 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching High-Dimensional Geometric Quantiles for Test-Time Adaptation of Transformers and Convolutional Networks Alike
Jan 16, 2026Test-time adaptation (TTA) refers to adapting a classifier for the test data when the probability distribution of the test data slightly differs from that of the training data of the model. To the best of our knowledge, most of the existing TTA approaches modify the weights of the classifier relying heavily on the architecture. It is unclear as to how these approaches are extendable to generic architectures. In this article, we propose an architecture-agnostic approach to TTA by adding an adapter network pre-processing the input images suitable to the classifier. This adapter is trained using the proposed quantile loss. Unlike existing approaches, we correct for the distribution shift by matching high-dimensional geometric quantiles. We prove theoretically that under suitable conditions minimizing quantile loss can learn the optimal adapter. We validate our approach on CIFAR10-C, CIFAR100-C and TinyImageNet-C by training both classic convolutional and transformer networks on CIFAR10, CIFAR100 and TinyImageNet datasets.
Radon-Nikodým Derivative: Re-imagining Anomaly Detection from a Measure Theoretic Perspective
Feb 25, 2025Which principle underpins the design of an effective anomaly detection loss function? The answer lies in the concept of \rnthm{} theorem, a fundamental concept in measure theory. The key insight is -- Multiplying the vanilla loss function with the \rnthm{} derivative improves the performance across the board. We refer to this as RN-Loss. This is established using PAC learnability of anomaly detection. We further show that the \rnthm{} derivative offers important insights into unsupervised clustering based anomaly detections as well. We evaluate our algorithm on 96 datasets, including univariate and multivariate data from diverse domains, including healthcare, cybersecurity, and finance. We show that RN-Derivative algorithms outperform state-of-the-art methods on 68\% of Multivariate datasets (based on F-1 scores) and also achieves peak F1-scores on 72\% of time series (Univariate) datasets.
A Granger-Causal Perspective on Gradient Descent with Application to Pruning
Dec 04, 2024



Stochastic Gradient Descent (SGD) is the main approach to optimizing neural networks. Several generalization properties of deep networks, such as convergence to a flatter minima, are believed to arise from SGD. This article explores the causality aspect of gradient descent. Specifically, we show that the gradient descent procedure has an implicit granger-causal relationship between the reduction in loss and a change in parameters. By suitable modifications, we make this causal relationship explicit. A causal approach to gradient descent has many significant applications which allow greater control. In this article, we illustrate the significance of the causal approach using the application of Pruning. The causal approach to pruning has several interesting properties - (i) We observe a phase shift as the percentage of pruned parameters increase. Such phase shift is indicative of an optimal pruning strategy. (ii) After pruning, we see that minima becomes "flatter", explaining the increase in accuracy after pruning weights.
Quantile Activation: departing from single point estimation for better generalization across distortions
May 19, 2024



A classifier is, in its essence, a function which takes an input and returns the class of the input and implicitly assumes an underlying distribution. We argue in this article that one has to move away from this basic tenet to obtain generalisation across distributions. Specifically, the class of the sample should depend on the points from its context distribution for better generalisation across distributions. How does one achieve this? The key idea is to adapt the outputs of each neuron of the network to its context distribution. We propose quantile activation, QACT, which, in simple terms, outputs the relative quantile of the sample in its context distribution, instead of the actual values in traditional networks. The scope of this article is to validate the proposed activation across several experimental settings, and compare it with conventional techniques. For this, we use the datasets developed to test robustness against distortions CIFAR10C, CIFAR100C, MNISTC, TinyImagenetC, and show that we achieve a significantly higher generalisation across distortions than the conventional classifiers, across different architectures. Although this paper is only a proof of concept, we surprisingly find that this approach outperforms DINOv2(small) at large distortions, even though DINOv2 is trained with a far bigger network on a considerably larger dataset.
Can Tree Based Approaches Surpass Deep Learning in Anomaly Detection? A Benchmarking Study
Feb 26, 2024Detection of anomalous situations for complex mission-critical systems holds paramount importance when their service continuity needs to be ensured. A major challenge in detecting anomalies from the operational data arises due to the imbalanced class distribution problem since the anomalies are supposed to be rare events. This paper evaluates a diverse array of machine learning-based anomaly detection algorithms through a comprehensive benchmark study. The paper contributes significantly by conducting an unbiased comparison of various anomaly detection algorithms, spanning classical machine learning including various tree-based approaches to deep learning and outlier detection methods. The inclusion of 104 publicly available and a few proprietary industrial systems datasets enhances the diversity of the study, allowing for a more realistic evaluation of algorithm performance and emphasizing the importance of adaptability to real-world scenarios. The paper dispels the deep learning myth, demonstrating that though powerful, deep learning is not a universal solution in this case. We observed that recently proposed tree-based evolutionary algorithms outperform in many scenarios. We noticed that tree-based approaches catch a singleton anomaly in a dataset where deep learning methods fail. On the other hand, classical SVM performs the best on datasets with more than 10% anomalies, implying that such scenarios can be best modeled as a classification problem rather than anomaly detection. To our knowledge, such a study on a large number of state-of-the-art algorithms using diverse data sets, with the objective of guiding researchers and practitioners in making informed algorithmic choices, has not been attempted earlier.
Strong convexity-guided hyper-parameter optimization for flatter losses
Feb 07, 2024We propose a novel white-box approach to hyper-parameter optimization. Motivated by recent work establishing a relationship between flat minima and generalization, we first establish a relationship between the strong convexity of the loss and its flatness. Based on this, we seek to find hyper-parameter configurations that improve flatness by minimizing the strong convexity of the loss. By using the structure of the underlying neural network, we derive closed-form equations to approximate the strong convexity parameter, and attempt to find hyper-parameters that minimize it in a randomized fashion. Through experiments on 14 classification datasets, we show that our method achieves strong performance at a fraction of the runtime.
DeliverAI: Reinforcement Learning Based Distributed Path-Sharing Network for Food Deliveries
Nov 03, 2023
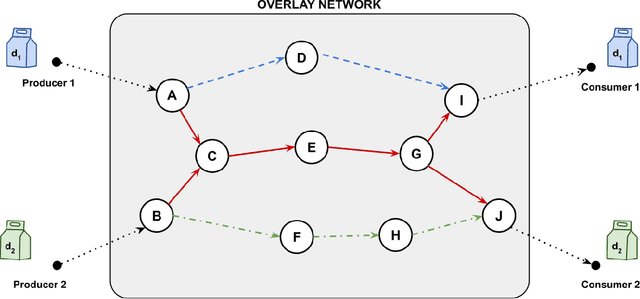
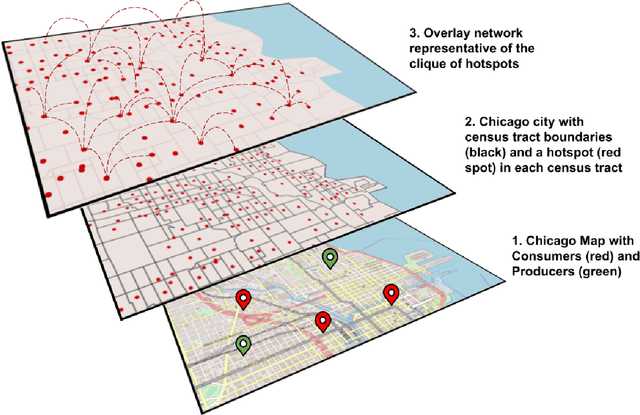
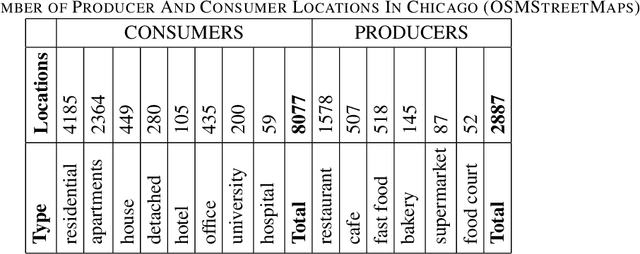
Delivery of items from the producer to the consumer has experienced significant growth over the past decade and has been greatly fueled by the recent pandemic. Amazon Fresh, Shopify, UberEats, InstaCart, and DoorDash are rapidly growing and are sharing the same business model of consumer items or food delivery. Existing food delivery methods are sub-optimal because each delivery is individually optimized to go directly from the producer to the consumer via the shortest time path. We observe a significant scope for reducing the costs associated with completing deliveries under the current model. We model our food delivery problem as a multi-objective optimization, where consumer satisfaction and delivery costs, both, need to be optimized. Taking inspiration from the success of ride-sharing in the taxi industry, we propose DeliverAI - a reinforcement learning-based path-sharing algorithm. Unlike previous attempts for path-sharing, DeliverAI can provide real-time, time-efficient decision-making using a Reinforcement learning-enabled agent system. Our novel agent interaction scheme leverages path-sharing among deliveries to reduce the total distance traveled while keeping the delivery completion time under check. We generate and test our methodology vigorously on a simulation setup using real data from the city of Chicago. Our results show that DeliverAI can reduce the delivery fleet size by 12\%, the distance traveled by 13%, and achieve 50% higher fleet utilization compared to the baselines.
To prune or not to prune : A chaos-causality approach to principled pruning of dense neural networks
Aug 19, 2023Reducing the size of a neural network (pruning) by removing weights without impacting its performance is an important problem for resource-constrained devices. In the past, pruning was typically accomplished by ranking or penalizing weights based on criteria like magnitude and removing low-ranked weights before retraining the remaining ones. Pruning strategies may also involve removing neurons from the network in order to achieve the desired reduction in network size. We formulate pruning as an optimization problem with the objective of minimizing misclassifications by selecting specific weights. To accomplish this, we have introduced the concept of chaos in learning (Lyapunov exponents) via weight updates and exploiting causality to identify the causal weights responsible for misclassification. Such a pruned network maintains the original performance and retains feature explainability.
Decoupling Quantile Representations from Loss Functions
Apr 25, 2023



The simultaneous quantile regression (SQR) technique has been used to estimate uncertainties for deep learning models, but its application is limited by the requirement that the solution at the median quantile ({\tau} = 0.5) must minimize the mean absolute error (MAE). In this article, we address this limitation by demonstrating a duality between quantiles and estimated probabilities in the case of simultaneous binary quantile regression (SBQR). This allows us to decouple the construction of quantile representations from the loss function, enabling us to assign an arbitrary classifier f(x) at the median quantile and generate the full spectrum of SBQR quantile representations at different {\tau} values. We validate our approach through two applications: (i) detecting out-of-distribution samples, where we show that quantile representations outperform standard probability outputs, and (ii) calibrating models, where we demonstrate the robustness of quantile representations to distortions. We conclude with a discussion of several hypotheses arising from these findings.
Correcting Model Misspecification via Generative Adversarial Networks
Apr 07, 2023



Machine learning models are often misspecified in the likelihood, which leads to a lack of robustness in the predictions. In this paper, we introduce a framework for correcting likelihood misspecifications in several paradigm agnostic noisy prior models and test the model's ability to remove the misspecification. The "ABC-GAN" framework introduced is a novel generative modeling paradigm, which combines Generative Adversarial Networks (GANs) and Approximate Bayesian Computation (ABC). This new paradigm assists the existing GANs by incorporating any subjective knowledge available about the modeling process via ABC, as a regularizer, resulting in a partially interpretable model that operates well under low data regimes. At the same time, unlike any Bayesian analysis, the explicit knowledge need not be perfect, since the generator in the GAN can be made arbitrarily complex. ABC-GAN eliminates the need for summary statistics and distance metrics as the discriminator implicitly learns them and enables simultaneous specification of multiple generative models. The model misspecification is simulated in our experiments by introducing noise of various biases and variances. The correction term is learnt via the ABC-GAN, with skip connections, referred to as skipGAN. The strength of the skip connection indicates the amount of correction needed or how misspecified the prior model is. Based on a simple experimental setup, we show that the ABC-GAN models not only correct the misspecification of the prior, but also perform as well as or better than the respective priors under noisier conditions. In this proposal, we show that ABC-GANs get the best of both worlds.