limits their effectiveness for small clinical text classification tasks with limited data. In this study, we propose a simplified Switch Transformer framework and train it from scratch on a small French clinical text classification dataset at CHU Sainte-Justine hospital. Our results demonstrate that the simplified small-scale Transformer models outperform pre-trained BERT-based models, including DistillBERT, CamemBERT, FlauBERT, and FrALBERT. Additionally, using a mixture of expert mechanisms from the Switch Transformer helps capture diverse patterns; hence, the proposed approach achieves better results than a conventional Transformer with the self-attention mechanism. Finally, our proposed framework achieves an accuracy of 87\%, precision at 87\%, and recall at 85\%, compared to the third-best pre-trained BERT-based model, FlauBERT, which achieved an accuracy of 84\%, precision at 84\%, and recall at 84\%. However, Switch Transformers have limitations, including a generalization gap and sharp minima. We compare it with a multi-layer perceptron neural network for small French clinical narratives classification and show that the latter outperforms all other models.
Adaptation of Autoencoder for Sparsity Reduction From Clinical Notes Representation Learning
Sep 26, 2022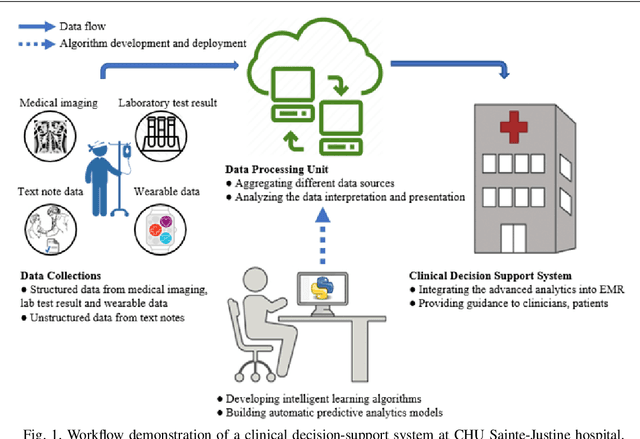
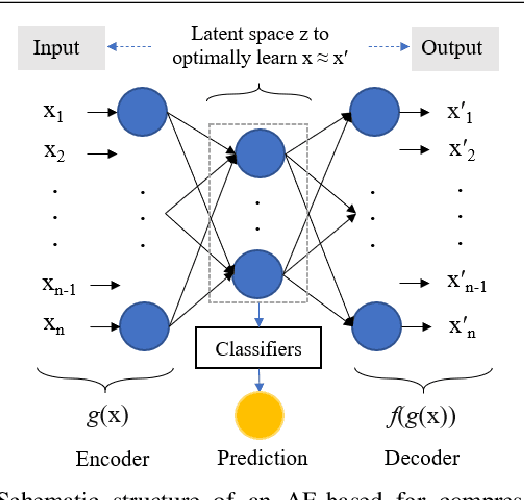
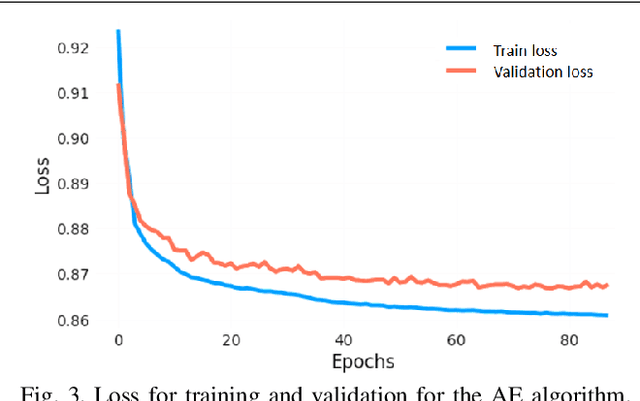
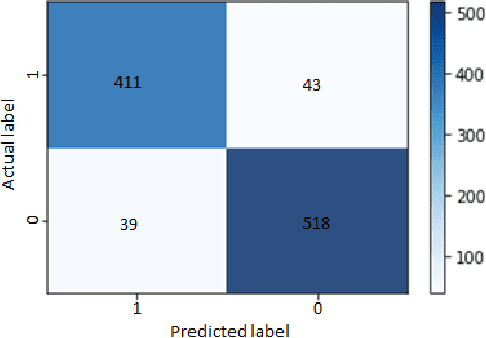
When dealing with clinical text classification on a small dataset recent studies have confirmed that a well-tuned multilayer perceptron outperforms other generative classifiers, including deep learning ones. To increase the performance of the neural network classifier, feature selection for the learning representation can effectively be used. However, most feature selection methods only estimate the degree of linear dependency between variables and select the best features based on univariate statistical tests. Furthermore, the sparsity of the feature space involved in the learning representation is ignored. Goal: Our aim is therefore to access an alternative approach to tackle the sparsity by compressing the clinical representation feature space, where limited French clinical notes can also be dealt with effectively. Methods: This study proposed an autoencoder learning algorithm to take advantage of sparsity reduction in clinical note representation. The motivation was to determine how to compress sparse, high-dimensional data by reducing the dimension of the clinical note representation feature space. The classification performance of the classifiers was then evaluated in the trained and compressed feature space. Results: The proposed approach provided overall performance gains of up to 3% for each evaluation. Finally, the classifier achieved a 92% accuracy, 91% recall, 91% precision, and 91% f1-score in detecting the patient's condition. Furthermore, the compression working mechanism and the autoencoder prediction process were demonstrated by applying the theoretic information bottleneck framework.
Detecting of a Patient's Condition From Clinical Narratives Using Natural Language Representation
Apr 19, 2021
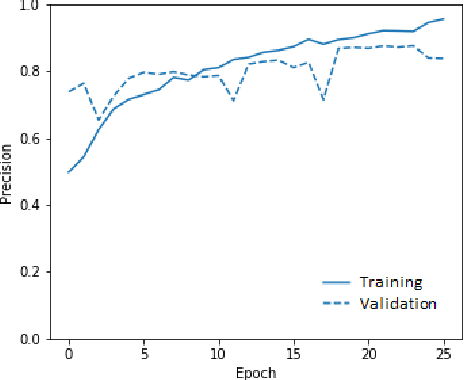
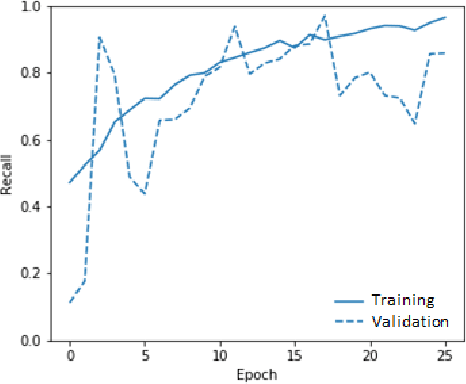
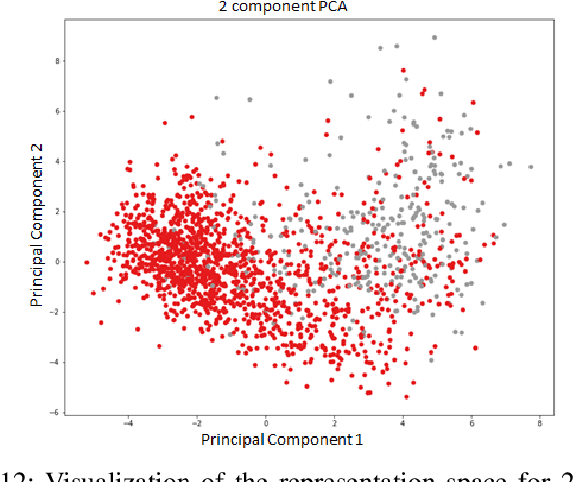
This paper proposes a joint clinical natural language representation learning and supervised classification framework based on machine learning for detecting concept labels in clinical narratives at CHU Sainte Justine Hospital (CHUSJ). The novel framework jointly discovers distributional syntactic and latent semantic (representation learning) from contextual clinical narrative inputs and, then, learns the knowledge representation for labeling in the contextual output (supervised classification). First, for having an effective representation learning approach with a small data set, mixing of numeric values and texts. Four different methods are applied to capture the numerical vital sign values. Then, different representation learning approaches are using to discover the rich structure from clinical narrative data. Second, for an automatic encounter with disease prediction, in this case, cardiac failure. The binary classifiers are iteratively trained to learn the knowledge representation of processed data in the preceding steps. The multilayer perceptron neural network outperforms other discriminative and generative classifiers. Consequently, the proposed framework yields an overall classification performance with accuracy, recall, and precision of 89 % and 88 %, 89 %, respectively. Furthermore, a generative autoencoder (AE) learning algorithm is then proposed to leverage the sparsity reduction. Affirmatively, AE algorithm is overperforming other sparsity reduction techniques. And, the classifier performances can successfully achieve up to 91 %, 91%, and 91%, respectively, for accuracy, recall, and precision.
Machine Learning Based on Natural Language Processing to Detect Cardiac Failure in Clinical Narratives
Apr 08, 2021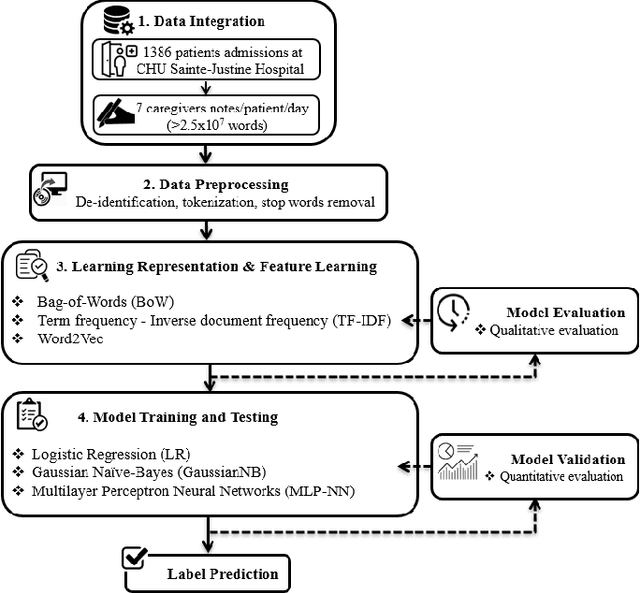
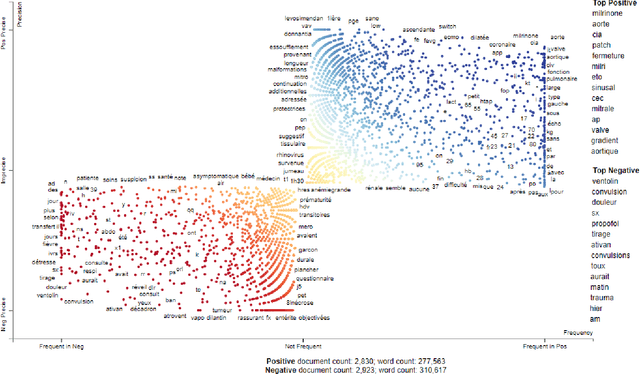

The purpose of the study presented herein is to develop a machine learning algorithm based on natural language processing that automatically detects whether a patient has a cardiac failure or a healthy condition by using physician notes in Research Data Warehouse at CHU Sainte Justine Hospital. First, a word representation learning technique was employed by using bag-of-word (BoW), term frequency inverse document frequency (TFIDF), and neural word embeddings (word2vec). Each representation technique aims to retain the words semantic and syntactic analysis in critical care data. It helps to enrich the mutual information for the word representation and leads to an advantage for further appropriate analysis steps. Second, a machine learning classifier was used to detect the patients condition for either cardiac failure or stable patient through the created word representation vector space from the previous step. This machine learning approach is based on a supervised binary classification algorithm, including logistic regression (LR), Gaussian Naive-Bayes (GaussianNB), and multilayer perceptron neural network (MLPNN). Technically, it mainly optimizes the empirical loss during training the classifiers. As a result, an automatic learning algorithm would be accomplished to draw a high classification performance, including accuracy (acc), precision (pre), recall (rec), and F1 score (f1). The results show that the combination of TFIDF and MLPNN always outperformed other combinations with all overall performance. In the case without any feature selection, the proposed framework yielded an overall classification performance with acc, pre, rec, and f1 of 84% and 82%, 85%, and 83%, respectively. Significantly, if the feature selection was well applied, the overall performance would finally improve up to 4% for each evaluation.