 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRUGAL: Unlocking SSL for Software Analytics
Paper and Code
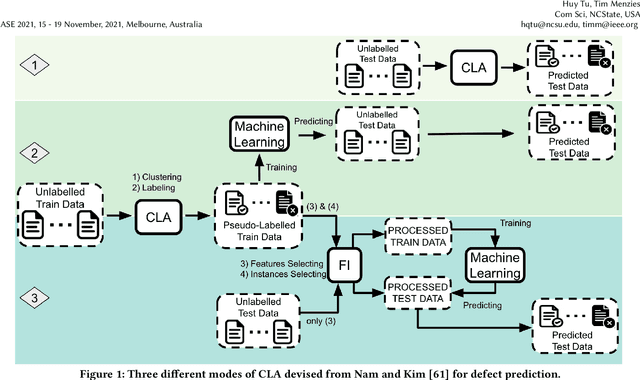
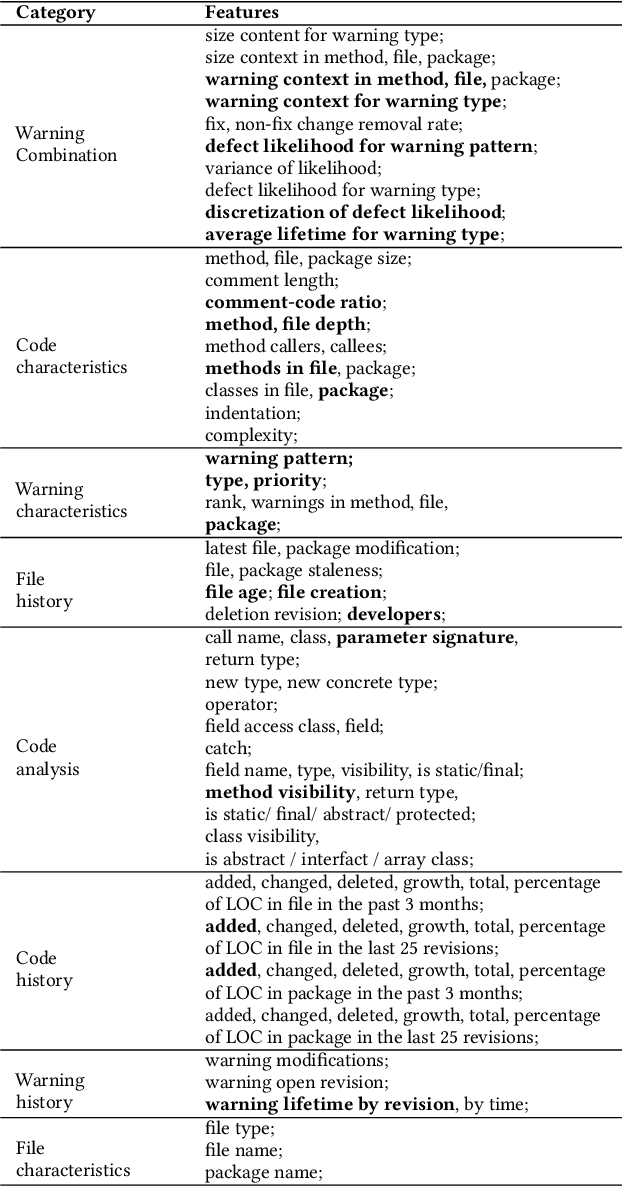


Standard software analytics often involves having a large amount of data with labels in order to commission models with acceptable performance. However, prior work has shown that such requirements can be expensive, taking several weeks to label thousands of commits, and not always available when traversing new research problems and domains. Unsupervised Learning is a promising direction to learn hidden patterns within unlabelled data, which has only been extensively studied in defect prediction. Nevertheless, unsupervised learning can be ineffective by itself and has not been explored in other domains (e.g., static analysis and issue close time). Motivated by this literature gap and technical limitations, we present FRUGAL, a tuned semi-supervised method that builds on a simple optimization scheme that does not require sophisticated (e.g., deep learners) and expensive (e.g., 100% manually labelled data) methods. FRUGAL optimizes the unsupervised learner's configurations (via a simple grid search) while validating our design decision of labelling just 2.5% of the data before prediction. As shown by the experiments of this paper FRUGAL outperforms the state-of-the-art adoptable static code warning recognizer and issue closed time predictor, while reducing the cost of labelling by a factor of 40 (from 100% to 2.5%). Hence we assert that FRUGAL can save considerable effort in data labelling especially in validating prior work or researching new problems. Based on this work, we suggest that proponents of complex and expensive methods should always baseline such methods against simpler and cheaper alternatives. For instance, a semi-supervised learner like FRUGAL can serve as a baseline to the state-of-the-art software analytics.