 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaying the Foundation First? Investigating the Generalization from Atomic Skills to Complex Reasoning Tasks
Mar 14, 2024



Current language models have demonstrated their capability to develop basic reasoning, but struggle in more complicated reasoning tasks that require a combination of atomic skills, such as math word problem requiring skills like arithmetic and unit conversion. Previous methods either do not improve the inherent atomic skills of models or not attempt to generalize the atomic skills to complex reasoning tasks. In this paper, we first propose a probing framework to investigate whether the atomic skill can spontaneously generalize to complex reasoning tasks. Then, we introduce a hierarchical curriculum learning training strategy to achieve better skill generalization. In our experiments, we find that atomic skills can not spontaneously generalize to compositional tasks. By leveraging hierarchical curriculum learning, we successfully induce generalization, significantly improve the performance of open-source LMs on complex reasoning tasks. Promisingly, the skill generalization exhibit effective in cross-dataset and cross-domain scenarios. Complex reasoning can also help enhance atomic skills. Our findings offer valuable guidance for designing better training strategies for complex reasoning tasks.
Enhancing Quantitative Reasoning Skills of Large Language Models through Dimension Perception
Dec 29, 2023Quantities are distinct and critical components of texts that characterize the magnitude properties of entities, providing a precise perspective for the understanding of natural language, especially for reasoning tasks. In recent years, there has been a flurry of research on reasoning tasks based on large language models (LLMs), most of which solely focus on numerical values, neglecting the dimensional concept of quantities with units despite its importance. We argue that the concept of dimension is essential for precisely understanding quantities and of great significance for LLMs to perform quantitative reasoning. However, the lack of dimension knowledge and quantity-related benchmarks has resulted in low performance of LLMs. Hence, we present a framework to enhance the quantitative reasoning ability of language models based on dimension perception. We first construct a dimensional unit knowledge base (DimUnitKB) to address the knowledge gap in this area. We propose a benchmark DimEval consisting of seven tasks of three categories to probe and enhance the dimension perception skills of LLMs. To evaluate the effectiveness of our methods, we propose a quantitative reasoning task and conduct experiments. The experimental results show that our dimension perception method dramatically improves accuracy (43.55%->50.67%) on quantitative reasoning tasks compared to GPT-4.
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023


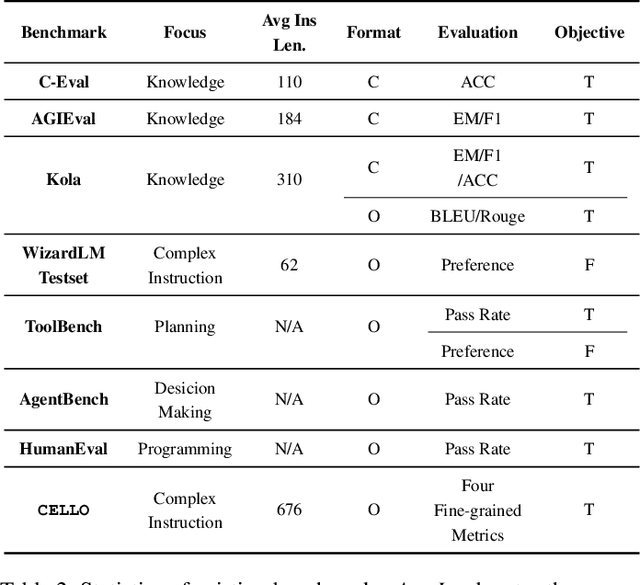
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.
HAUSER: Towards Holistic and Automatic Evaluation of Simile Generation
Jun 13, 2023



Similes play an imperative role in creative writing such as story and dialogue generation. Proper evaluation metrics are like a beacon guiding the research of simile generation (SG). However, it remains under-explored as to what criteria should be considered, how to quantify each criterion into metrics, and whether the metrics are effective for comprehensive, efficient, and reliable SG evaluation. To address the issues, we establish HAUSER, a holistic and automatic evaluation system for the SG task, which consists of five criteria from three perspectives and automatic metrics for each criterion. Through extensive experiments, we verify that our metrics are significantly more correlated with human ratings from each perspective compared with prior automatic metrics.