 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDictionary Based Pattern Entropy for Causal Direction Discovery
Mar 04, 2026Discovering causal direction from temporal observational data is particularly challenging for symbolic sequences, where functional models and noise assumptions are often unavailable. We propose a novel \emph{Dictionary Based Pattern Entropy ($DPE$)} framework that infers both the direction of causation and the specific subpatterns driving changes in the effect variable. The framework integrates \emph{Algorithmic Information Theory} (AIT) and \emph{Shannon Information Theory}. Causation is interpreted as the emergence of compact, rule based patterns in the candidate cause that systematically constrain the effect. $DPE$ constructs direction-specific dictionaries and quantifies their influence using entropy-based measures, enabling a principled link between deterministic pattern structure and stochastic variability. Causal direction is inferred via a minimum-uncertainty criterion, selecting the direction exhibiting stronger and more consistent pattern-driven organization. As summarized in Table 7, $DPE$ consistently achieves reliable performance across diverse synthetic systems, including delayed bit-flip perturbations, AR(1) coupling, 1D skew-tent maps, and sparse processes, outperforming or matching competing AIT-based methods ($ETC_E$, $ETC_P$, $LZ_P$). In biological and ecological datasets, performance is competitive, while alternative methods show advantages in specific genomic settings. Overall, the results demonstrate that minimizing pattern level uncertainty yields a robust, interpretable, and broadly applicable framework for causal discovery.
Linked Data Classification using Neurochaos Learning
Feb 18, 2026Neurochaos Learning (NL) has shown promise in recent times over traditional deep learning due to its two key features: ability to learn from small sized training samples, and low compute requirements. In prior work, NL has been implemented and extensively tested on separable and time series data, and demonstrated its superior performance on both classification and regression tasks. In this paper, we investigate the next step in NL, viz., applying NL to linked data, in particular, data that is represented in the form of knowledge graphs. We integrate linked data into NL by implementing node aggregation on knowledge graphs, and then feeding the aggregated node features to the simplest NL architecture: ChaosNet. We demonstrate the results of our implementation on homophilic graph datasets as well as heterophilic graph datasets of verying heterophily. We show better efficacy of our approach on homophilic graphs than on heterophilic graphs. While doing so, we also present our analysis of the results, as well as suggestions for future work.
Deep Learning for Short-Term Precipitation Prediction in Four Major Indian Cities: A ConvLSTM Approach with Explainable AI
Nov 14, 2025Deep learning models for precipitation forecasting often function as black boxes, limiting their adoption in real-world weather prediction. To enhance transparency while maintaining accuracy, we developed an interpretable deep learning framework for short-term precipitation prediction in four major Indian cities: Bengaluru, Mumbai, Delhi, and Kolkata, spanning diverse climate zones. We implemented a hybrid Time-Distributed CNN-ConvLSTM (Convolutional Neural Network-Long Short-Term Memory) architecture, trained on multi-decadal ERA5 reanalysis data. The architecture was optimized for each city with a different number of convolutional filters: Bengaluru (32), Mumbai and Delhi (64), and Kolkata (128). The models achieved root mean square error (RMSE) values of 0.21 mm/day (Bengaluru), 0.52 mm/day (Mumbai), 0.48 mm/day (Delhi), and 1.80 mm/day (Kolkata). Through interpretability analysis using permutation importance, Gradient-weighted Class Activation Mapping (Grad-CAM), temporal occlusion, and counterfactual perturbation, we identified distinct patterns in the model's behavior. The model relied on city-specific variables, with prediction horizons ranging from one day for Bengaluru to five days for Kolkata. This study demonstrates how explainable AI (xAI) can provide accurate forecasts and transparent insights into precipitation patterns in diverse urban environments.
Advancing Forest Fires Classification using Neurochaos Learning
Oct 30, 2025Forest fires are among the most dangerous and unpredictable natural disasters worldwide. Forest fire can be instigated by natural causes or by humans. They are devastating overall, and thus, many research efforts have been carried out to predict whether a fire can occur in an area given certain environmental variables. Many research works employ Machine Learning (ML) and Deep Learning (DL) models for classification; however, their accuracy is merely adequate and falls short of expectations. This limit arises because these models are unable to depict the underlying nonlinearity in nature and extensively rely on substantial training data, which is hard to obtain. We propose using Neurochaos Learning (NL), a chaos-based, brain-inspired learning algorithm for forest fire classification. Like our brains, NL needs less data to learn nonlinear patterns in the training data. It employs one-dimensional chaotic maps, namely the Generalized L\"uroth Series (GLS), as neurons. NL yields comparable performance with ML and DL models, sometimes even surpassing them, particularly in low-sample training regimes, and unlike deep neural networks, NL is interpretable as it preserves causal structures in the data. Random Heterogenous Neurochaos Learning (RHNL), a type of NL where different chaotic neurons are randomnly located to mimic the randomness and heterogeneity of human brain gives the best F1 score of 1.0 for the Algerian Forest Fires Dataset. Compared to other traditional ML classifiers considered, RHNL also gives high precision score of 0.90 for Canadian Forest Fires Dataset and 0.68 for Portugal Forest Fires Dataset. The results obtained from this work indicate that Neurochaos Learning (NL) architectures achieve better performance than conventional machine learning classifiers, highlighting their promise for developing more efficient and reliable forest fire detection systems.
Augmented Regression Models using Neurochaos Learning
May 19, 2025This study presents novel Augmented Regression Models using Neurochaos Learning (NL), where Tracemean features derived from the Neurochaos Learning framework are integrated with traditional regression algorithms : Linear Regression, Ridge Regression, Lasso Regression, and Support Vector Regression (SVR). Our approach was evaluated using ten diverse real-life datasets and a synthetically generated dataset of the form $y = mx + c + \epsilon$. Results show that incorporating the Tracemean feature (mean of the chaotic neural traces of the neurons in the NL architecture) significantly enhances regression performance, particularly in Augmented Lasso Regression and Augmented SVR, where six out of ten real-life datasets exhibited improved predictive accuracy. Among the models, Augmented Chaotic Ridge Regression achieved the highest average performance boost (11.35 %). Additionally, experiments on the simulated dataset demonstrated that the Mean Squared Error (MSE) of the augmented models consistently decreased and converged towards the Minimum Mean Squared Error (MMSE) as the sample size increased. This work demonstrates the potential of chaos-inspired features in regression tasks, offering a pathway to more accurate and computationally efficient prediction models.
Predicting Stock Prices using Permutation Decision Trees and Strategic Trailing
Apr 18, 2025In this paper, we explore the application of Permutation Decision Trees (PDT) and strategic trailing for predicting stock market movements and executing profitable trades in the Indian stock market. We focus on high-frequency data using 5-minute candlesticks for the top 50 stocks listed in the NIFTY 50 index. We implement a trading strategy that aims to buy stocks at lower prices and sell them at higher prices, capitalizing on short-term market fluctuations. Due to regulatory constraints in India, short selling is not considered in our strategy. The model incorporates various technical indicators and employs hyperparameters such as the trailing stop-loss value and support thresholds to manage risk effectively. Our results indicate that the proposed trading bot has the potential to outperform the market average and yield returns higher than the risk-free rate offered by 10-year Indian government bonds. We trained and tested data on a 60 day dataset provided by Yahoo Finance. Specifically, 12 days for testing and 48 days for training. Our bot based on permutation decision tree achieved a profit of 1.3468 % over a 12-day testing period, where as a bot based on LSTM gave a return of 0.1238 % over a 12-day testing period and a bot based on RNN gave a return of 0.3096 % over a 12-day testing period. All of the bots outperform the buy-and-hold strategy, which resulted in a loss of 2.2508 %.
Chaotic Map based Compression Approach to Classification
Feb 17, 2025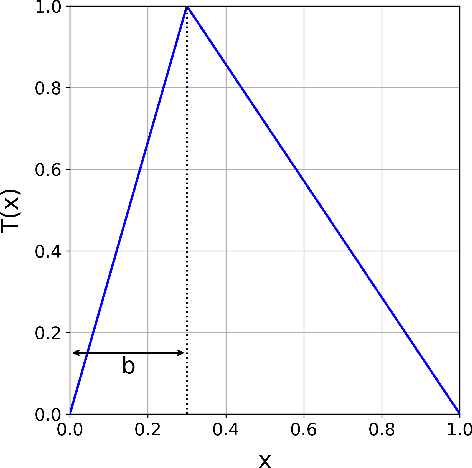
Modern machine learning approaches often prioritize performance at the cost of increased complexity, computational demands, and reduced interpretability. This paper introduces a novel framework that challenges this trend by reinterpreting learning from an information-theoretic perspective, viewing it as a search for encoding schemes that capture intrinsic data structures through compact representations. Rather than following the conventional approach of fitting data to complex models, we propose a fundamentally different method that maps data to intervals of initial conditions in a dynamical system. Our GLS (Generalized L\"uroth Series) coding compression classifier employs skew tent maps - a class of chaotic maps - both for encoding data into initial conditions and for subsequent recovery. The effectiveness of this simple framework is noteworthy, with performance closely approaching that of well-established machine learning methods. On the breast cancer dataset, our approach achieves 92.98\% accuracy, comparable to Naive Bayes at 94.74\%. While these results do not exceed state-of-the-art performance, the significance of our contribution lies not in outperforming existing methods but in demonstrating that a fundamentally simpler, more interpretable approach can achieve competitive results.
Integrating Causality with Neurochaos Learning: Proposed Approach and Research Agenda
Jan 23, 2025Deep learning implemented via neural networks, has revolutionized machine learning by providing methods for complex tasks such as object detection/classification and prediction. However, architectures based on deep neural networks have started to yield diminishing returns, primarily due to their statistical nature and inability to capture causal structure in the training data. Another issue with deep learning is its high energy consumption, which is not that desirable from a sustainability perspective. Therefore, alternative approaches are being considered to address these issues, both of which are inspired by the functioning of the human brain. One approach is causal learning, which takes into account causality among the items in the dataset on which the neural network is trained. It is expected that this will help minimize the spurious correlations that are prevalent in the learned representations of deep neural networks. The other approach is Neurochaos Learning, a recent development, which draws its inspiration from the nonlinear chaotic firing intrinsic to neurons in biological neural networks (brain/central nervous system). Both approaches have shown improved results over just deep learning alone. To that end, in this position paper, we investigate how causal and neurochaos learning approaches can be integrated together to produce better results, especially in domains that contain linked data. We propose an approach for this integration to enhance classification, prediction and reinforcement learning. We also propose a set of research questions that need to be investigated in order to make this integration a reality.
Causal Discovery and Classification Using Lempel-Ziv Complexity
Nov 04, 2024Inferring causal relationships in the decision-making processes of machine learning algorithms is a crucial step toward achieving explainable Artificial Intelligence (AI). In this research, we introduce a novel causality measure and a distance metric derived from Lempel-Ziv (LZ) complexity. We explore how the proposed causality measure can be used in decision trees by enabling splits based on features that most strongly \textit{cause} the outcome. We further evaluate the effectiveness of the causality-based decision tree and the distance-based decision tree in comparison to a traditional decision tree using Gini impurity. While the proposed methods demonstrate comparable classification performance overall, the causality-based decision tree significantly outperforms both the distance-based decision tree and the Gini-based decision tree on datasets generated from causal models. This result indicates that the proposed approach can capture insights beyond those of classical decision trees, especially in causally structured data. Based on the features used in the LZ causal measure based decision tree, we introduce a causal strength for each features in the dataset so as to infer the predominant causal variables for the occurrence of the outcome.
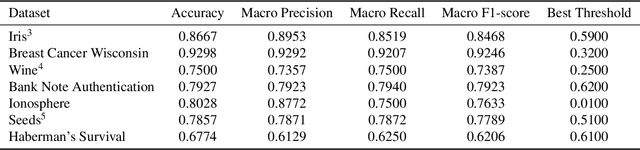
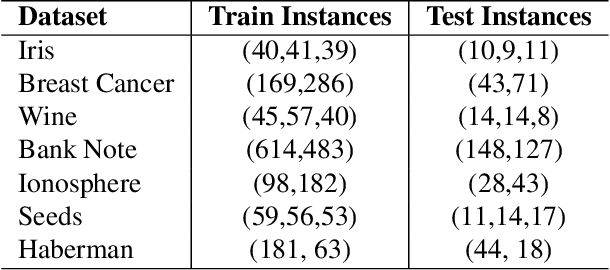
Random Heterogeneous Neurochaos Learning Architecture for Data Classification
Oct 30, 2024


Inspired by the human brain's structure and function, Artificial Neural Networks (ANN) were developed for data classification. However, existing Neural Networks, including Deep Neural Networks, do not mimic the brain's rich structure. They lack key features such as randomness and neuron heterogeneity, which are inherently chaotic in their firing behavior. Neurochaos Learning (NL), a chaos-based neural network, recently employed one-dimensional chaotic maps like Generalized L\"uroth Series (GLS) and Logistic map as neurons. For the first time, we propose a random heterogeneous extension of NL, where various chaotic neurons are randomly placed in the input layer, mimicking the randomness and heterogeneous nature of human brain networks. We evaluated the performance of the newly proposed Random Heterogeneous Neurochaos Learning (RHNL) architectures combined with traditional Machine Learning (ML) methods. On public datasets, RHNL outperformed both homogeneous NL and fixed heterogeneous NL architectures in nearly all classification tasks. RHNL achieved high F1 scores on the Wine dataset (1.0), Bank Note Authentication dataset (0.99), Breast Cancer Wisconsin dataset (0.99), and Free Spoken Digit Dataset (FSDD) (0.98). These RHNL results are among the best in the literature for these datasets. We investigated RHNL performance on image datasets, where it outperformed stand-alone ML classifiers. In low training sample regimes, RHNL was the best among stand-alone ML. Our architecture bridges the gap between existing ANN architectures and the human brain's chaotic, random, and heterogeneous properties. We foresee the development of several novel learning algorithms centered around Random Heterogeneous Neurochaos Learning in the coming days.