 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Tree Based Approaches Surpass Deep Learning in Anomaly Detection? A Benchmarking Study
Feb 26, 2024Detection of anomalous situations for complex mission-critical systems holds paramount importance when their service continuity needs to be ensured. A major challenge in detecting anomalies from the operational data arises due to the imbalanced class distribution problem since the anomalies are supposed to be rare events. This paper evaluates a diverse array of machine learning-based anomaly detection algorithms through a comprehensive benchmark study. The paper contributes significantly by conducting an unbiased comparison of various anomaly detection algorithms, spanning classical machine learning including various tree-based approaches to deep learning and outlier detection methods. The inclusion of 104 publicly available and a few proprietary industrial systems datasets enhances the diversity of the study, allowing for a more realistic evaluation of algorithm performance and emphasizing the importance of adaptability to real-world scenarios. The paper dispels the deep learning myth, demonstrating that though powerful, deep learning is not a universal solution in this case. We observed that recently proposed tree-based evolutionary algorithms outperform in many scenarios. We noticed that tree-based approaches catch a singleton anomaly in a dataset where deep learning methods fail. On the other hand, classical SVM performs the best on datasets with more than 10% anomalies, implying that such scenarios can be best modeled as a classification problem rather than anomaly detection. To our knowledge, such a study on a large number of state-of-the-art algorithms using diverse data sets, with the objective of guiding researchers and practitioners in making informed algorithmic choices, has not been attempted earlier.
Quantile LSTM: A Robust LSTM for Anomaly Detection In Time Series Data
Feb 17, 2023Anomalies refer to the departure of systems and devices from their normal behaviour in standard operating conditions. An anomaly in an industrial device can indicate an upcoming failure, often in the temporal direction. In this paper, we make two contributions: 1) we estimate conditional quantiles and consider three different ways to define anomalies based on the estimated quantiles. 2) we use a new learnable activation function in the popular Long Short Term Memory networks (LSTM) architecture to model temporal long-range dependency. In particular, we propose Parametric Elliot Function (PEF) as an activation function (AF) inside LSTM, which saturates lately compared to sigmoid and tanh. The proposed algorithms are compared with other well-known anomaly detection algorithms, such as Isolation Forest (iForest), Elliptic Envelope, Autoencoder, and modern Deep Learning models such as Deep Autoencoding Gaussian Mixture Model (DAGMM), Generative Adversarial Networks (GAN). The algorithms are evaluated in terms of various performance metrics, such as Precision and Recall. The algorithms have been tested on multiple industrial time-series datasets such as Yahoo, AWS, GE, and machine sensors. We have found that the LSTM-based quantile algorithms are very effective and outperformed the existing algorithms in identifying anomalies.
Postulating Exoplanetary Habitability via a Novel Anomaly Detection Method
Sep 06, 2021

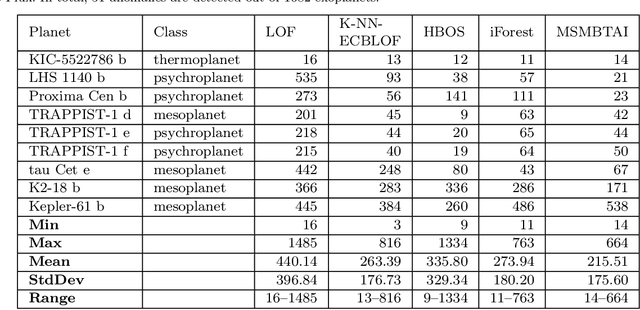
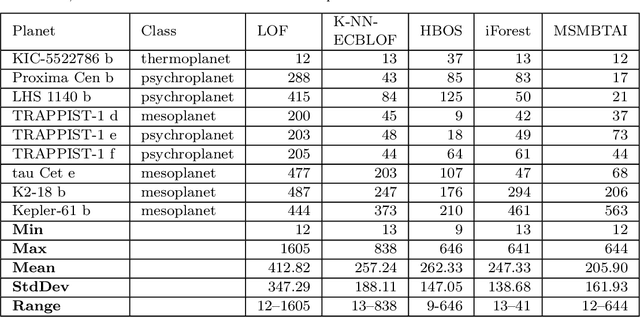
A profound shift in the study of cosmology came with the discovery of thousands of exoplanets and the possibility of the existence of billions of them in our Galaxy. The biggest goal in these searches is whether there are other life-harbouring planets. However, the question which of these detected planets are habitable, potentially-habitable, or maybe even inhabited, is still not answered. Some potentially habitable exoplanets have been hypothesized, but since Earth is the only known habitable planet, measures of habitability are necessarily determined with Earth as the reference. Several recent works introduced new habitability metrics based on optimization methods. Classification of potentially habitable exoplanets using supervised learning is another emerging area of study. However, both modeling and supervised learning approaches suffer from drawbacks. We propose an anomaly detection method, the Multi-Stage Memetic Algorithm (MSMA), to detect anomalies and extend it to an unsupervised clustering algorithm MSMVMCA to use it to detect potentially habitable exoplanets as anomalies. The algorithm is based on the postulate that Earth is an anomaly, with the possibility of existence of few other anomalies among thousands of data points. We describe an MSMA-based clustering approach with a novel distance function to detect habitable candidates as anomalies (including Earth). The results are cross-matched with the habitable exoplanet catalog (PHL-HEC) of the Planetary Habitability Laboratory (PHL) with both optimistic and conservative lists of potentially habitable exoplanets.