 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead Top News First: A Document Reordering Approach for Multi-Document News Summarization
Mar 19, 2022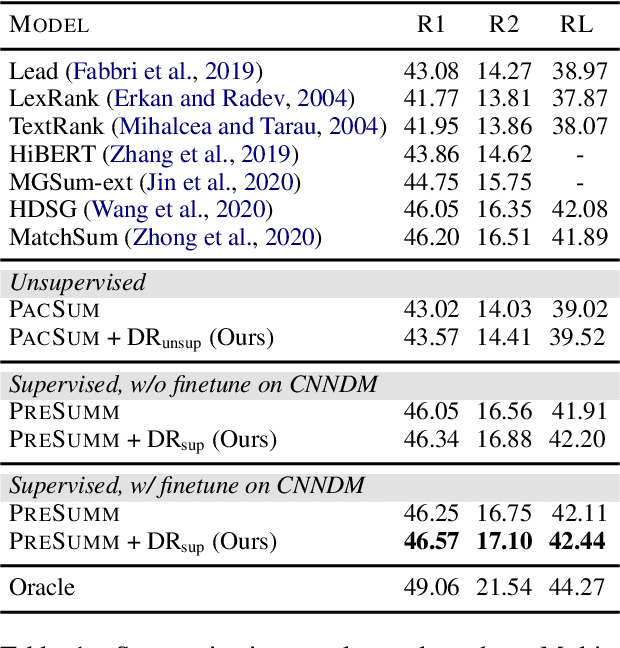
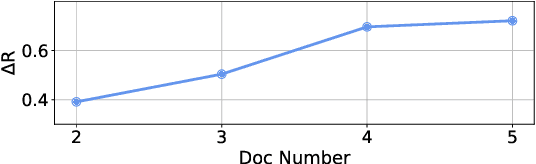


A common method for extractive multi-document news summarization is to re-formulate it as a single-document summarization problem by concatenating all documents as a single meta-document. However, this method neglects the relative importance of documents. We propose a simple approach to reorder the documents according to their relative importance before concatenating and summarizing them. The reordering makes the salient content easier to learn by the summarization model. Experiments show that our approach outperforms previous state-of-the-art methods with more complex architectures.
Event-Driven News Stream Clustering using Entity-Aware Contextual Embeddings
Jan 26, 2021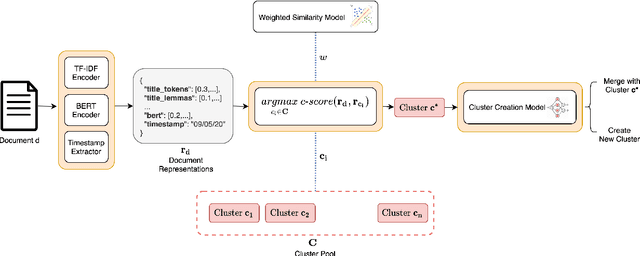
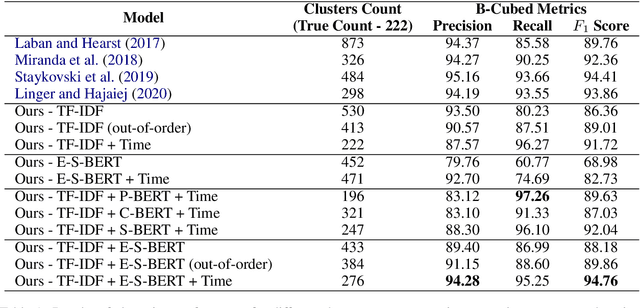
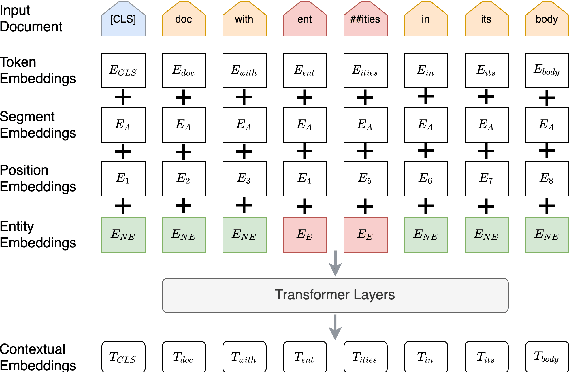
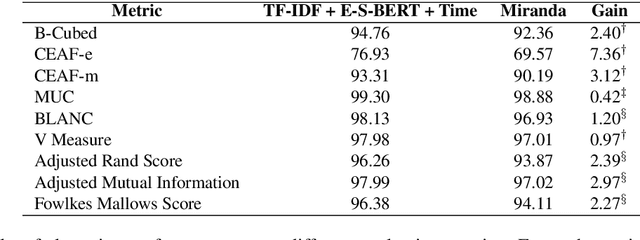
We propose a method for online news stream clustering that is a variant of the non-parametric streaming K-means algorithm. Our model uses a combination of sparse and dense document representations, aggregates document-cluster similarity along these multiple representations and makes the clustering decision using a neural classifier. The weighted document-cluster similarity model is learned using a novel adaptation of the triplet loss into a linear classification objective. We show that the use of a suitable fine-tuning objective and external knowledge in pre-trained transformer models yields significant improvements in the effectiveness of contextual embeddings for clustering. Our model achieves a new state-of-the-art on a standard stream clustering dataset of English documents.
The CL-SciSumm Shared Task 2018: Results and Key Insights
Sep 02, 2019
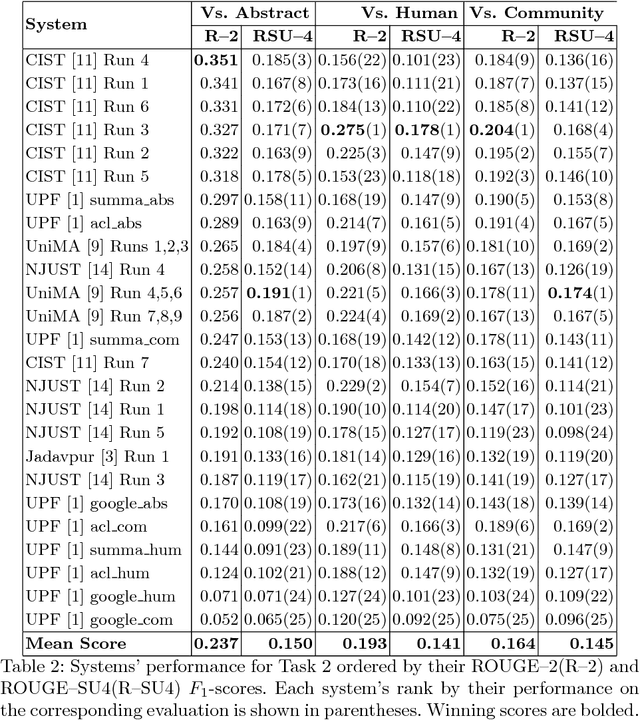

This overview describes the official results of the CL-SciSumm Shared Task 2018 -- the first medium-scale shared task on scientific document summarization in the computational linguistics (CL) domain. This year, the dataset comprised 60 annotated sets of citing and reference papers from the open access research papers in the CL domain. The Shared Task was organized as a part of the 41st Annual Conference of the Special Interest Group in Information Retrieval (SIGIR), held in Ann Arbor, USA in July 2018. We compare the participating systems in terms of two evaluation metrics. The annotated dataset and evaluation scripts can be accessed and used by the community from: \url{https://github.com/WING-NUS/scisumm-corpus}.
Overview and Results: CL-SciSumm Shared Task 2019
Jul 23, 2019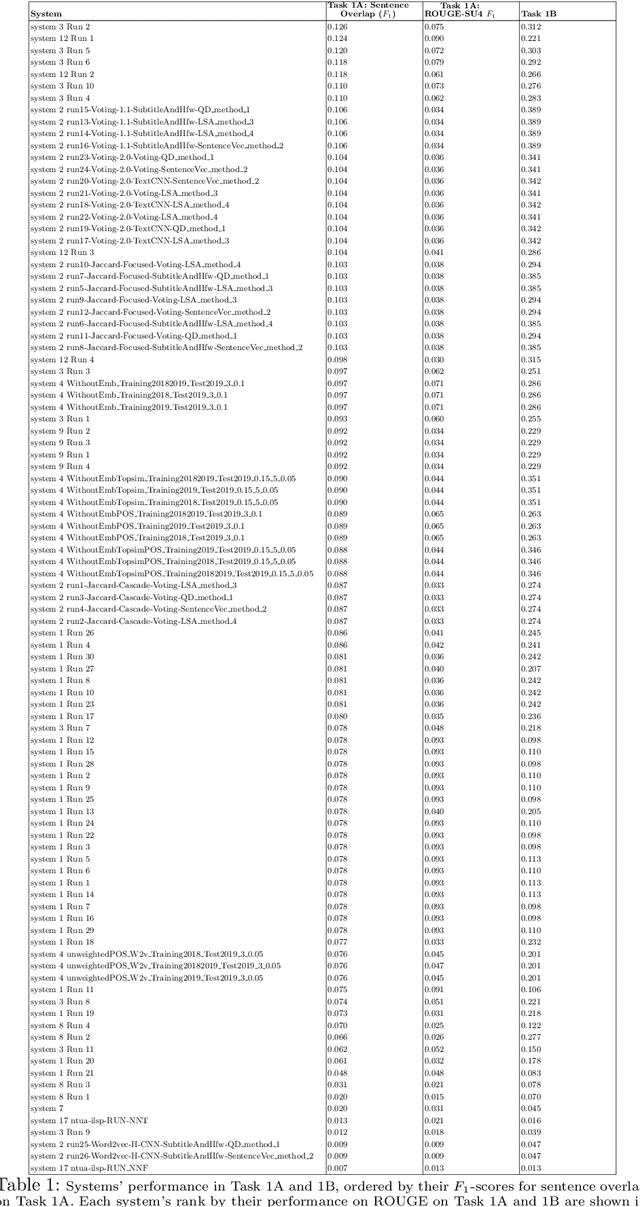
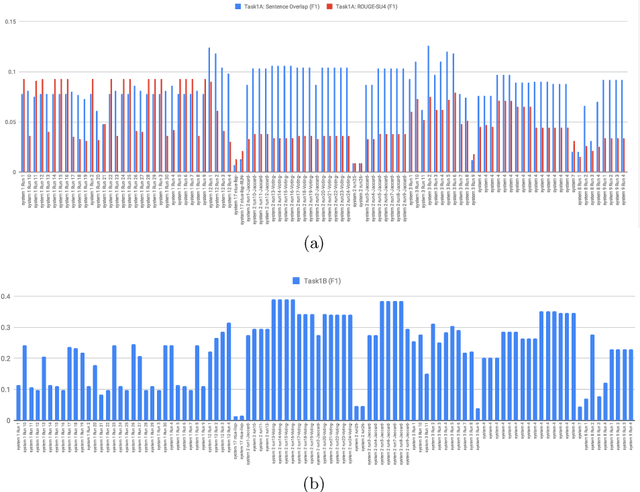
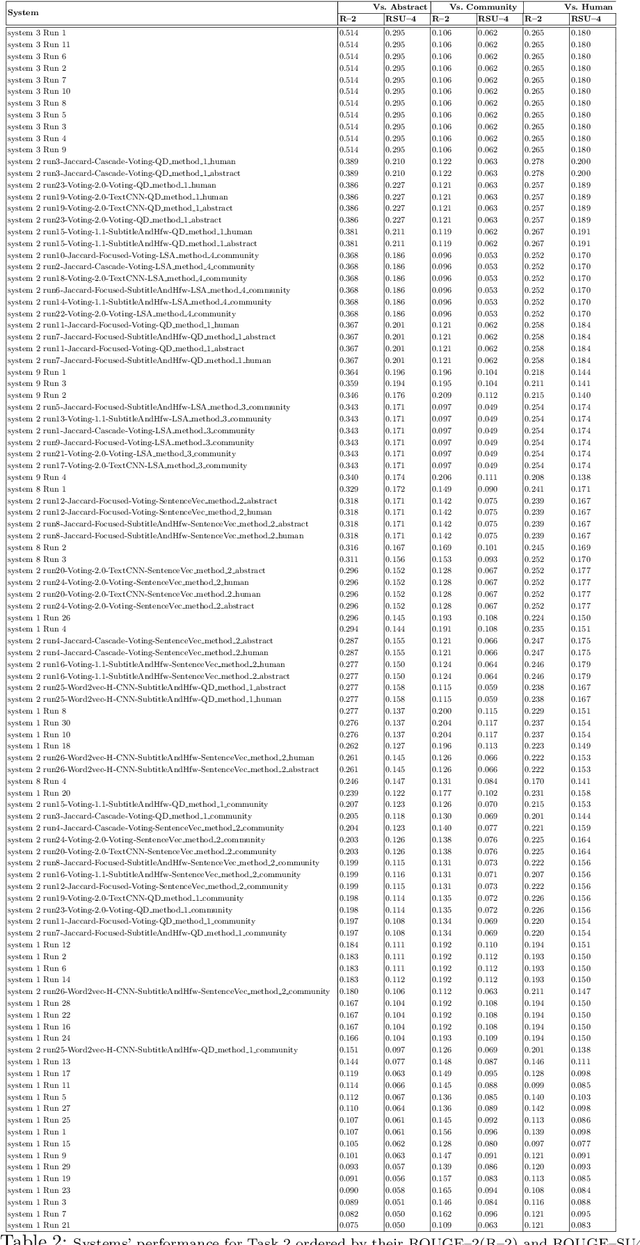
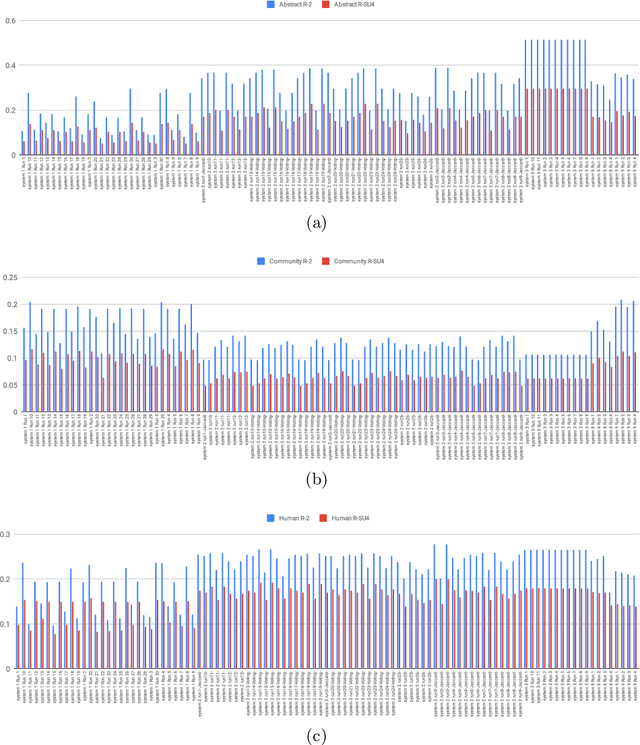
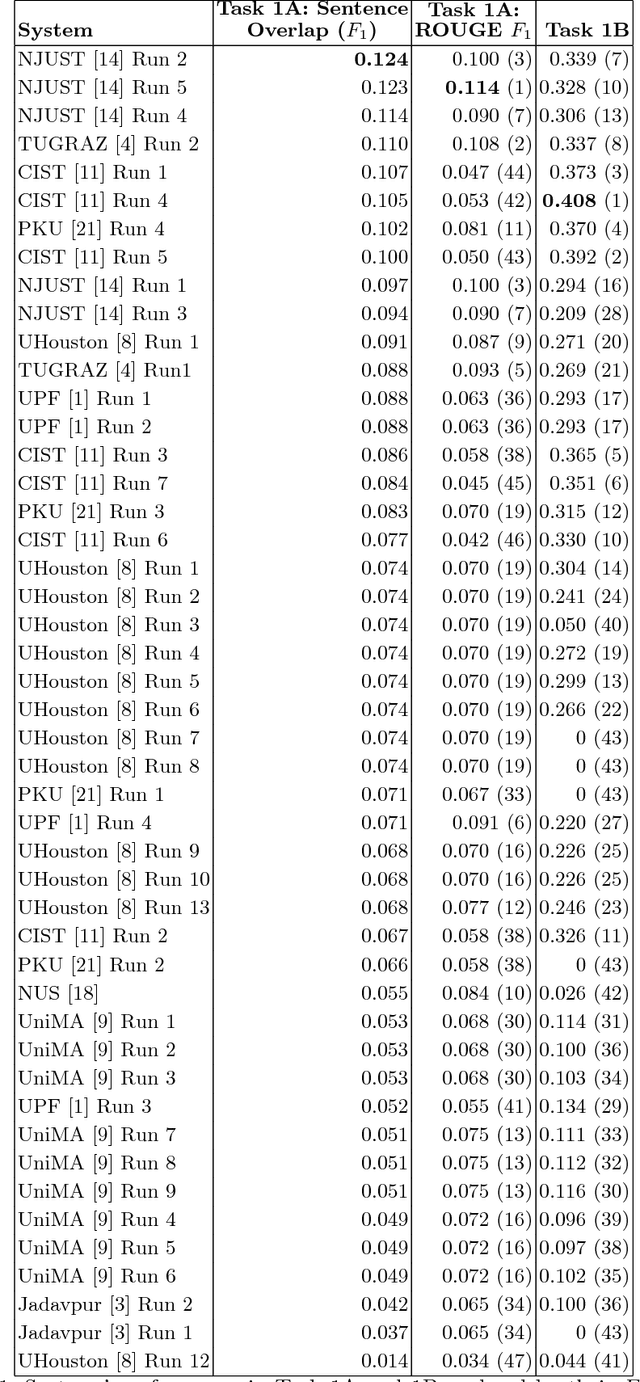
The CL-SciSumm Shared Task is the first medium-scale shared task on scientific document summarization in the computational linguistics~(CL) domain. In 2019, it comprised three tasks: (1A) identifying relationships between citing documents and the referred document, (1B) classifying the discourse facets, and (2) generating the abstractive summary. The dataset comprised 40 annotated sets of citing and reference papers of the CL-SciSumm 2018 corpus and 1000 more from the SciSummNet dataset. All papers are from the open access research papers in the CL domain. This overview describes the participation and the official results of the CL-SciSumm 2019 Shared Task, organized as a part of the 42nd Annual Conference of the Special Interest Group in Information Retrieval (SIGIR), held in Paris, France in July 2019. We compare the participating systems in terms of two evaluation metrics and discuss the use of ROUGE as an evaluation metric. The annotated dataset used for this shared task and the scripts used for evaluation can be accessed and used by the community at: https://github.com/WING-NUS/scisumm-corpus.
When to reply? Context Sensitive Models to Predict Instructor Interventions in MOOC Forums
May 26, 2019
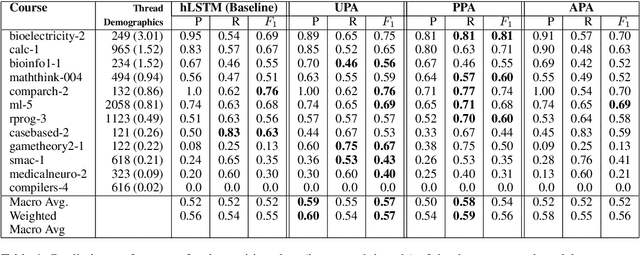
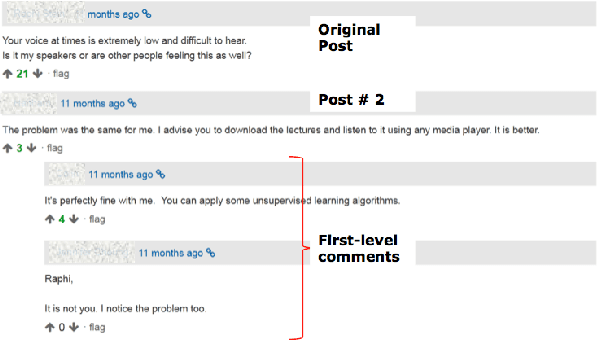
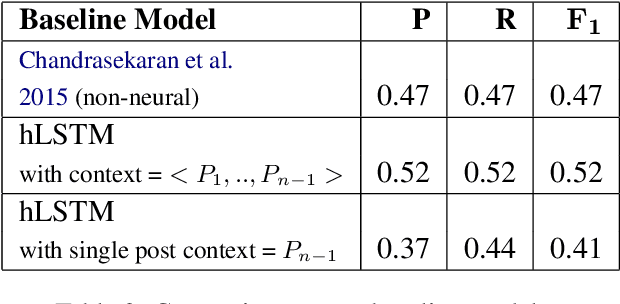
Due to time constraints, course instructors often need to selectively participate in student discussion threads, due to their limited bandwidth and lopsided student--instructor ratio on online forums. We propose the first deep learning models for this binary prediction problem. We propose novel attention based models to infer the amount of latent context necessary to predict instructor intervention. Such models also allow themselves to be tuned to instructor's preference to intervene early or late. Our three proposed attentive model variants to infer the latent context improve over the state-of-the-art by a significant, large margin of 11% in F1 and 10% in recall, on average. Further, introspection of attention help us better understand what aspects of a discussion post propagate through the discussion thread that prompts instructor intervention.
A Comparison of Word Embeddings for English and Cross-Lingual Chinese Word Sense Disambiguation
Apr 09, 2017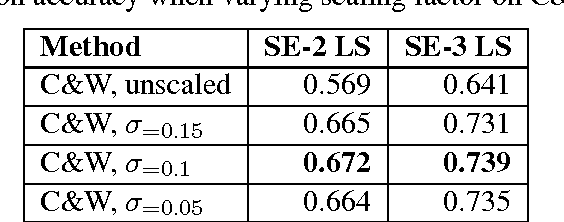
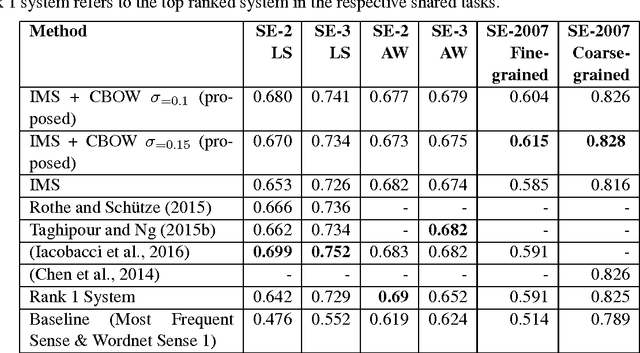
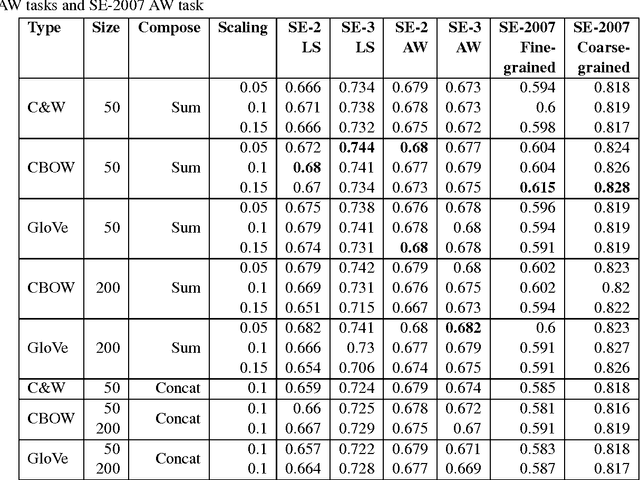
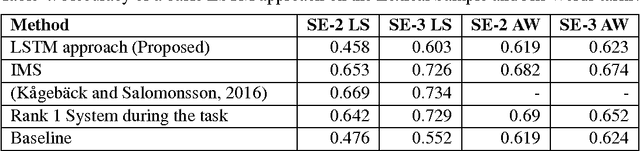
Word embeddings are now ubiquitous forms of word representation in natural language processing. There have been applications of word embeddings for monolingual word sense disambiguation (WSD) in English, but few comparisons have been done. This paper attempts to bridge that gap by examining popular embeddings for the task of monolingual English WSD. Our simplified method leads to comparable state-of-the-art performance without expensive retraining. Cross-Lingual WSD - where the word senses of a word in a source language e come from a separate target translation language f - can also assist in language learning; for example, when providing translations of target vocabulary for learners. Thus we have also applied word embeddings to the novel task of cross-lingual WSD for Chinese and provide a public dataset for further benchmarking. We have also experimented with using word embeddings for LSTM networks and found surprisingly that a basic LSTM network does not work well. We discuss the ramifications of this outcome.
* 10 pages. Appears in the Proceedings of The 3rd Workshop on Natural Language Processing Techniques for Educational Applications (NLPTEA 2016)
Using Discourse Signals for Robust Instructor Intervention Prediction
Dec 03, 2016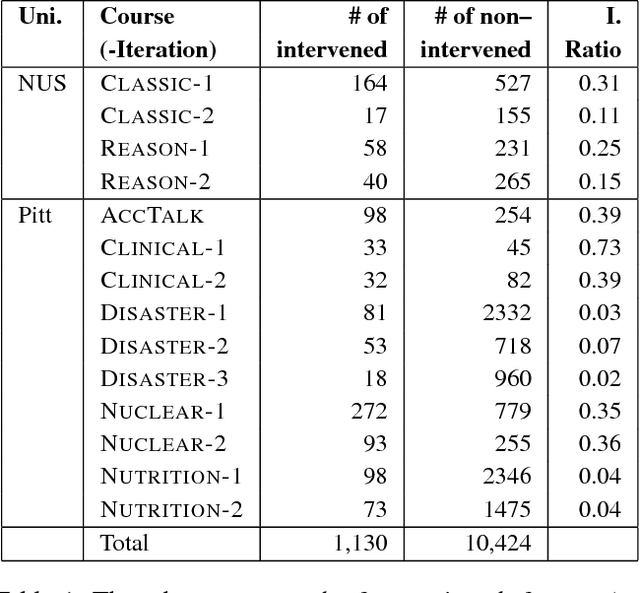
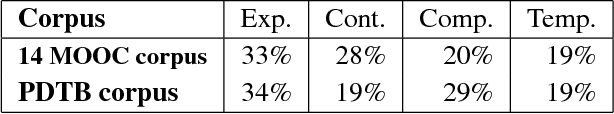
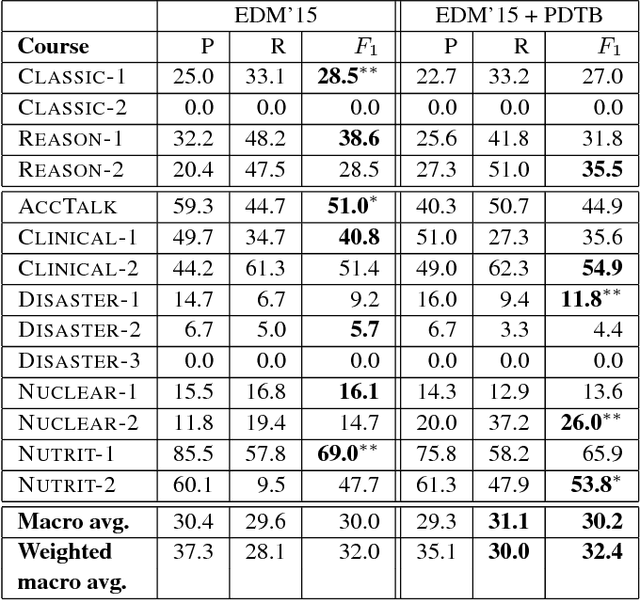
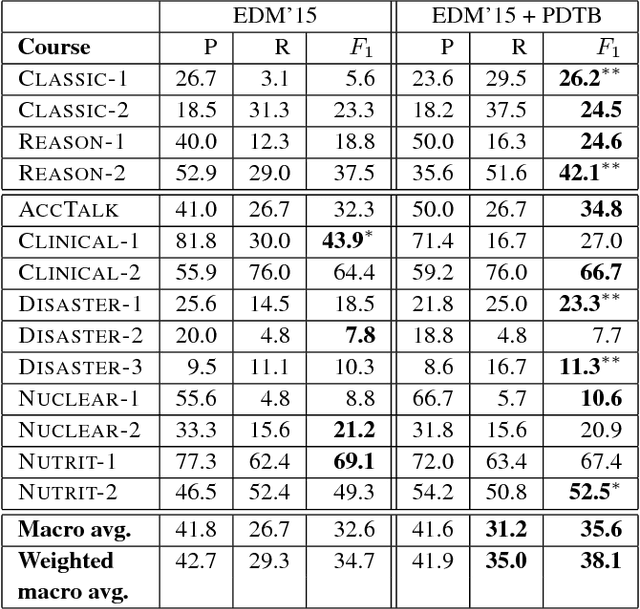
We tackle the prediction of instructor intervention in student posts from discussion forums in Massive Open Online Courses (MOOCs). Our key finding is that using automatically obtained discourse relations improves the prediction of when instructors intervene in student discussions, when compared with a state-of-the-art, feature-rich baseline. Our supervised classifier makes use of an automatic discourse parser which outputs Penn Discourse Treebank (PDTB) tags that represent in-post discourse features. We show PDTB relation-based features increase the robustness of the classifier and complement baseline features in recalling more diverse instructor intervention patterns. In comprehensive experiments over 14 MOOC offerings from several disciplines, the PDTB discourse features improve performance on average. The resultant models are less dependent on domain-specific vocabulary, allowing them to better generalize to new courses.