 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-confidence Recourse Using tSeTlin machines: TRUST
Jun 17, 2026Counterfactual explanations are widely used to provide algorithmic recourse in high-stakes decision-making systems. Most existing methods seek the smallest change to an input that flips a model's decision. However, decision-makers often rely not only on predicted labels but also on confidence thresholds and risk margins. Counterfactuals that barely cross a decision boundary can be fragile and unstable under noise or model variation. In this paper, we propose Target-confidence Recourse Using tSeTlin machines (TRUST), a framework in which users explicitly specify the desired prediction confidence for recourse. Rather than generating counterfactuals and evaluating confidence afterward, TRUST directly searches for minimal changes that satisfy a user-defined confidence target, enabling comparison of recourse options in terms of cost, confidence, and robustness. We instantiate TRUST using a Probabilistic Tsetlin Machine (PTM) combined with Bayesian optimization. The probabilistic clause-based structure of PTM links prediction confidence to the stability of decision rules. We show that counterfactuals satisfying the same rules can still differ substantially in reliability depending on how securely they satisfy those rules, revealing whether decisions are supported by robust or fragile clause activations. Experiments on synthetic and real-world datasets demonstrate that target-confidence counterfactuals produce more robust and interpretable recourse than conventional boundary-based approaches. Across multiple benchmarks, TRUST achieves perfect robustness while maintaining low recourse cost, including an L2 distance of 0.10 on the Haberman dataset at 0.92 confidence. By explicitly controlling confidence and exposing rule-level stability, TRUST provides actionable recourse for high-stakes decision support.
Chaotic Map based Compression Approach to Classification
Feb 17, 2025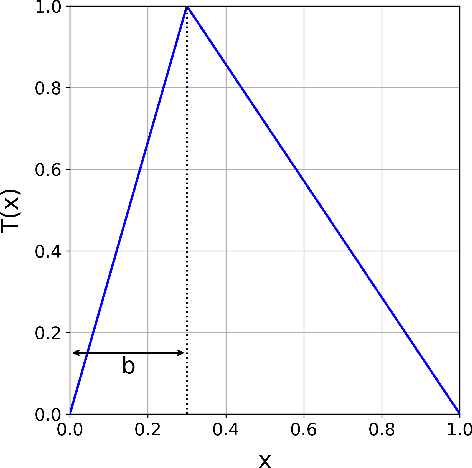
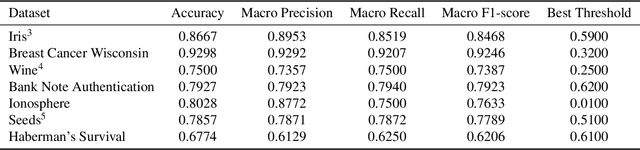
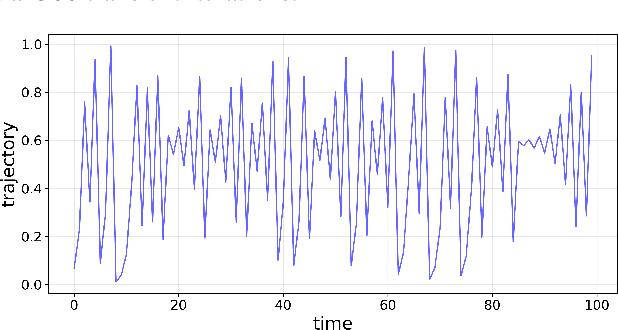
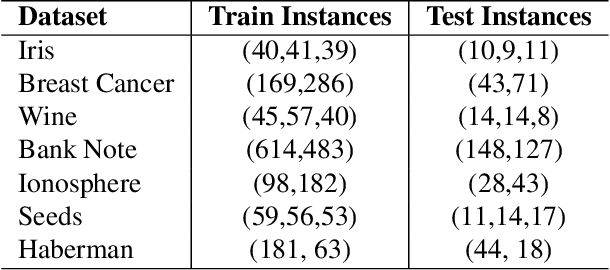
Modern machine learning approaches often prioritize performance at the cost of increased complexity, computational demands, and reduced interpretability. This paper introduces a novel framework that challenges this trend by reinterpreting learning from an information-theoretic perspective, viewing it as a search for encoding schemes that capture intrinsic data structures through compact representations. Rather than following the conventional approach of fitting data to complex models, we propose a fundamentally different method that maps data to intervals of initial conditions in a dynamical system. Our GLS (Generalized L\"uroth Series) coding compression classifier employs skew tent maps - a class of chaotic maps - both for encoding data into initial conditions and for subsequent recovery. The effectiveness of this simple framework is noteworthy, with performance closely approaching that of well-established machine learning methods. On the breast cancer dataset, our approach achieves 92.98\% accuracy, comparable to Naive Bayes at 94.74\%. While these results do not exceed state-of-the-art performance, the significance of our contribution lies not in outperforming existing methods but in demonstrating that a fundamentally simpler, more interpretable approach can achieve competitive results.
Uncertainty-Aware Regularization for Image-to-Image Translation
Nov 24, 2024



The importance of quantifying uncertainty in deep networks has become paramount for reliable real-world applications. In this paper, we propose a method to improve uncertainty estimation in medical Image-to-Image (I2I) translation. Our model integrates aleatoric uncertainty and employs Uncertainty-Aware Regularization (UAR) inspired by simple priors to refine uncertainty estimates and enhance reconstruction quality. We show that by leveraging simple priors on parameters, our approach captures more robust uncertainty maps, effectively refining them to indicate precisely where the network encounters difficulties, while being less affected by noise. Our experiments demonstrate that UAR not only improves translation performance, but also provides better uncertainty estimations, particularly in the presence of noise and artifacts. We validate our approach using two medical imaging datasets, showcasing its effectiveness in maintaining high confidence in familiar regions while accurately identifying areas of uncertainty in novel/ambiguous scenarios.
Terrain-Informed Self-Supervised Learning: Enhancing Building Footprint Extraction from LiDAR Data with Limited Annotations
Nov 02, 2023



Estimating building footprint maps from geospatial data is of paramount importance in urban planning, development, disaster management, and various other applications. Deep learning methodologies have gained prominence in building segmentation maps, offering the promise of precise footprint extraction without extensive post-processing. However, these methods face challenges in generalization and label efficiency, particularly in remote sensing, where obtaining accurate labels can be both expensive and time-consuming. To address these challenges, we propose terrain-aware self-supervised learning, tailored to remote sensing, using digital elevation models from LiDAR data. We propose to learn a model to differentiate between bare Earth and superimposed structures enabling the network to implicitly learn domain-relevant features without the need for extensive pixel-level annotations. We test the effectiveness of our approach by evaluating building segmentation performance on test datasets with varying label fractions. Remarkably, with only 1% of the labels (equivalent to 25 labeled examples), our method improves over ImageNet pre-training, showing the advantage of leveraging unlabeled data for feature extraction in the domain of remote sensing. The performance improvement is more pronounced in few-shot scenarios and gradually closes the gap with ImageNet pre-training as the label fraction increases. We test on a dataset characterized by substantial distribution shifts and labeling errors to demonstrate the generalizability of our approach. When compared to other baselines, including ImageNet pretraining and more complex architectures, our approach consistently performs better, demonstrating the efficiency and effectiveness of self-supervised terrain-aware feature learning.
Evaluating clinical diversity and plausibility of synthetic capsule endoscopic images
Jan 16, 2023Wireless Capsule Endoscopy (WCE) is being increasingly used as an alternative imaging modality for complete and non-invasive screening of the gastrointestinal tract. Although this is advantageous in reducing unnecessary hospital admissions, it also demands that a WCE diagnostic protocol be in place so larger populations can be effectively screened. This calls for training and education protocols attuned specifically to this modality. Like training in other modalities such as traditional endoscopy, CT, MRI, etc., a WCE training protocol would require an atlas comprising of a large corpora of images that show vivid descriptions of pathologies and abnormalities, ideally observed over a period of time. Since such comprehensive atlases are presently lacking in WCE, in this work, we propose a deep learning method for utilizing already available studies across different institutions for the creation of a realistic WCE atlas using StyleGAN. We identify clinically relevant attributes in WCE such that synthetic images can be generated with selected attributes on cue. Beyond this, we also simulate several disease progression scenarios. The generated images are evaluated for realism and plausibility through three subjective online experiments with the participation of eight gastroenterology experts from three geographical locations and a variety of years of experience. The results from the experiments indicate that the images are highly realistic and the disease scenarios plausible. The images comprising the atlas are available publicly for use in training applications as well as supplementing real datasets for deep learning.
This changes to that : Combining causal and non-causal explanations to generate disease progression in capsule endoscopy
Dec 05, 2022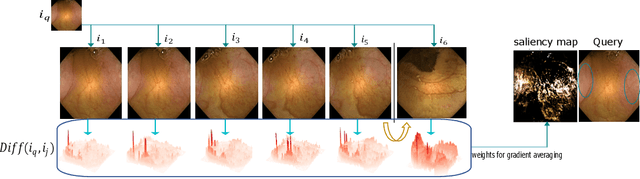
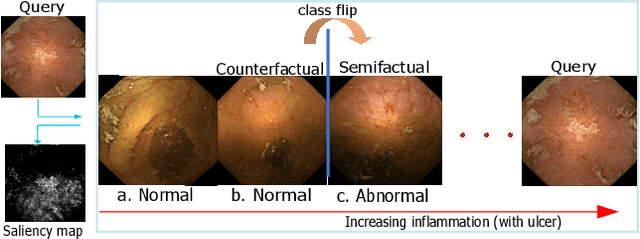
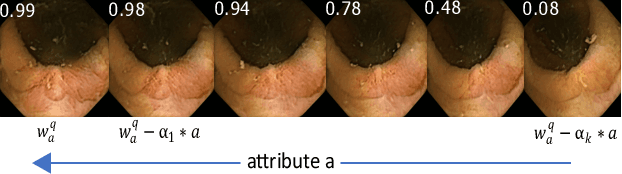
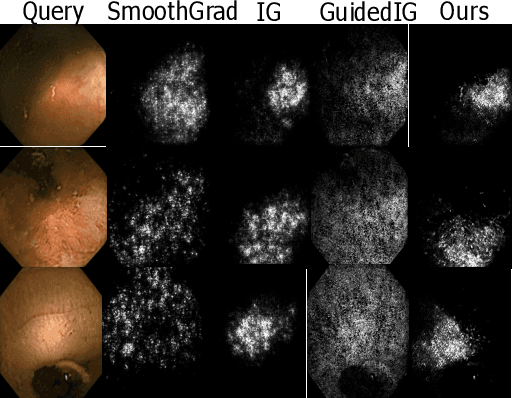
Due to the unequivocal need for understanding the decision processes of deep learning networks, both modal-dependent and model-agnostic techniques have become very popular. Although both of these ideas provide transparency for automated decision making, most methodologies focus on either using the modal-gradients (model-dependent) or ignoring the model internal states and reasoning with a model's behavior/outcome (model-agnostic) to instances. In this work, we propose a unified explanation approach that given an instance combines both model-dependent and agnostic explanations to produce an explanation set. The generated explanations are not only consistent in the neighborhood of a sample but can highlight causal relationships between image content and the outcome. We use Wireless Capsule Endoscopy (WCE) domain to illustrate the effectiveness of our explanations. The saliency maps generated by our approach are comparable or better on the softmax information score.
From Labels to Priors in Capsule Endoscopy: A Prior Guided Approach for Improving Generalization with Few Labels
Jun 10, 2022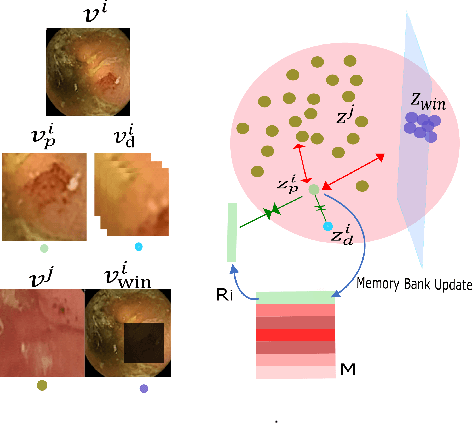

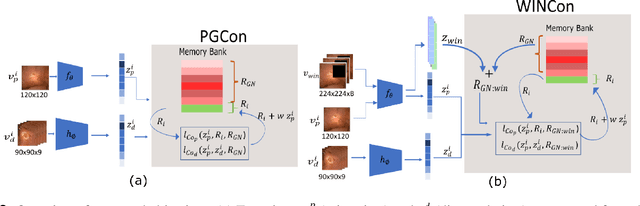

The lack of generalizability of deep learning approaches for the automated diagnosis of pathologies in Wireless Capsule Endoscopy (WCE) has prevented any significant advantages from trickling down to real clinical practices. As a result, disease management using WCE continues to depend on exhaustive manual investigations by medical experts. This explains its limited use despite several advantages. Prior works have considered using higher quality and quantity of labels as a way of tackling the lack of generalization, however this is hardly scalable considering pathology diversity not to mention that labeling large datasets encumbers the medical staff additionally. We propose using freely available domain knowledge as priors to learn more robust and generalizable representations. We experimentally show that domain priors can benefit representations by acting in proxy of labels, thereby significantly reducing the labeling requirement while still enabling fully unsupervised yet pathology-aware learning. We use the contrastive objective along with prior-guided views during pretraining, where the view choices inspire sensitivity to pathological information. Extensive experiments on three datasets show that our method performs better than (or closes gap with) the state-of-the-art in the domain, establishing a new benchmark in pathology classification and cross-dataset generalization, as well as scaling to unseen pathology categories.
Learning More for Free - A Multi Task Learning Approach for Improved Pathology Classification in Capsule Endoscopy
Jun 30, 2021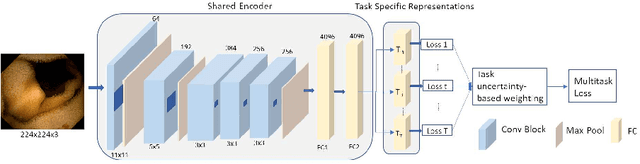
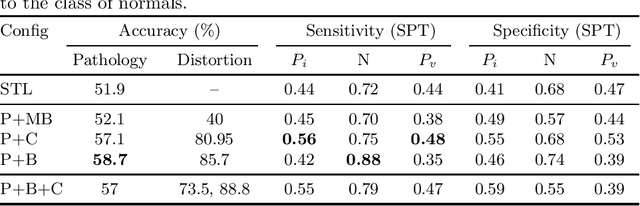
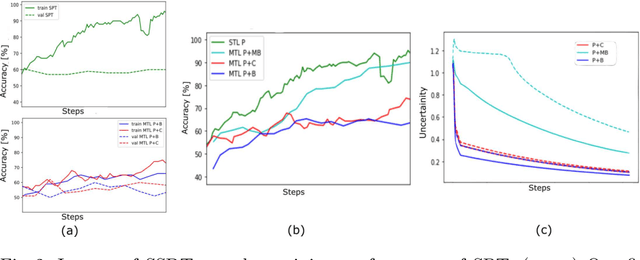

The progress in Computer Aided Diagnosis (CADx) of Wireless Capsule Endoscopy (WCE) is thwarted by the lack of data. The inadequacy in richly representative healthy and abnormal conditions results in isolated analyses of pathologies, that can not handle realistic multi-pathology scenarios. In this work, we explore how to learn more for free, from limited data through solving a WCE multicentric, multi-pathology classification problem. Learning more implies to learning more than full supervision would allow with the same data. This is done by combining self supervision with full supervision, under multi task learning. Additionally, we draw inspiration from the Human Visual System (HVS) in designing self supervision tasks and investigate if seemingly ineffectual signals within the data itself can be exploited to gain performance, if so, which signals would be better than others. Further, we present our analysis of the high level features as a stepping stone towards more robust multi-pathology CADx in WCE.