 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaying the Foundation First? Investigating the Generalization from Atomic Skills to Complex Reasoning Tasks
Mar 14, 2024



Current language models have demonstrated their capability to develop basic reasoning, but struggle in more complicated reasoning tasks that require a combination of atomic skills, such as math word problem requiring skills like arithmetic and unit conversion. Previous methods either do not improve the inherent atomic skills of models or not attempt to generalize the atomic skills to complex reasoning tasks. In this paper, we first propose a probing framework to investigate whether the atomic skill can spontaneously generalize to complex reasoning tasks. Then, we introduce a hierarchical curriculum learning training strategy to achieve better skill generalization. In our experiments, we find that atomic skills can not spontaneously generalize to compositional tasks. By leveraging hierarchical curriculum learning, we successfully induce generalization, significantly improve the performance of open-source LMs on complex reasoning tasks. Promisingly, the skill generalization exhibit effective in cross-dataset and cross-domain scenarios. Complex reasoning can also help enhance atomic skills. Our findings offer valuable guidance for designing better training strategies for complex reasoning tasks.
Source Prompt: Coordinated Pre-training of Language Models on Diverse Corpora from Multiple Sources
Nov 16, 2023
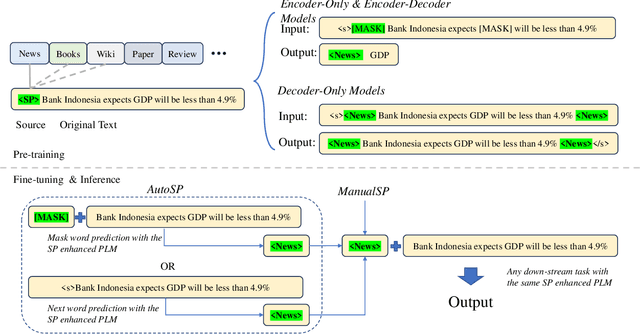
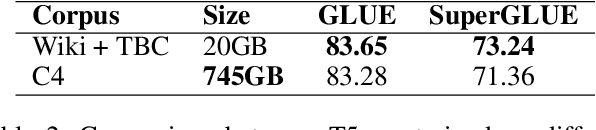

Pre-trained language models (PLMs) have established the new paradigm in the field of NLP. For more powerful PLMs, one of the most popular and successful way is to continuously scale up sizes of the models and the pre-training corpora. These large corpora are generally obtained by converging smaller ones from multiple sources, they are thus growing increasingly diverse. However, the side-effects of these colossal converged corpora remain understudied. In this paper, we identify the disadvantage of heterogeneous corpora from multiple sources for pre-training PLMs. Towards coordinated pre-training on diverse corpora, we further propose source prompts (SP), which explicitly prompt the model of the data source at the pre-training and fine-tuning stages. Results of extensive experiments demonstrate that PLMs pre-trained with SP on diverse corpora gain significant improvement in various downstream tasks.
BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark
Feb 26, 2023To advance Chinese financial natural language processing (NLP), we introduce BBT-FinT5, a new Chinese financial pre-training language model based on the T5 model. To support this effort, we have built BBT-FinCorpus, a large-scale financial corpus with approximately 300GB of raw text from four different sources. In general domain NLP, comprehensive benchmarks like GLUE and SuperGLUE have driven significant advancements in language model pre-training by enabling head-to-head comparisons among models. Drawing inspiration from these benchmarks, we propose BBT-CFLEB, a Chinese Financial Language understanding and generation Evaluation Benchmark, which includes six datasets covering both understanding and generation tasks. Our aim is to facilitate research in the development of NLP within the Chinese financial domain. Our model, corpus and benchmark are released at https://github.com/ssymmetry/BBT-FinCUGE-Applications. Our work belongs to the Big Bang Transformer (BBT), a large-scale pre-trained language model project.