 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Adapt: Few-shot Bimanual Adaptation for Novel Categories of 3D Objects via Semantic Correspondence
Feb 09, 2026Bimanual manipulation is imperative yet challenging for robots to execute complex tasks, requiring coordinated collaboration between two arms. However, existing methods for bimanual manipulation often rely on costly data collection and training, struggling to generalize to unseen objects in novel categories efficiently. In this paper, we present Bi-Adapt, a novel framework designed for efficient generalization for bimanual manipulation via semantic correspondence. Bi-Adapt achieves cross-category affordance mapping by leveraging the strong capability of vision foundation models. Fine-tuning with restricted data on novel categories, Bi-Adapt exhibits notable generalization to out-of-category objects in a zero-shot manner. Extensive experiments conducted in both simulation and real-world environments validate the effectiveness of our approach and demonstrate its high efficiency, achieving a high success rate on different benchmark tasks across novel categories with limited data. Project website: https://biadapt-project.github.io/
$\textbf{EMOS}$: $\textbf{E}$mbodiment-aware Heterogeneous $\textbf{M}$ulti-robot $\textbf{O}$perating $\textbf{S}$ystem with LLM Agents
Oct 30, 2024

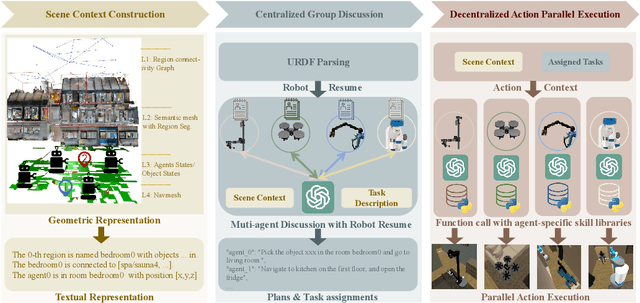

Heterogeneous multi-robot systems (HMRS) have emerged as a powerful approach for tackling complex tasks that single robots cannot manage alone. Current large-language-model-based multi-agent systems (LLM-based MAS) have shown success in areas like software development and operating systems, but applying these systems to robot control presents unique challenges. In particular, the capabilities of each agent in a multi-robot system are inherently tied to the physical composition of the robots, rather than predefined roles. To address this issue, we introduce a novel multi-agent framework designed to enable effective collaboration among heterogeneous robots with varying embodiments and capabilities, along with a new benchmark named Habitat-MAS. One of our key designs is $\textit{Robot Resume}$: Instead of adopting human-designed role play, we propose a self-prompted approach, where agents comprehend robot URDF files and call robot kinematics tools to generate descriptions of their physics capabilities to guide their behavior in task planning and action execution. The Habitat-MAS benchmark is designed to assess how a multi-agent framework handles tasks that require embodiment-aware reasoning, which includes 1) manipulation, 2) perception, 3) navigation, and 4) comprehensive multi-floor object rearrangement. The experimental results indicate that the robot's resume and the hierarchical design of our multi-agent system are essential for the effective operation of the heterogeneous multi-robot system within this intricate problem context.
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023


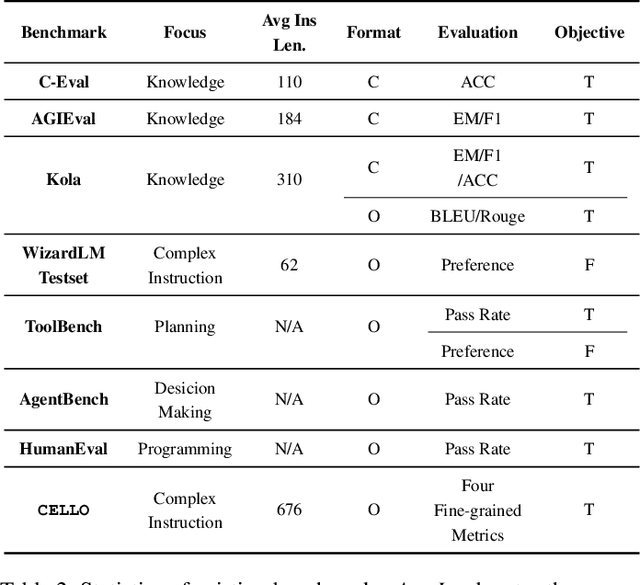
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.