 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation of Autoencoder for Sparsity Reduction From Clinical Notes Representation Learning
Sep 26, 2022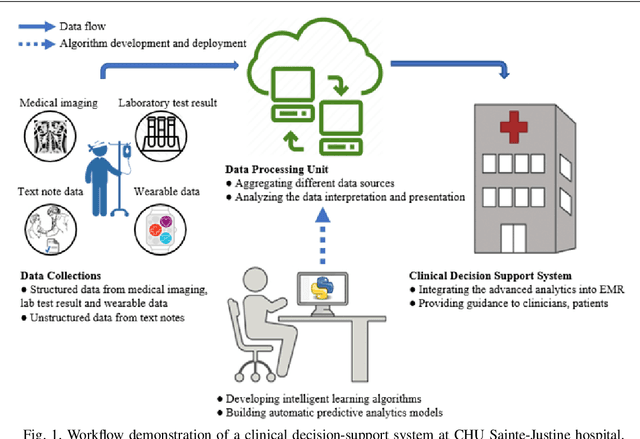
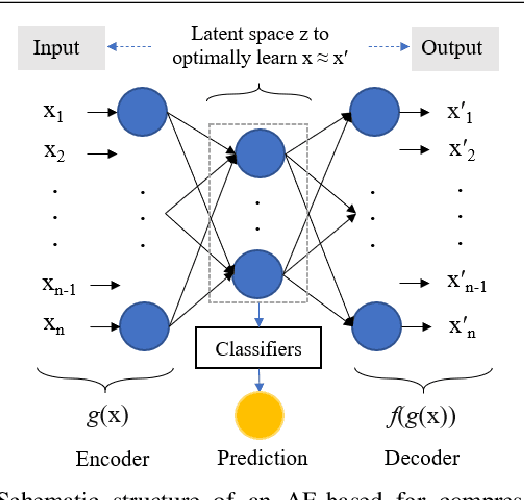
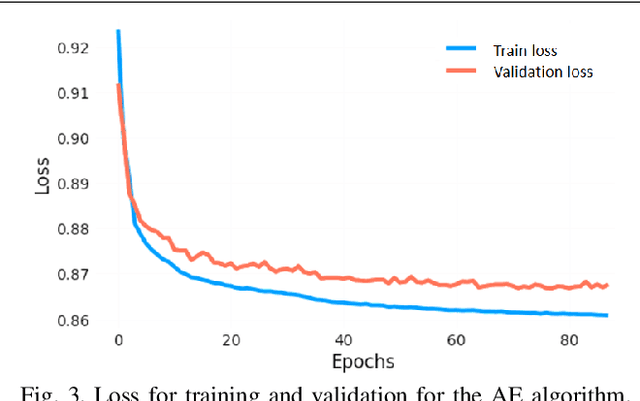
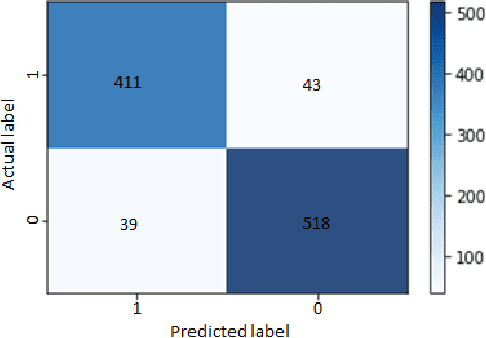
When dealing with clinical text classification on a small dataset recent studies have confirmed that a well-tuned multilayer perceptron outperforms other generative classifiers, including deep learning ones. To increase the performance of the neural network classifier, feature selection for the learning representation can effectively be used. However, most feature selection methods only estimate the degree of linear dependency between variables and select the best features based on univariate statistical tests. Furthermore, the sparsity of the feature space involved in the learning representation is ignored. Goal: Our aim is therefore to access an alternative approach to tackle the sparsity by compressing the clinical representation feature space, where limited French clinical notes can also be dealt with effectively. Methods: This study proposed an autoencoder learning algorithm to take advantage of sparsity reduction in clinical note representation. The motivation was to determine how to compress sparse, high-dimensional data by reducing the dimension of the clinical note representation feature space. The classification performance of the classifiers was then evaluated in the trained and compressed feature space. Results: The proposed approach provided overall performance gains of up to 3% for each evaluation. Finally, the classifier achieved a 92% accuracy, 91% recall, 91% precision, and 91% f1-score in detecting the patient's condition. Furthermore, the compression working mechanism and the autoencoder prediction process were demonstrated by applying the theoretic information bottleneck framework.
Detecting of a Patient's Condition From Clinical Narratives Using Natural Language Representation
Apr 19, 2021
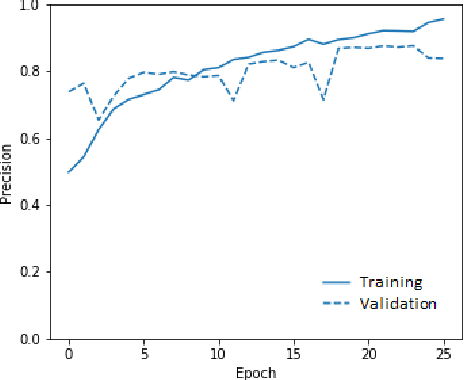
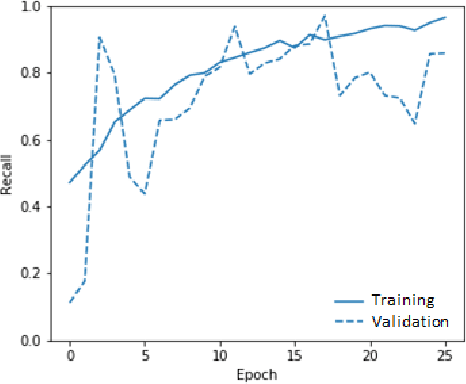
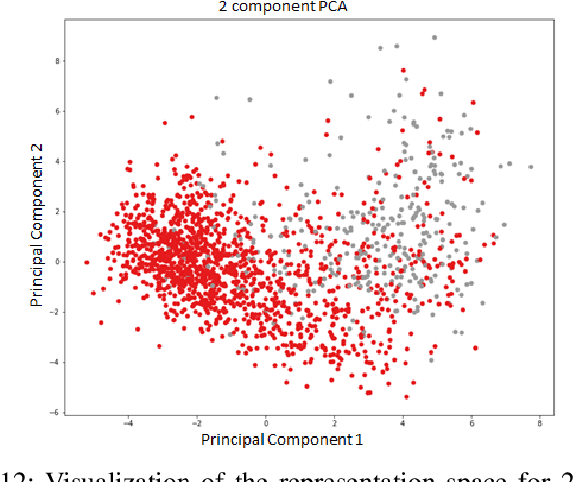
This paper proposes a joint clinical natural language representation learning and supervised classification framework based on machine learning for detecting concept labels in clinical narratives at CHU Sainte Justine Hospital (CHUSJ). The novel framework jointly discovers distributional syntactic and latent semantic (representation learning) from contextual clinical narrative inputs and, then, learns the knowledge representation for labeling in the contextual output (supervised classification). First, for having an effective representation learning approach with a small data set, mixing of numeric values and texts. Four different methods are applied to capture the numerical vital sign values. Then, different representation learning approaches are using to discover the rich structure from clinical narrative data. Second, for an automatic encounter with disease prediction, in this case, cardiac failure. The binary classifiers are iteratively trained to learn the knowledge representation of processed data in the preceding steps. The multilayer perceptron neural network outperforms other discriminative and generative classifiers. Consequently, the proposed framework yields an overall classification performance with accuracy, recall, and precision of 89 % and 88 %, 89 %, respectively. Furthermore, a generative autoencoder (AE) learning algorithm is then proposed to leverage the sparsity reduction. Affirmatively, AE algorithm is overperforming other sparsity reduction techniques. And, the classifier performances can successfully achieve up to 91 %, 91%, and 91%, respectively, for accuracy, recall, and precision.
Machine Learning Based on Natural Language Processing to Detect Cardiac Failure in Clinical Narratives
Apr 08, 2021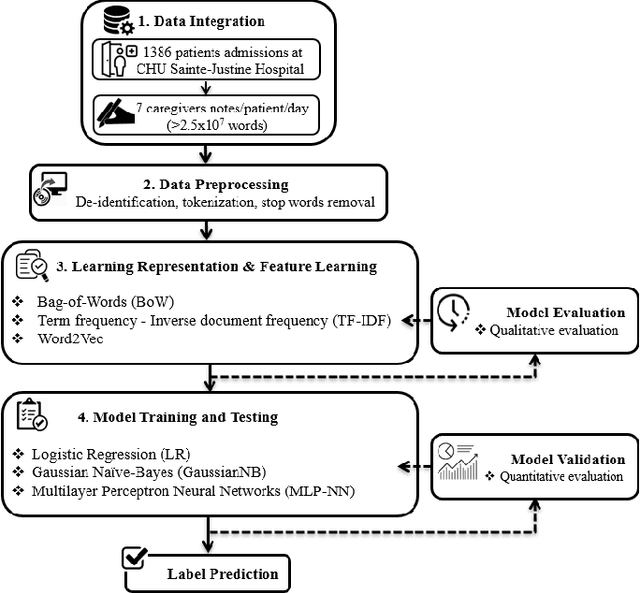
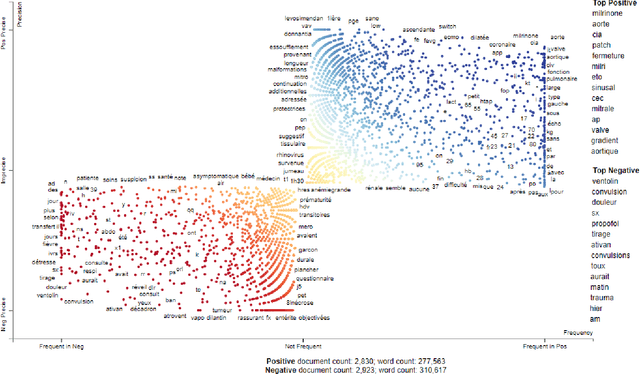

The purpose of the study presented herein is to develop a machine learning algorithm based on natural language processing that automatically detects whether a patient has a cardiac failure or a healthy condition by using physician notes in Research Data Warehouse at CHU Sainte Justine Hospital. First, a word representation learning technique was employed by using bag-of-word (BoW), term frequency inverse document frequency (TFIDF), and neural word embeddings (word2vec). Each representation technique aims to retain the words semantic and syntactic analysis in critical care data. It helps to enrich the mutual information for the word representation and leads to an advantage for further appropriate analysis steps. Second, a machine learning classifier was used to detect the patients condition for either cardiac failure or stable patient through the created word representation vector space from the previous step. This machine learning approach is based on a supervised binary classification algorithm, including logistic regression (LR), Gaussian Naive-Bayes (GaussianNB), and multilayer perceptron neural network (MLPNN). Technically, it mainly optimizes the empirical loss during training the classifiers. As a result, an automatic learning algorithm would be accomplished to draw a high classification performance, including accuracy (acc), precision (pre), recall (rec), and F1 score (f1). The results show that the combination of TFIDF and MLPNN always outperformed other combinations with all overall performance. In the case without any feature selection, the proposed framework yielded an overall classification performance with acc, pre, rec, and f1 of 84% and 82%, 85%, and 83%, respectively. Significantly, if the feature selection was well applied, the overall performance would finally improve up to 4% for each evaluation.