 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPruner: Transformer-Based Call Graph Pruning
Paper and Code

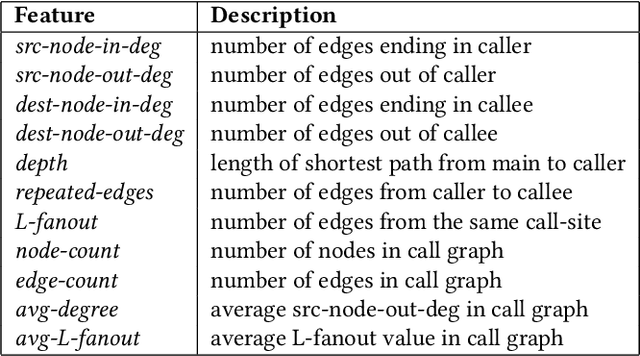
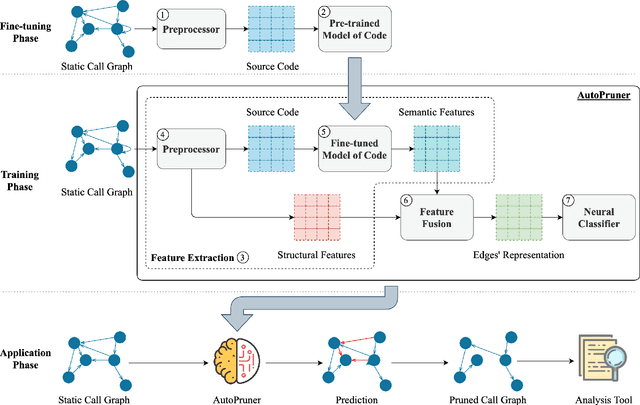

Constructing a static call graph requires trade-offs between soundness and precision. Program analysis techniques for constructing call graphs are unfortunately usually imprecise. To address this problem, researchers have recently proposed call graph pruning empowered by machine learning to post-process call graphs constructed by static analysis. A machine learning model is built to capture information from the call graph by extracting structural features for use in a random forest classifier. It then removes edges that are predicted to be false positives. Despite the improvements shown by machine learning models, they are still limited as they do not consider the source code semantics and thus often are not able to effectively distinguish true and false positives. In this paper, we present a novel call graph pruning technique, AutoPruner, for eliminating false positives in call graphs via both statistical semantic and structural analysis. Given a call graph constructed by traditional static analysis tools, AutoPruner takes a Transformer-based approach to capture the semantic relationships between the caller and callee functions associated with each edge in the call graph. To do so, AutoPruner fine-tunes a model of code that was pre-trained on a large corpus to represent source code based on descriptions of its semantics. Next, the model is used to extract semantic features from the functions related to each edge in the call graph. AutoPruner uses these semantic features together with the structural features extracted from the call graph to classify each edge via a feed-forward neural network. Our empirical evaluation on a benchmark dataset of real-world programs shows that AutoPruner outperforms the state-of-the-art baselines, improving on F-measure by up to 13% in identifying false-positive edges in a static call graph.