 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Particle Collision Data Analysis
Nov 28, 2024For decades, researchers have developed task-specific models to address scientific challenges across diverse disciplines. Recently, large language models (LLMs) have shown enormous capabilities in handling general tasks; however, these models encounter difficulties in addressing real-world scientific problems, particularly in domains involving large-scale numerical data analysis, such as experimental high energy physics. This limitation is primarily due to BPE tokenization's inefficacy with numerical data. In this paper, we propose a task-agnostic architecture, BBT-Neutron, which employs a binary tokenization method to facilitate pretraining on a mixture of textual and large-scale numerical experimental data. The project code is available at https://github.com/supersymmetry-technologies/bbt-neutron. We demonstrate the application of BBT-Neutron to Jet Origin Identification (JoI), a critical categorization challenge in high-energy physics that distinguishes jets originating from various quarks or gluons. Our results indicate that BBT-Neutron achieves comparable performance to state-of-the-art task-specific JoI models. Furthermore, we examine the scaling behavior of BBT-Neutron's performance with increasing data volume, suggesting the potential for BBT-Neutron to serve as a foundational model for particle physics data analysis, with possible extensions to a broad spectrum of scientific computing applications for Big Science experiments, industrial manufacturing and spacial computing.
Source Prompt: Coordinated Pre-training of Language Models on Diverse Corpora from Multiple Sources
Nov 16, 2023
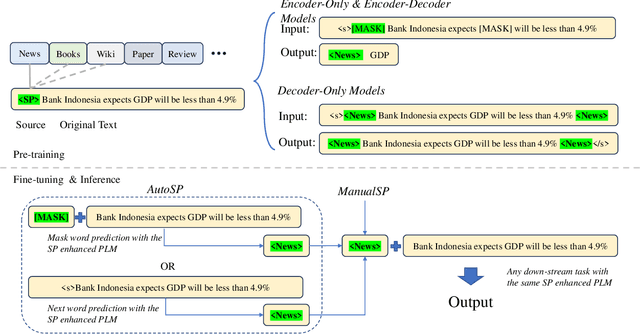

Pre-trained language models (PLMs) have established the new paradigm in the field of NLP. For more powerful PLMs, one of the most popular and successful way is to continuously scale up sizes of the models and the pre-training corpora. These large corpora are generally obtained by converging smaller ones from multiple sources, they are thus growing increasingly diverse. However, the side-effects of these colossal converged corpora remain understudied. In this paper, we identify the disadvantage of heterogeneous corpora from multiple sources for pre-training PLMs. Towards coordinated pre-training on diverse corpora, we further propose source prompts (SP), which explicitly prompt the model of the data source at the pre-training and fine-tuning stages. Results of extensive experiments demonstrate that PLMs pre-trained with SP on diverse corpora gain significant improvement in various downstream tasks.
BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark
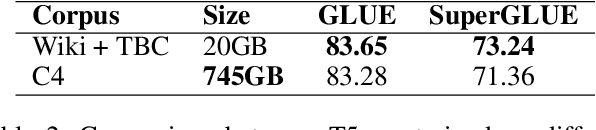
Feb 26, 2023To advance Chinese financial natural language processing (NLP), we introduce BBT-FinT5, a new Chinese financial pre-training language model based on the T5 model. To support this effort, we have built BBT-FinCorpus, a large-scale financial corpus with approximately 300GB of raw text from four different sources. In general domain NLP, comprehensive benchmarks like GLUE and SuperGLUE have driven significant advancements in language model pre-training by enabling head-to-head comparisons among models. Drawing inspiration from these benchmarks, we propose BBT-CFLEB, a Chinese Financial Language understanding and generation Evaluation Benchmark, which includes six datasets covering both understanding and generation tasks. Our aim is to facilitate research in the development of NLP within the Chinese financial domain. Our model, corpus and benchmark are released at https://github.com/ssymmetry/BBT-FinCUGE-Applications. Our work belongs to the Big Bang Transformer (BBT), a large-scale pre-trained language model project.