 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Level Relation to Attentive Aggregation with Neighborhood-Homogeneity Constraint for Point Cloud Analysis
May 04, 2026In 3D point cloud understanding, the core challenge lies in accurately capturing discriminative features within complex neighborhoods, which directly affects the execution precision of downstream tasks such as embodied AI and autonomous driving. Existing methods explore feature correlation discrimination but are limited to point-level spatial distribution or channel responses, enabling only coarse-grained level evaluation. For modern multi-scale point cloud networks, such coarse-grained metrics inevitably incur significant information loss in deeper layers. To address this issue, we propose a novel network equipped with a channel-level metric-based enhancement mechanism, termed the PointCRA network. Our core idea is to introduce temporal trend variation as a new evaluation dimension to avoid the information loss caused by weight dimension collapse in existing spatial and channel attention mechanisms. On this basis, we construct a multi-level calibration framework guided by neighborhood homogeneity for weight calibration, and design a dedicated loss function to enhance channel discriminability. The module effectively leverages the intrinsic feature priors of deep networks to adaptively correct the feature aggregation process, offering strong interpretability with low parameter overhead. Furthermore, our proposed method exhibits strong transferability, interpretability, and parameter efficiency. We validate the proposed method effectiveness on diverse datasets and benchmark models, and further demonstrate its rationality through extensive analytical experiments. Our PointCRA achieves 77.5% mIoU on the S3DIS dataset, 90.4% OA on the ScanObjectNN dataset, and 87.4% instance mIoU on the ShapeNetPart dataset. The code and pretrained weights are publicly available on GitHub:
Enhancing point cloud analysis via neighbor aggregation correction based on cross-stage structure correlation
Jun 18, 2025Point cloud analysis is the cornerstone of many downstream tasks, among which aggregating local structures is the basis for understanding point cloud data. While numerous works aggregate neighbor using three-dimensional relative coordinates, there are irrelevant point interference and feature hierarchy gap problems due to the limitation of local coordinates. Although some works address this limitation by refining spatial description though explicit modeling of cross-stage structure, these enhancement methods based on direct geometric structure encoding have problems of high computational overhead and noise sensitivity. To overcome these problems, we propose the Point Distribution Set Abstraction module (PDSA) that utilizes the correlation in the high-dimensional space to correct the feature distribution during aggregation, which improves the computational efficiency and robustness. PDSA distinguishes the point correlation based on a lightweight cross-stage structural descriptor, and enhances structural homogeneity by reducing the variance of the neighbor feature matrix and increasing classes separability though long-distance modeling. Additionally, we introducing a key point mechanism to optimize the computational overhead. The experimental result on semantic segmentation and classification tasks based on different baselines verify the generalization of the method we proposed, and achieve significant performance improvement with less parameter cost. The corresponding ablation and visualization results demonstrate the effectiveness and rationality of our method. The code and training weight is available at: https://github.com/AGENT9717/PointDistribution
ChemHAS: Hierarchical Agent Stacking for Enhancing Chemistry Tools
May 27, 2025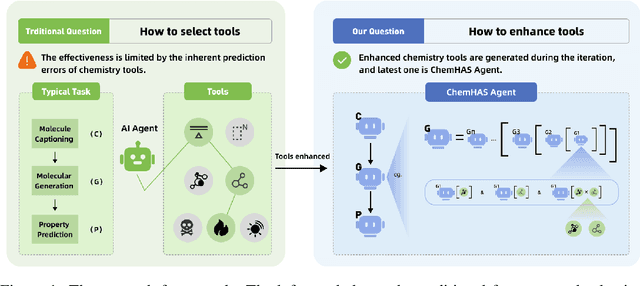
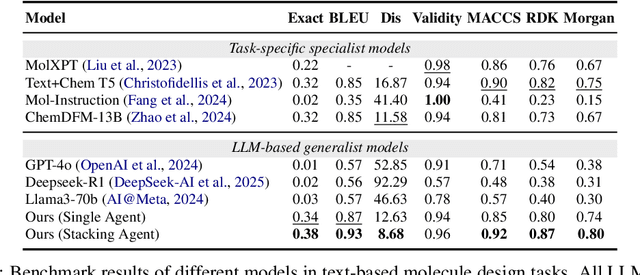
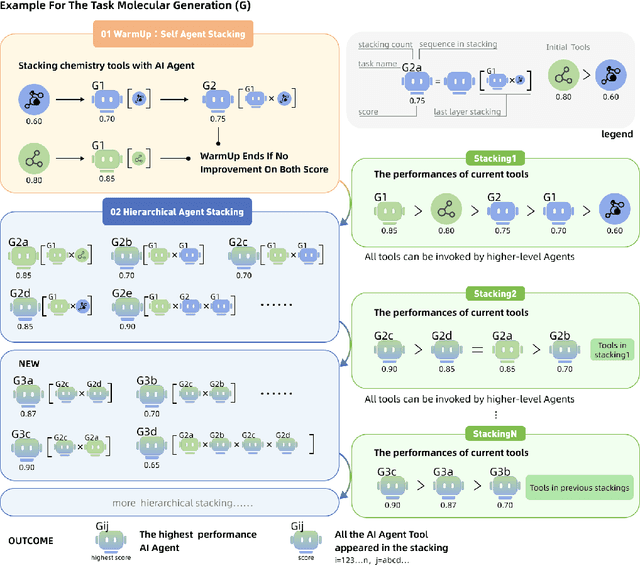
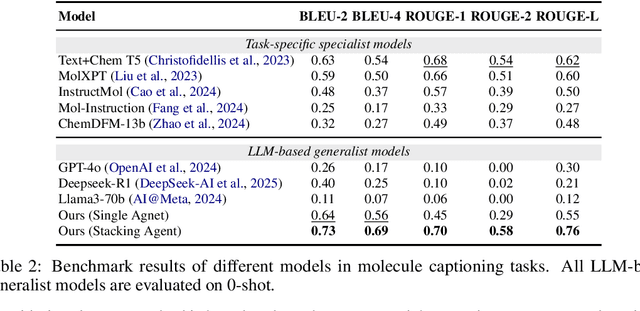
Large Language Model (LLM)-based agents have demonstrated the ability to improve performance in chemistry-related tasks by selecting appropriate tools. However, their effectiveness remains limited by the inherent prediction errors of chemistry tools. In this paper, we take a step further by exploring how LLMbased agents can, in turn, be leveraged to reduce prediction errors of the tools. To this end, we propose ChemHAS (Chemical Hierarchical Agent Stacking), a simple yet effective method that enhances chemistry tools through optimizing agent-stacking structures from limited data. ChemHAS achieves state-of-the-art performance across four fundamental chemistry tasks, demonstrating that our method can effectively compensate for prediction errors of the tools. Furthermore, we identify and characterize four distinct agent-stacking behaviors, potentially improving interpretability and revealing new possibilities for AI agent applications in scientific research. Our code and dataset are publicly available at https: //anonymous.4open.science/r/ChemHAS-01E4/README.md.
QUILL: Quotation Generation Enhancement of Large Language Models
Nov 06, 2024



While Large language models (LLMs) have become excellent writing assistants, they still struggle with quotation generation. This is because they either hallucinate when providing factual quotations or fail to provide quotes that exceed human expectations. To bridge the gap, we systematically study how to evaluate and improve LLMs' performance in quotation generation tasks. We first establish a holistic and automatic evaluation system for quotation generation task, which consists of five criteria each with corresponding automatic metric. To improve the LLMs' quotation generation abilities, we construct a bilingual knowledge base that is broad in scope and rich in dimensions, containing up to 32,022 quotes. Moreover, guided by our critiria, we further design a quotation-specific metric to rerank the retrieved quotations from the knowledge base. Extensive experiments show that our metrics strongly correlate with human preferences. Existing LLMs struggle to generate desired quotes, but our quotation knowledge base and reranking metric help narrow this gap. Our dataset and code are publicly available at https://github.com/GraceXiaoo/QUILL.
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023


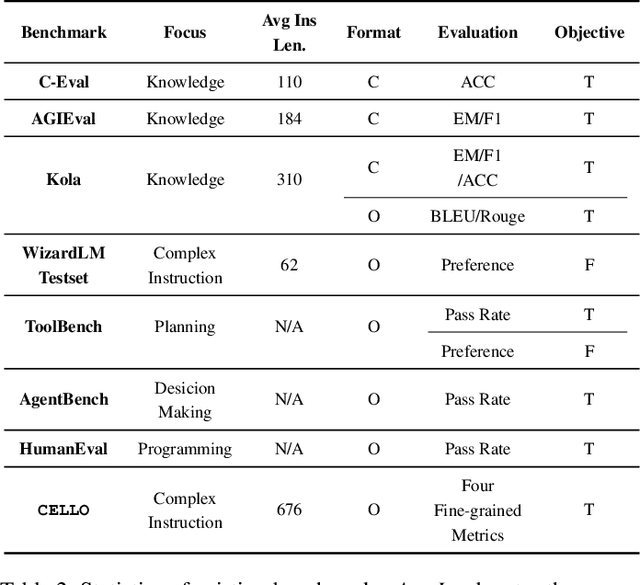
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.
A bioinspired three-stage model for camouflaged object detection
May 22, 2023Camouflaged objects are typically assimilated into their backgrounds and exhibit fuzzy boundaries. The complex environmental conditions and the high intrinsic similarity between camouflaged targets and their surroundings pose significant challenges in accurately locating and segmenting these objects in their entirety. While existing methods have demonstrated remarkable performance in various real-world scenarios, they still face limitations when confronted with difficult cases, such as small targets, thin structures, and indistinct boundaries. Drawing inspiration from human visual perception when observing images containing camouflaged objects, we propose a three-stage model that enables coarse-to-fine segmentation in a single iteration. Specifically, our model employs three decoders to sequentially process subsampled features, cropped features, and high-resolution original features. This proposed approach not only reduces computational overhead but also mitigates interference caused by background noise. Furthermore, considering the significance of multi-scale information, we have designed a multi-scale feature enhancement module that enlarges the receptive field while preserving detailed structural cues. Additionally, a boundary enhancement module has been developed to enhance performance by leveraging boundary information. Subsequently, a mask-guided fusion module is proposed to generate fine-grained results by integrating coarse prediction maps with high-resolution feature maps. Our network surpasses state-of-the-art CNN-based counterparts without unnecessary complexities. Upon acceptance of the paper, the source code will be made publicly available at https://github.com/clelouch/BTSNet.
Partitioning Cloud-based Microservices (via Deep Learning)
Sep 29, 2021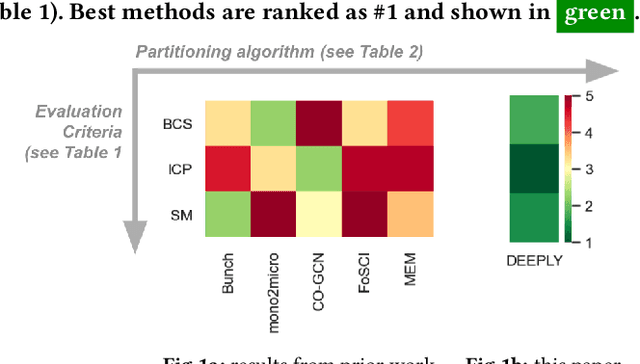

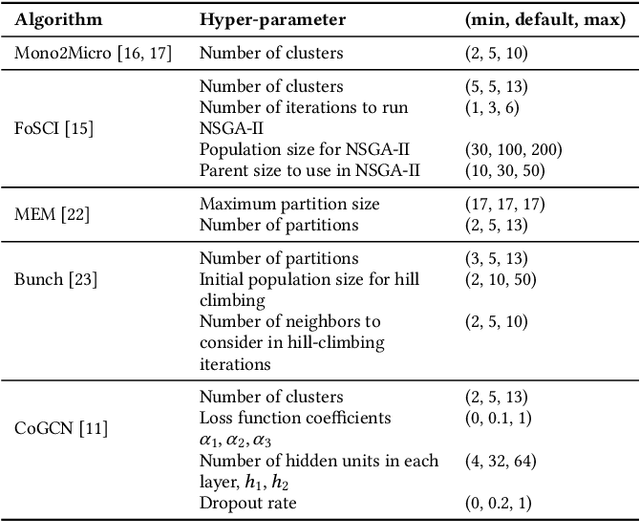
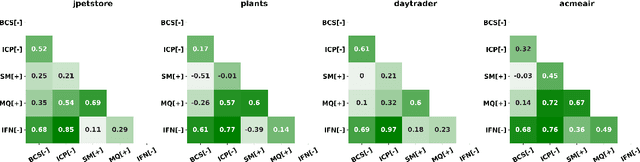
Cloud-based software has many advantages. When services are divided into many independent components, they are easier to update. Also, during peak demand, it is easier to scale cloud services (just hire more CPUs). Hence, many organizations are partitioning their monolithic enterprise applications into cloud-based microservices. Recently there has been much work using machine learning to simplify this partitioning task. Despite much research, no single partitioning method can be recommended as generally useful. More specifically, those prior solutions are "brittle''; i.e. if they work well for one kind of goal in one dataset, then they can be sub-optimal if applied to many datasets and multiple goals. In order to find a generally useful partitioning method, we propose DEEPLY. This new algorithm extends the CO-GCN deep learning partition generator with (a) a novel loss function and (b) some hyper-parameter optimization. As shown by our experiments, DEEPLY generally outperforms prior work (including CO-GCN, and others) across multiple datasets and goals. To the best of our knowledge, this is the first report in SE of such stable hyper-parameter optimization. To aid reuse of this work, DEEPLY is available on-line at https://bit.ly/2WhfFlB.
A Smartphone-based System for Real-time Early Childhood Caries Diagnosis
Aug 17, 2020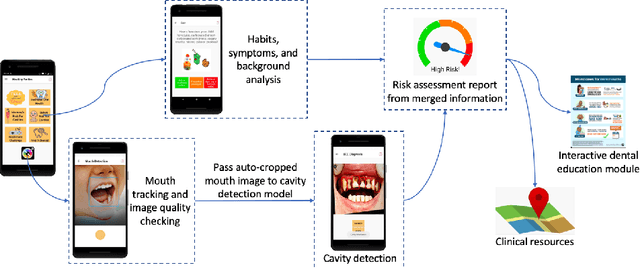


Early childhood caries (ECC) is the most common, yet preventable chronic disease in children under the age of 6. Treatments on severe ECC are extremely expensive and unaffordable for socioeconomically disadvantaged families. The identification of ECC in an early stage usually requires expertise in the field, and hence is often ignored by parents. Therefore, early prevention strategies and easy-to-adopt diagnosis techniques are desired. In this study, we propose a multistage deep learning-based system for cavity detection. We create a dataset containing RGB oral images labeled manually by dental practitioners. We then investigate the effectiveness of different deep learning models on the dataset. Furthermore, we integrate the deep learning system into an easy-to-use mobile application that can diagnose ECC from an early stage and provide real-time results to untrained users.