 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadon-Nikodým Derivative: Re-imagining Anomaly Detection from a Measure Theoretic Perspective
Feb 25, 2025Which principle underpins the design of an effective anomaly detection loss function? The answer lies in the concept of \rnthm{} theorem, a fundamental concept in measure theory. The key insight is -- Multiplying the vanilla loss function with the \rnthm{} derivative improves the performance across the board. We refer to this as RN-Loss. This is established using PAC learnability of anomaly detection. We further show that the \rnthm{} derivative offers important insights into unsupervised clustering based anomaly detections as well. We evaluate our algorithm on 96 datasets, including univariate and multivariate data from diverse domains, including healthcare, cybersecurity, and finance. We show that RN-Derivative algorithms outperform state-of-the-art methods on 68\% of Multivariate datasets (based on F-1 scores) and also achieves peak F1-scores on 72\% of time series (Univariate) datasets.
Strong convexity-guided hyper-parameter optimization for flatter losses
Feb 07, 2024We propose a novel white-box approach to hyper-parameter optimization. Motivated by recent work establishing a relationship between flat minima and generalization, we first establish a relationship between the strong convexity of the loss and its flatness. Based on this, we seek to find hyper-parameter configurations that improve flatness by minimizing the strong convexity of the loss. By using the structure of the underlying neural network, we derive closed-form equations to approximate the strong convexity parameter, and attempt to find hyper-parameters that minimize it in a randomized fashion. Through experiments on 14 classification datasets, we show that our method achieves strong performance at a fraction of the runtime.
SMOOTHIE: A Theory of Hyper-parameter Optimization for Software Analytics
Jan 17, 2024Hyper-parameter optimization is the black art of tuning a learner's control parameters. In software analytics, a repeated result is that such tuning can result in dramatic performance improvements. Despite this, hyper-parameter optimization is often applied rarely or poorly in software analytics--perhaps due to the CPU cost of exploring all those parameter options can be prohibitive. We theorize that learners generalize better when the loss landscape is ``smooth''. This theory is useful since the influence on ``smoothness'' of different hyper-parameter choices can be tested very quickly (e.g. for a deep learner, after just one epoch). To test this theory, this paper implements and tests SMOOTHIE, a novel hyper-parameter optimizer that guides its optimizations via considerations of ``smothness''. The experiments of this paper test SMOOTHIE on numerous SE tasks including (a) GitHub issue lifetime prediction; (b) detecting false alarms in static code warnings; (c) defect prediction, and (d) a set of standard ML datasets. In all these experiments, SMOOTHIE out-performed state-of-the-art optimizers. Better yet, SMOOTHIE ran 300% faster than the prior state-of-the art. We hence conclude that this theory (that hyper-parameter optimization is best viewed as a ``smoothing'' function for the decision landscape), is both theoretically interesting and practically very useful. To support open science and other researchers working in this area, all our scripts and datasets are available on-line at https://github.com/yrahul3910/smoothness-hpo/.
How to Find Actionable Static Analysis Warnings
May 21, 2022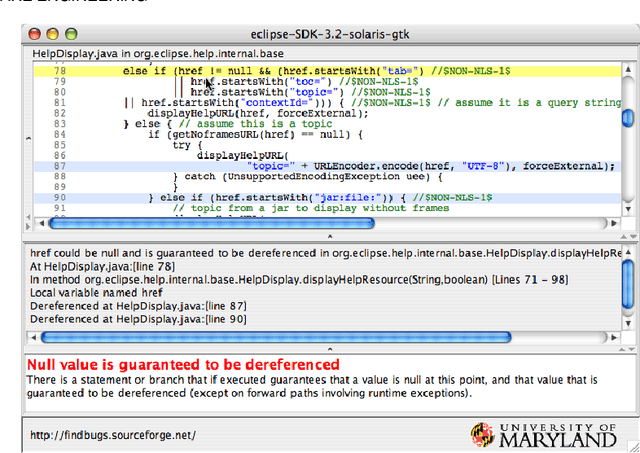

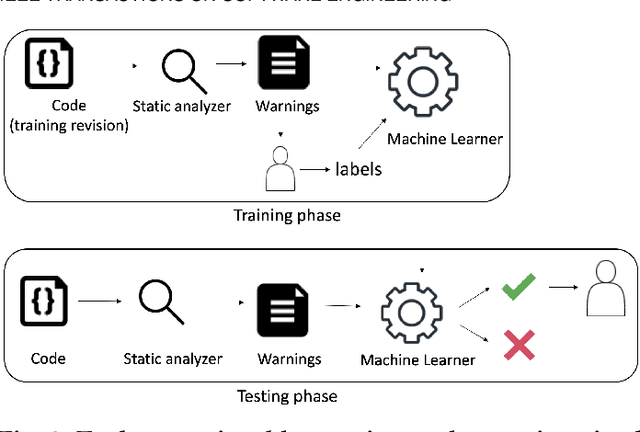
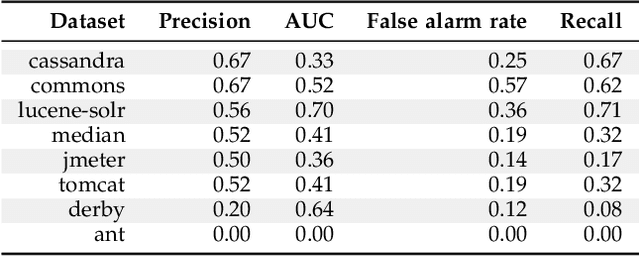
Automatically generated static code warnings suffer from a large number of false alarms. Hence, developers only take action on a small percent of those warnings. To better predict which static code warnings should not be ignored, we suggest that analysts need to look deeper into their algorithms to find choices that better improve the particulars of their specific problem. Specifically, we show here that effective predictors of such warnings can be created by methods that locally adjust the decision boundary (between actionable warnings and others). These methods yield a new high water-mark for recognizing actionable static code warnings. For eight open-source Java projects (CASSANDRA, JMETER, COMMONS, LUCENE-SOLR, ANT, TOMCAT, DERBY) we achieve perfect test results on 4/8 datasets and, overall, a median AUC (area under the true negatives, true positives curve) of 92\%.
Partitioning Cloud-based Microservices (via Deep Learning)
Sep 29, 2021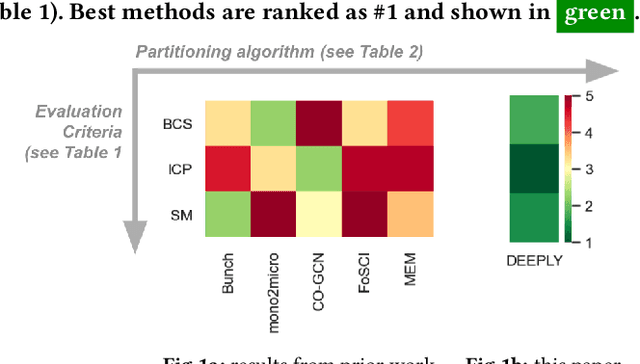

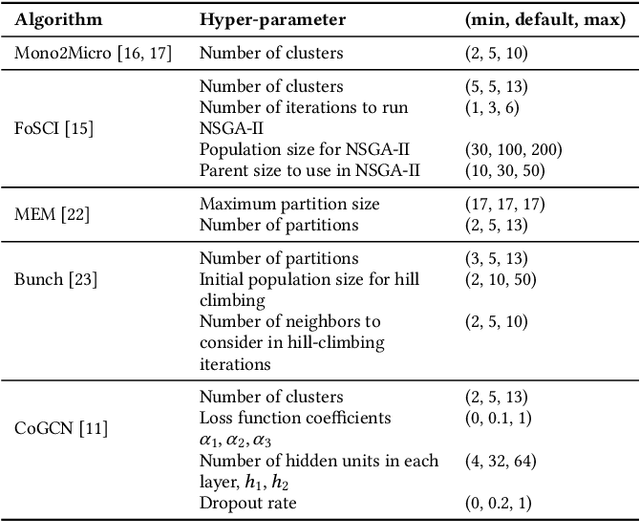
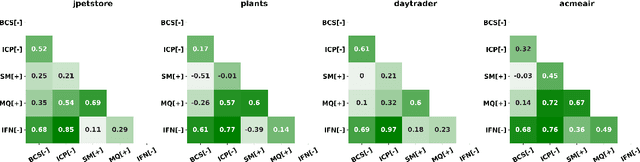
Cloud-based software has many advantages. When services are divided into many independent components, they are easier to update. Also, during peak demand, it is easier to scale cloud services (just hire more CPUs). Hence, many organizations are partitioning their monolithic enterprise applications into cloud-based microservices. Recently there has been much work using machine learning to simplify this partitioning task. Despite much research, no single partitioning method can be recommended as generally useful. More specifically, those prior solutions are "brittle''; i.e. if they work well for one kind of goal in one dataset, then they can be sub-optimal if applied to many datasets and multiple goals. In order to find a generally useful partitioning method, we propose DEEPLY. This new algorithm extends the CO-GCN deep learning partition generator with (a) a novel loss function and (b) some hyper-parameter optimization. As shown by our experiments, DEEPLY generally outperforms prior work (including CO-GCN, and others) across multiple datasets and goals. To the best of our knowledge, this is the first report in SE of such stable hyper-parameter optimization. To aid reuse of this work, DEEPLY is available on-line at https://bit.ly/2WhfFlB.
When SIMPLE is better than complex: A case study on deep learning for predicting Bugzilla issue close time
Jan 15, 2021

Is deep learning over-hyped? Where are the case studies that compare state-of-the-art deep learners with simpler options? In response to this gap in the literature, this paper offers one case study on using deep learning to predict issue close time in Bugzilla. We report here that a SIMPLE extension to a decades-old feedforward neural network works better than the more recent, and more elaborate, "long-short term memory" deep learning (which are currently popular in the SE literature). SIMPLE is a combination of a fast feedforward network and a hyper-parameter optimizer. SIMPLE runs in 3 seconds while the newer algorithms take 6 hours to terminate. Since it runs so fast, it is more amenable to being tuned by our optimizer. This paper reports results seen after running SIMPLE on issue close time data from 45,364 issues raised in Chromium, Eclipse, and Firefox projects from January 2010 to March 2016. In our experiments, this SIMPLEr tuning approach achieves significantly better predictors for issue close time than the more complex deep learner. These better and SIMPLEr results can be generated 2,700 times faster than if using a state-of-the-art deep learner. From this result, we make two conclusions. Firstly, for predicting issue close time, we would recommend SIMPLE over complex deep learners. Secondly, before analysts try very sophisticated (but very slow) algorithms, they might achieve better results, much sooner, by applying hyper-parameter optimization to simple (but very fast) algorithms.
Parsimonious Computing: A Minority Training Regime for Effective Prediction in Large Microarray Expression Data Sets
May 18, 2020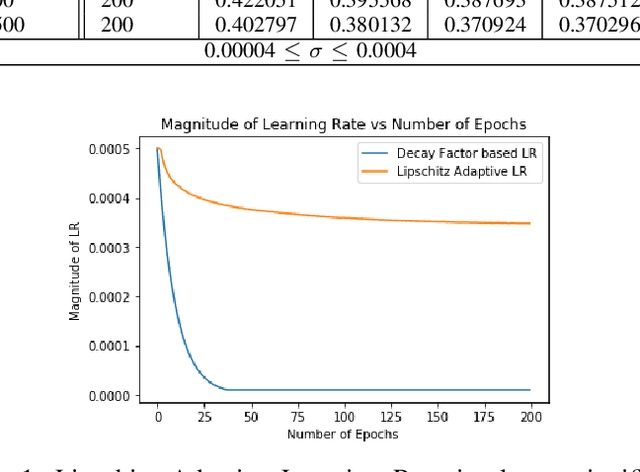
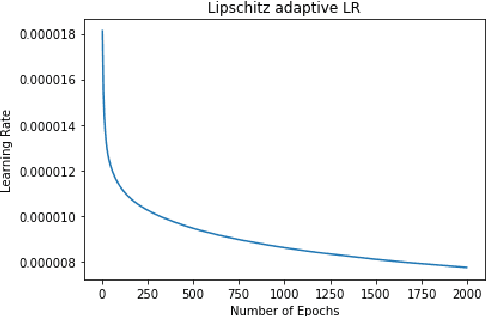
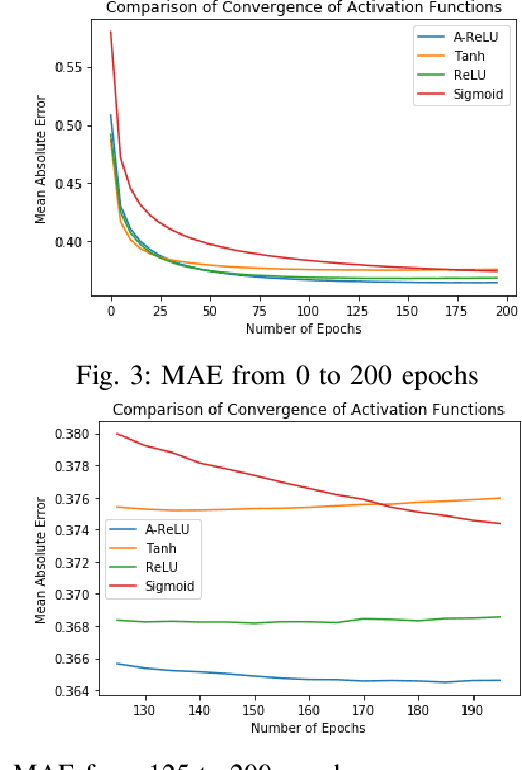
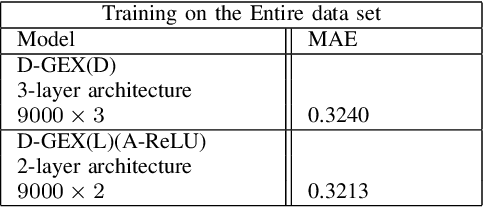
Rigorous mathematical investigation of learning rates used in back-propagation in shallow neural networks has become a necessity. This is because experimental evidence needs to be endorsed by a theoretical background. Such theory may be helpful in reducing the volume of experimental effort to accomplish desired results. We leveraged the functional property of Mean Square Error, which is Lipschitz continuous to compute learning rate in shallow neural networks. We claim that our approach reduces tuning efforts, especially when a significant corpus of data has to be handled. We achieve remarkable improvement in saving computational cost while surpassing prediction accuracy reported in literature. The learning rate, proposed here, is the inverse of the Lipschitz constant. The work results in a novel method for carrying out gene expression inference on large microarray data sets with a shallow architecture constrained by limited computing resources. A combination of random sub-sampling of the dataset, an adaptive Lipschitz constant inspired learning rate and a new activation function, A-ReLU helped accomplish the results reported in the paper.
Evolution of Novel Activation Functions in Neural Network Training with Applications to Classification of Exoplanets
Jun 01, 2019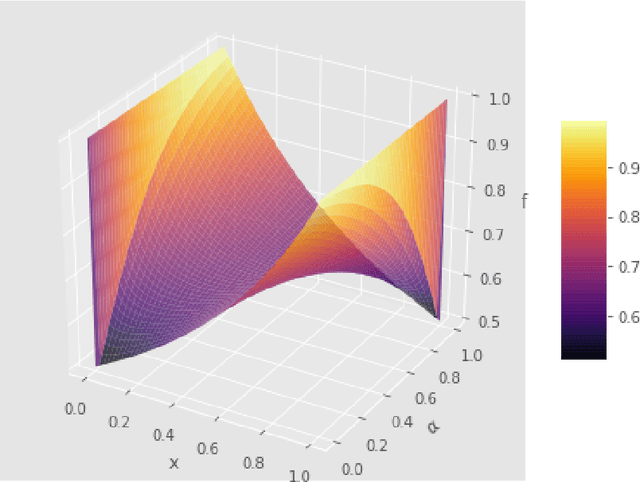
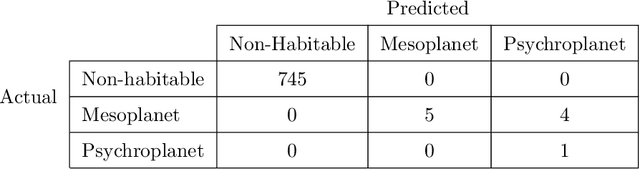
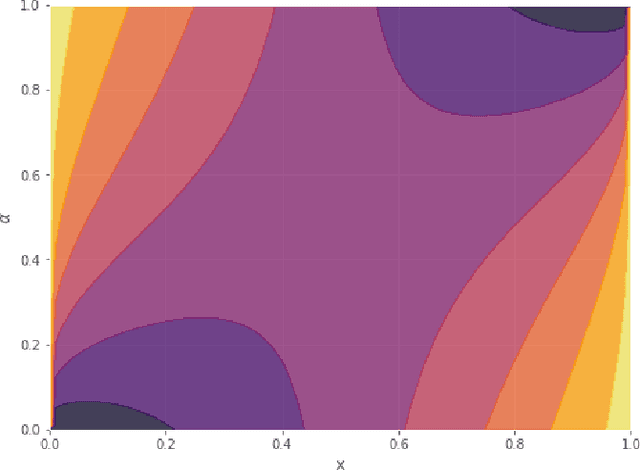
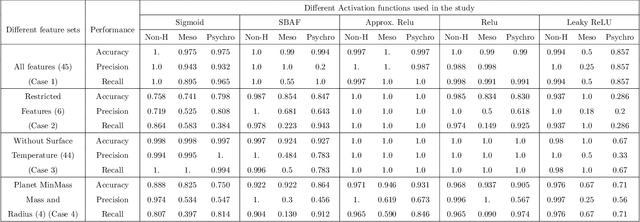
We present analytical exploration of novel activation functions as consequence of integration of several ideas leading to implementation and subsequent use in habitability classification of exoplanets. Neural networks, although a powerful engine in supervised methods, often require expensive tuning efforts for optimized performance. Habitability classes are hard to discriminate, especially when attributes used as hard markers of separation are removed from the data set. The solution is approached from the point of investigating analytical properties of the proposed activation functions. The theory of ordinary differential equations and fixed point are exploited to justify the "lack of tuning efforts" to achieve optimal performance compared to traditional activation functions. Additionally, the relationship between the proposed activation functions and the more popular ones is established through extensive analytical and empirical evidence. Finally, the activation functions have been implemented in plain vanilla feed-forward neural network to classify exoplanets.
A novel adaptive learning rate scheduler for deep neural networks
Mar 13, 2019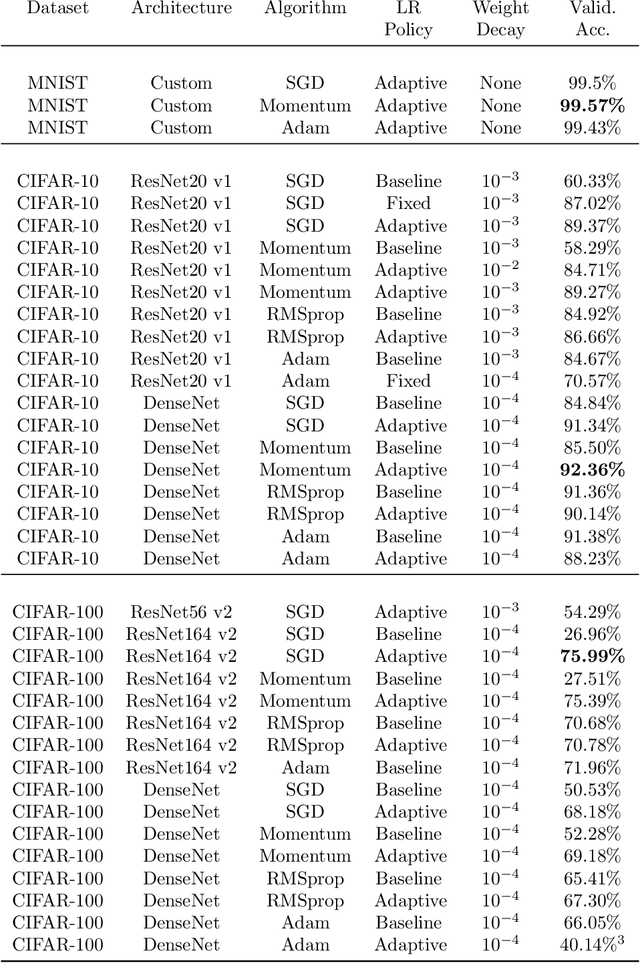

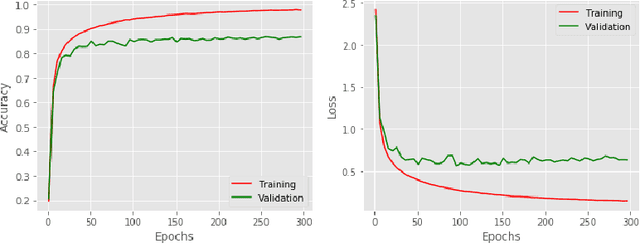
Optimizing deep neural networks is largely thought to be an empirical process, requiring manual tuning of several hyper-parameters, such as learning rate, weight decay, and dropout rate. Arguably, the learning rate is the most important of these to tune, and this has gained more attention in recent works. In this paper, we propose a novel method to compute the learning rate for training deep neural networks with stochastic gradient descent. We first derive a theoretical framework to compute learning rates dynamically based on the Lipschitz constant of the loss function. We then extend this framework to other commonly used optimization algorithms, such as gradient descent with momentum and Adam. We run an extensive set of experiments that demonstrate the efficacy of our approach on popular architectures and datasets, and show that commonly used learning rates are an order of magnitude smaller than the ideal value.
Employee Attrition Prediction
Jun 19, 2018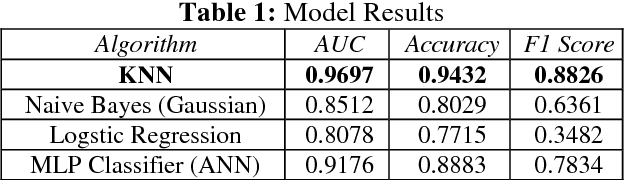
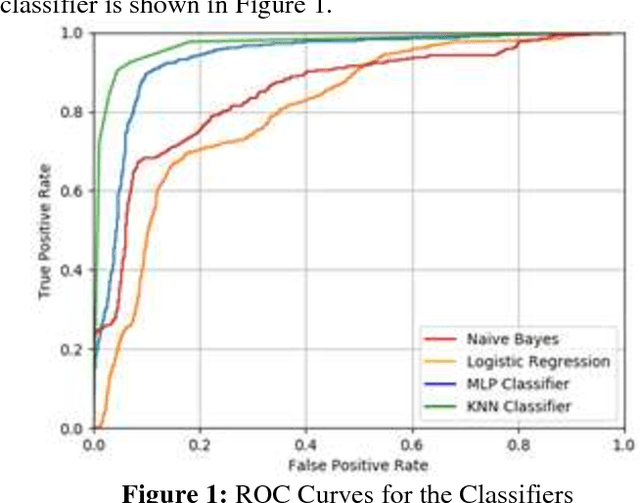
We aim to predict whether an employee of a company will leave or not, using the k-Nearest Neighbors algorithm. We use evaluation of employee performance, average monthly hours at work and number of years spent in the company, among others, as our features. Other approaches to this problem include the use of ANNs, decision trees and logistic regression. The dataset was split, using 70% for training the algorithm and 30% for testing it, achieving an accuracy of 94.32%.