 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Trial Begin: A Mock-Court Approach to Vulnerability Detection using LLM-Based Agents
May 16, 2025



Detecting vulnerabilities in source code remains a critical yet challenging task, especially when benign and vulnerable functions share significant similarities. In this work, we introduce VulTrial, a courtroom-inspired multi-agent framework designed to enhance automated vulnerability detection. It employs four role-specific agents, which are security researcher, code author, moderator, and review board. Through extensive experiments using GPT-3.5 and GPT-4o we demonstrate that Vultrial outperforms single-agent and multi-agent baselines. Using GPT-4o, VulTrial improves the performance by 102.39% and 84.17% over its respective baseline. Additionally, we show that role-specific instruction tuning in multi-agent with small data (50 pair samples) improves the performance of VulTrial further by 139.89% and 118.30%. Furthermore, we analyze the impact of increasing the number of agent interactions on VulTrial's overall performance. While multi-agent setups inherently incur higher costs due to increased token usage, our findings reveal that applying VulTrial to a cost-effective model like GPT-3.5 can improve its performance by 69.89% compared to GPT-4o in a single-agent setting, at a lower overall cost.
Human-in-the-Loop Synthetic Text Data Inspection with Provenance Tracking
Apr 29, 2024
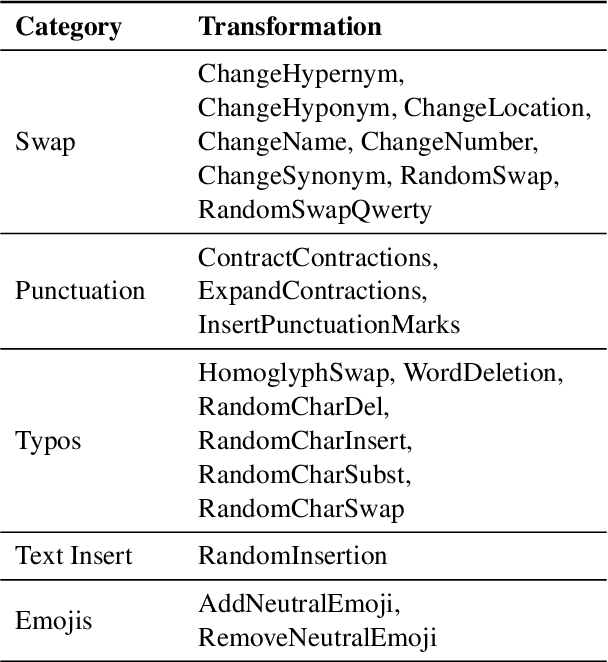
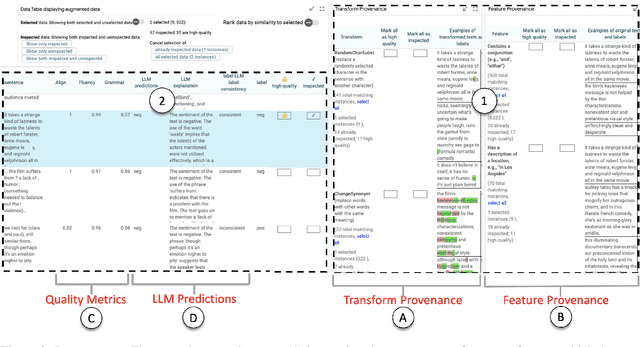
Data augmentation techniques apply transformations to existing texts to generate additional data. The transformations may produce low-quality texts, where the meaning of the text is changed and the text may even be mangled beyond human comprehension. Analyzing the synthetically generated texts and their corresponding labels is slow and demanding. To winnow out texts with incorrect labels, we develop INSPECTOR, a human-in-the-loop data inspection technique. INSPECTOR combines the strengths of provenance tracking techniques with assistive labeling. INSPECTOR allows users to group related texts by their transformation provenance, i.e., the transformations applied to the original text, or feature provenance, the linguistic features of the original text. For assistive labeling, INSPECTOR computes metrics that approximate data quality, and allows users to compare the corresponding label of each text against the predictions of a large language model. In a user study, INSPECTOR increases the number of texts with correct labels identified by 3X on a sentiment analysis task and by 4X on a hate speech detection task. The participants found grouping the synthetically generated texts by their common transformation to be the most useful technique. Surprisingly, grouping texts by common linguistic features was perceived to be unhelpful. Contrary to prior work, our study finds that no single technique obviates the need for human inspection effort. This validates the design of INSPECTOR which combines both analysis of data provenance and assistive labeling to reduce human inspection effort.
Multi-Granularity Detector for Vulnerability Fixes
May 23, 2023



With the increasing reliance on Open Source Software, users are exposed to third-party library vulnerabilities. Software Composition Analysis (SCA) tools have been created to alert users of such vulnerabilities. SCA requires the identification of vulnerability-fixing commits. Prior works have proposed methods that can automatically identify such vulnerability-fixing commits. However, identifying such commits is highly challenging, as only a very small minority of commits are vulnerability fixing. Moreover, code changes can be noisy and difficult to analyze. We observe that noise can occur at different levels of detail, making it challenging to detect vulnerability fixes accurately. To address these challenges and boost the effectiveness of prior works, we propose MiDas (Multi-Granularity Detector for Vulnerability Fixes). Unique from prior works, Midas constructs different neural networks for each level of code change granularity, corresponding to commit-level, file-level, hunk-level, and line-level, following their natural organization. It then utilizes an ensemble model that combines all base models to generate the final prediction. This design allows MiDas to better handle the noisy and highly imbalanced nature of vulnerability-fixing commit data. Additionally, to reduce the human effort required to inspect code changes, we have designed an effort-aware adjustment for Midas's outputs based on commit length. The evaluation results demonstrate that MiDas outperforms the current state-of-the-art baseline in terms of AUC by 4.9% and 13.7% on Java and Python-based datasets, respectively. Furthermore, in terms of two effort-aware metrics, EffortCost@L and Popt@L, MiDas also outperforms the state-of-the-art baseline, achieving improvements of up to 28.2% and 15.9% on Java, and 60% and 51.4% on Python, respectively.
VulCurator: A Vulnerability-Fixing Commit Detector
Sep 07, 2022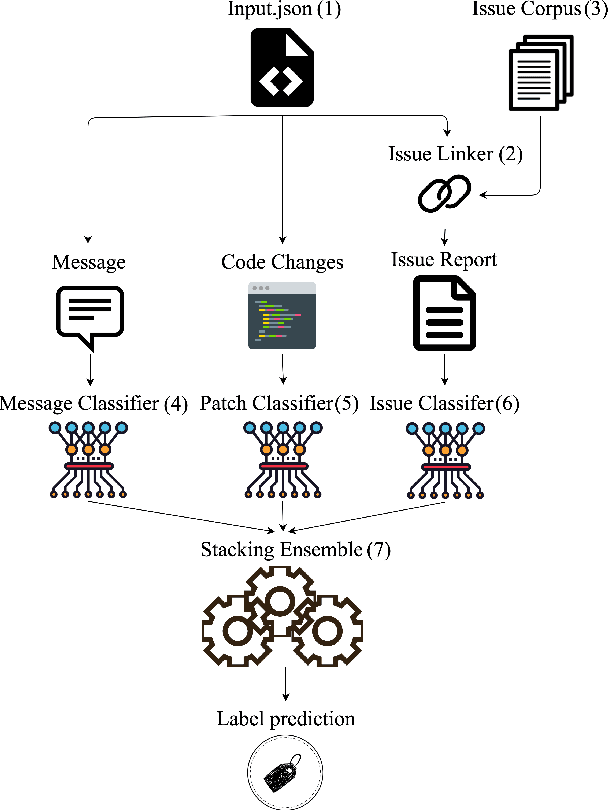

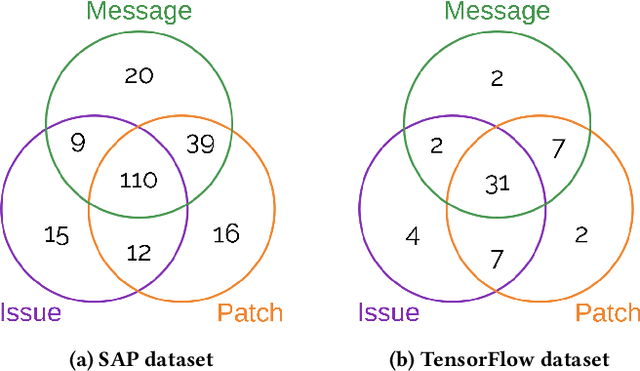

Open-source software (OSS) vulnerability management process is important nowadays, as the number of discovered OSS vulnerabilities is increasing over time. Monitoring vulnerability-fixing commits is a part of the standard process to prevent vulnerability exploitation. Manually detecting vulnerability-fixing commits is, however, time consuming due to the possibly large number of commits to review. Recently, many techniques have been proposed to automatically detect vulnerability-fixing commits using machine learning. These solutions either: (1) did not use deep learning, or (2) use deep learning on only limited sources of information. This paper proposes VulCurator, a tool that leverages deep learning on richer sources of information, including commit messages, code changes and issue reports for vulnerability-fixing commit classifica- tion. Our experimental results show that VulCurator outperforms the state-of-the-art baselines up to 16.1% in terms of F1-score. VulCurator tool is publicly available at https://github.com/ntgiang71096/VFDetector and https://zenodo.org/record/7034132#.Yw3MN-xBzDI, with a demo video at https://youtu.be/uMlFmWSJYOE.
AutoPruner: Transformer-Based Call Graph Pruning
Sep 07, 2022
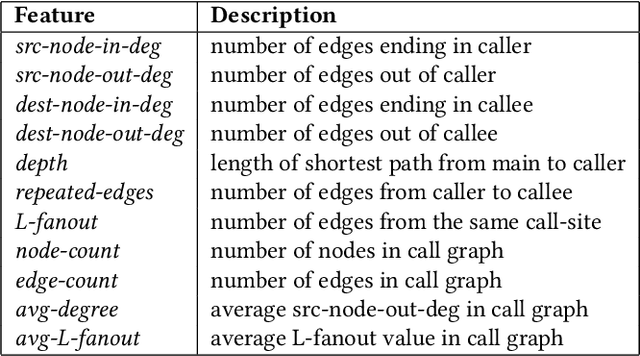
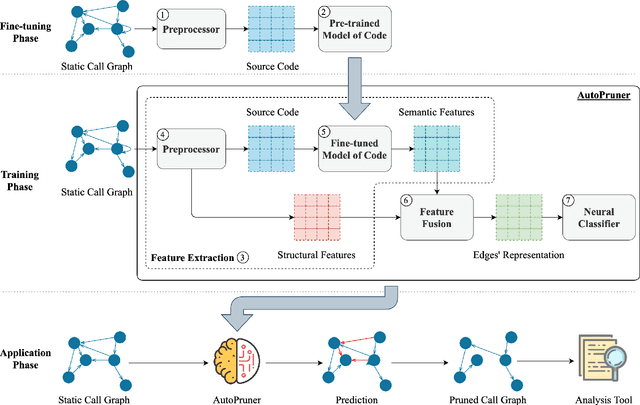

Constructing a static call graph requires trade-offs between soundness and precision. Program analysis techniques for constructing call graphs are unfortunately usually imprecise. To address this problem, researchers have recently proposed call graph pruning empowered by machine learning to post-process call graphs constructed by static analysis. A machine learning model is built to capture information from the call graph by extracting structural features for use in a random forest classifier. It then removes edges that are predicted to be false positives. Despite the improvements shown by machine learning models, they are still limited as they do not consider the source code semantics and thus often are not able to effectively distinguish true and false positives. In this paper, we present a novel call graph pruning technique, AutoPruner, for eliminating false positives in call graphs via both statistical semantic and structural analysis. Given a call graph constructed by traditional static analysis tools, AutoPruner takes a Transformer-based approach to capture the semantic relationships between the caller and callee functions associated with each edge in the call graph. To do so, AutoPruner fine-tunes a model of code that was pre-trained on a large corpus to represent source code based on descriptions of its semantics. Next, the model is used to extract semantic features from the functions related to each edge in the call graph. AutoPruner uses these semantic features together with the structural features extracted from the call graph to classify each edge via a feed-forward neural network. Our empirical evaluation on a benchmark dataset of real-world programs shows that AutoPruner outperforms the state-of-the-art baselines, improving on F-measure by up to 13% in identifying false-positive edges in a static call graph.
How to Find Actionable Static Analysis Warnings
May 21, 2022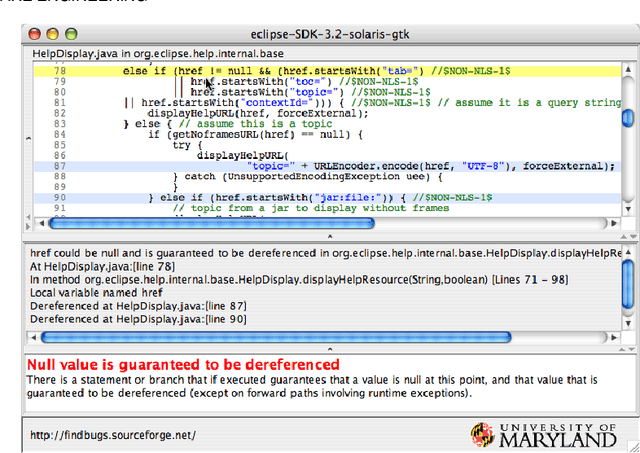

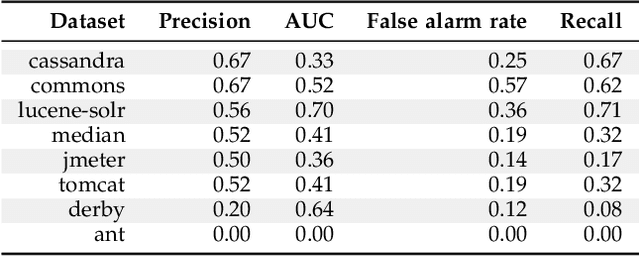
Automatically generated static code warnings suffer from a large number of false alarms. Hence, developers only take action on a small percent of those warnings. To better predict which static code warnings should not be ignored, we suggest that analysts need to look deeper into their algorithms to find choices that better improve the particulars of their specific problem. Specifically, we show here that effective predictors of such warnings can be created by methods that locally adjust the decision boundary (between actionable warnings and others). These methods yield a new high water-mark for recognizing actionable static code warnings. For eight open-source Java projects (CASSANDRA, JMETER, COMMONS, LUCENE-SOLR, ANT, TOMCAT, DERBY) we achieve perfect test results on 4/8 datasets and, overall, a median AUC (area under the true negatives, true positives curve) of 92\%.
A Comparison of Word Embeddings for English and Cross-Lingual Chinese Word Sense Disambiguation
Apr 09, 2017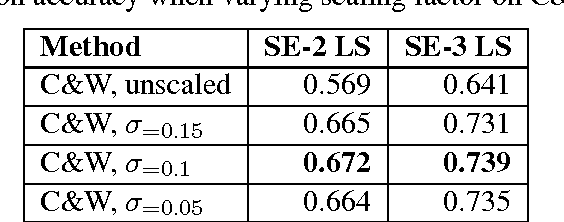
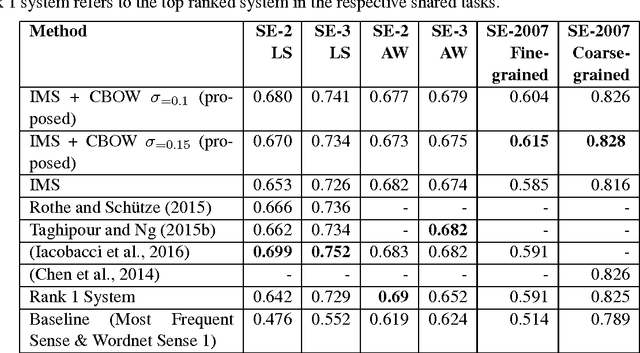
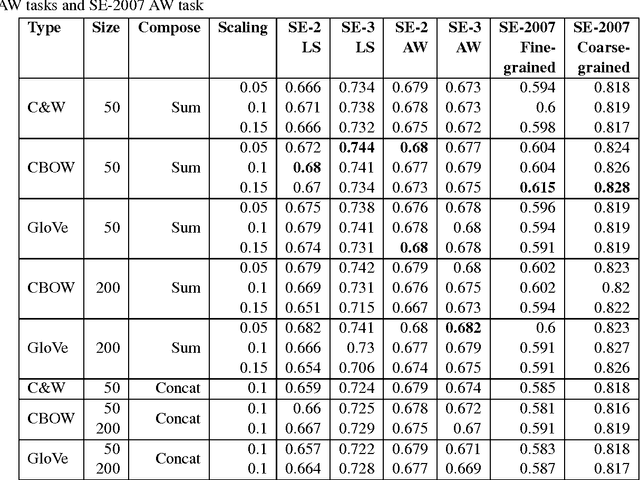
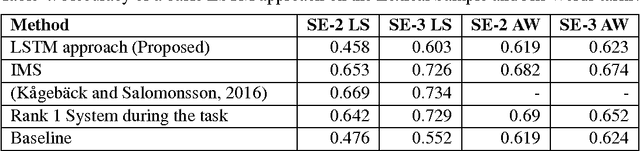
Word embeddings are now ubiquitous forms of word representation in natural language processing. There have been applications of word embeddings for monolingual word sense disambiguation (WSD) in English, but few comparisons have been done. This paper attempts to bridge that gap by examining popular embeddings for the task of monolingual English WSD. Our simplified method leads to comparable state-of-the-art performance without expensive retraining. Cross-Lingual WSD - where the word senses of a word in a source language e come from a separate target translation language f - can also assist in language learning; for example, when providing translations of target vocabulary for learners. Thus we have also applied word embeddings to the novel task of cross-lingual WSD for Chinese and provide a public dataset for further benchmarking. We have also experimented with using word embeddings for LSTM networks and found surprisingly that a basic LSTM network does not work well. We discuss the ramifications of this outcome.
* 10 pages. Appears in the Proceedings of The 3rd Workshop on Natural Language Processing Techniques for Educational Applications (NLPTEA 2016)