 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time, accurate, and open source upper-limb musculoskeletal analysis using a single RGBD camera
Jun 14, 2024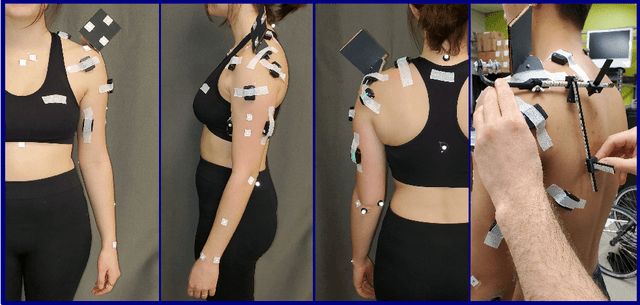
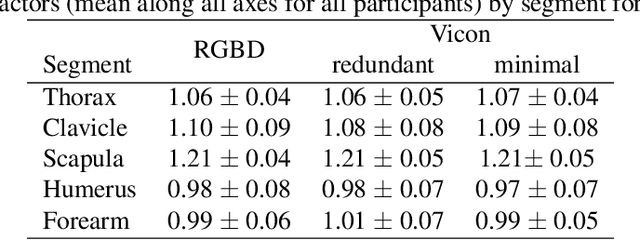
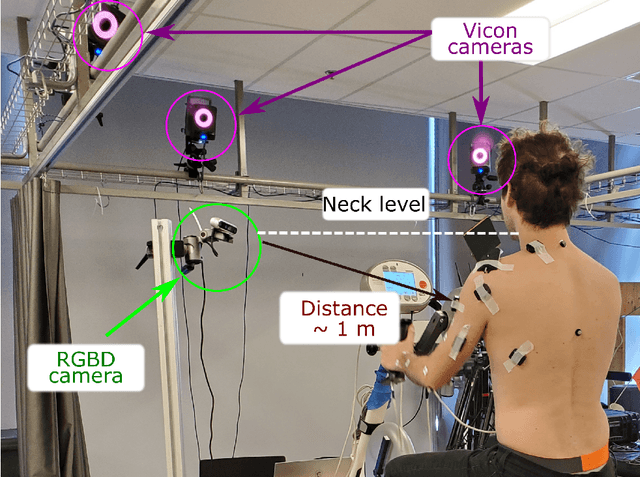
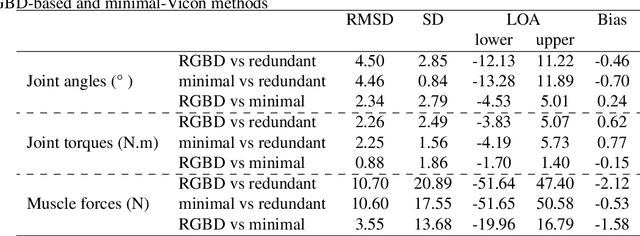
Biomechanical biofeedback may enhance rehabilitation and provide clinicians with more objective task evaluation. These feedbacks often rely on expensive motion capture systems, which restricts their widespread use, leading to the development of computer vision-based methods. These methods are subject to large joint angle errors, considering the upper limb, and exclude the scapula and clavicle motion in the analysis. Our open-source approach offers a user-friendly solution for high-fidelity upper-limb kinematics using a single low-cost RGBD camera and includes semi-automatic skin marker labeling. Real-time biomechanical analysis, ranging from kinematics to muscle force estimation, was conducted on eight participants performing a hand-cycling motion to demonstrate the applicability of our approach on the upper limb. Markers were recorded by the RGBD camera and an optoelectronic camera system, considered as a reference. Muscle activity and external load were recorded using eight EMG and instrumented hand pedals, respectively. Bland-Altman analysis revealed significant agreements in the 3D markers' positions between the two motion capture methods, with errors averaging 3.3$\pm$3.9 mm. For the biomechanical analysis, the level of agreement was sensitive to whether the same marker set was used. For example, joint angle differences averaging 2.3$\pm$2.8{\deg} when using the same marker set, compared to 4.5$\pm$2.9{\deg} otherwise. Biofeedback from the RGBD camera was provided at 63 Hz. Our study introduces a novel method for using an RGBD camera as a low-cost motion capture solution, emphasizing its potential for accurate kinematic reconstruction and comprehensive upper-limb biomechanical studies.
SwinFuSR: an image fusion-inspired model for RGB-guided thermal image super-resolution
Apr 22, 2024Thermal imaging plays a crucial role in various applications, but the inherent low resolution of commonly available infrared (IR) cameras limits its effectiveness. Conventional super-resolution (SR) methods often struggle with thermal images due to their lack of high-frequency details. Guided SR leverages information from a high-resolution image, typically in the visible spectrum, to enhance the reconstruction of a high-res IR image from the low-res input. Inspired by SwinFusion, we propose SwinFuSR, a guided SR architecture based on Swin transformers. In real world scenarios, however, the guiding modality (e.g. RBG image) may be missing, so we propose a training method that improves the robustness of the model in this case. Our method has few parameters and outperforms state of the art models in terms of Peak Signal to Noise Ratio (PSNR) and Structural SIMilarity (SSIM). In Track 2 of the PBVS 2024 Thermal Image Super-Resolution Challenge, it achieves 3rd place in the PSNR metric. Our code and pretained weights are available at https://github.com/VisionICLab/SwinFuSR.
Predicting Next Local Appearance for Video Anomaly Detection
Jun 10, 2021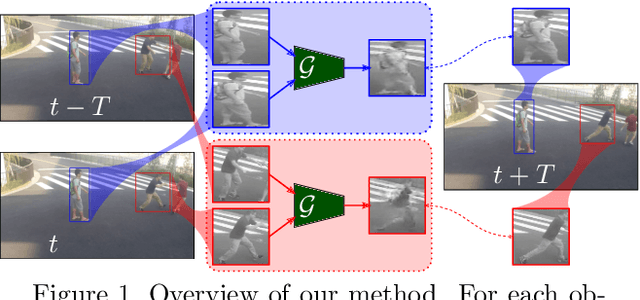
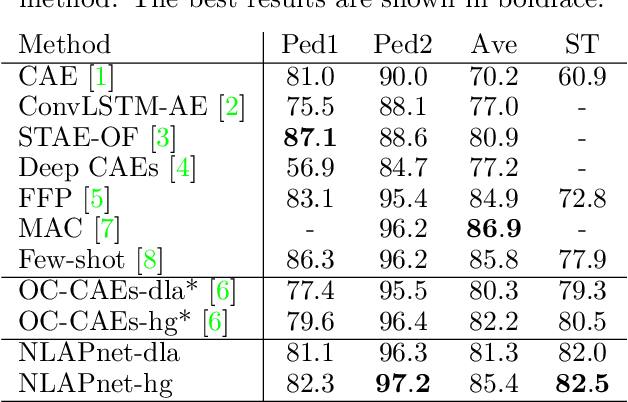
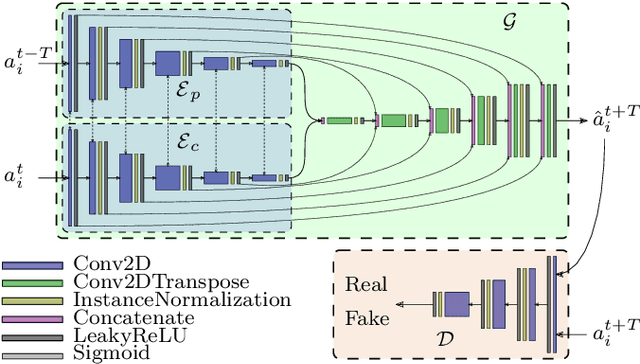
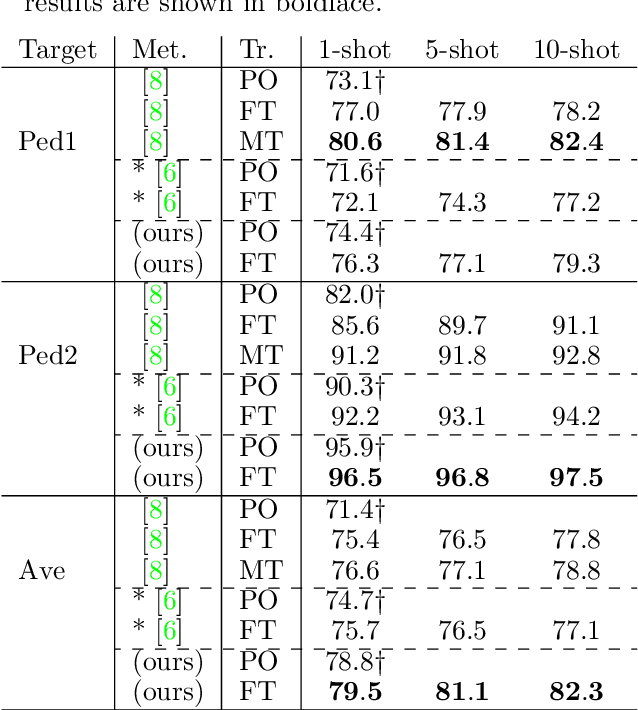
We present a local anomaly detection method in videos. As opposed to most existing methods that are computationally expensive and are not very generalizable across different video scenes, we propose an adversarial framework that learns the temporal local appearance variations by predicting the appearance of a normally behaving object in the next frame of a scene by only relying on its current and past appearances. In the presence of an abnormally behaving object, the reconstruction error between the real and the predicted next appearance of that object indicates the likelihood of an anomaly. Our method is competitive with the existing state-of-the-art while being significantly faster for both training and inference and being better at generalizing to unseen video scenes.
Local Anomaly Detection in Videos using Object-Centric Adversarial Learning
Nov 13, 2020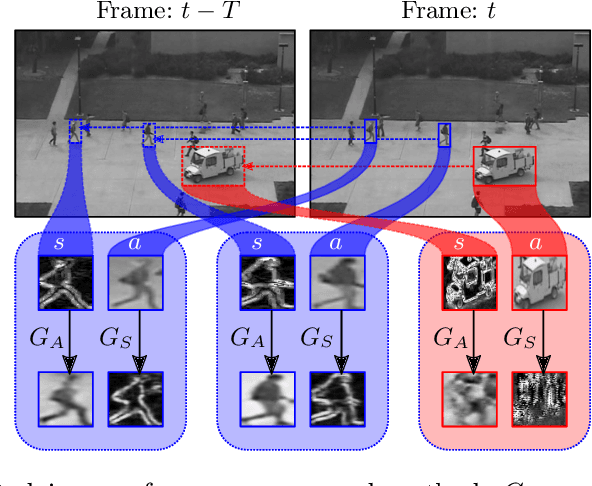
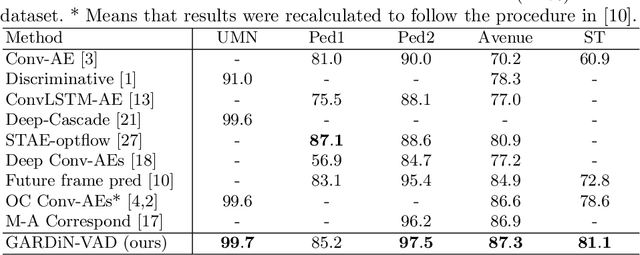
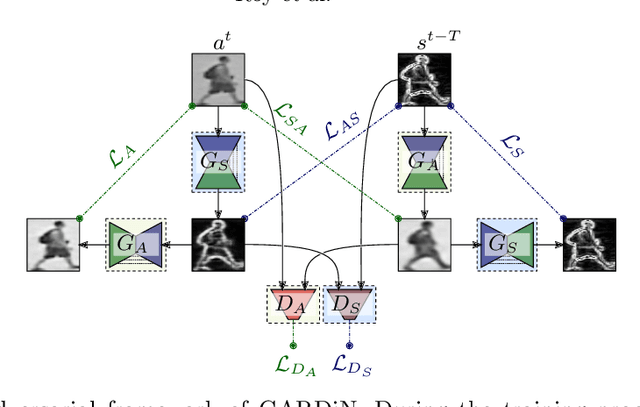
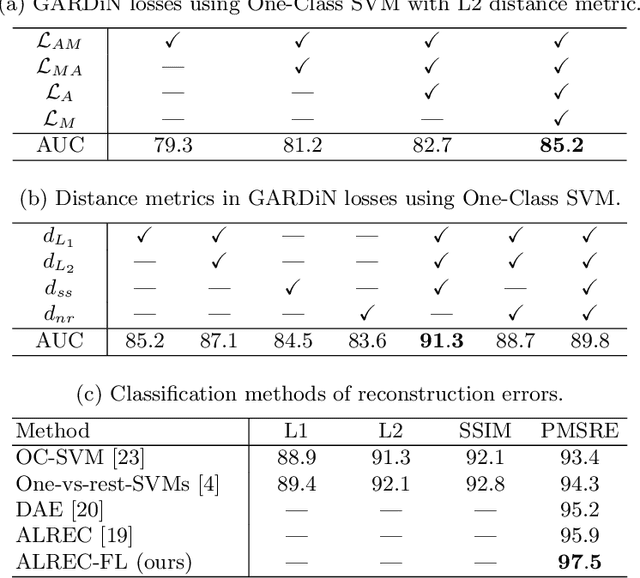
We propose a novel unsupervised approach based on a two-stage object-centric adversarial framework that only needs object regions for detecting frame-level local anomalies in videos. The first stage consists in learning the correspondence between the current appearance and past gradient images of objects in scenes deemed normal, allowing us to either generate the past gradient from current appearance or the reverse. The second stage extracts the partial reconstruction errors between real and generated images (appearance and past gradient) with normal object behaviour, and trains a discriminator in an adversarial fashion. In inference mode, we employ the trained image generators with the adversarially learned binary classifier for outputting region-level anomaly detection scores. We tested our method on four public benchmarks, UMN, UCSD, Avenue and ShanghaiTech and our proposed object-centric adversarial approach yields competitive or even superior results compared to state-of-the-art methods.