 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeTS: Learning to Think-and-Search via Process-and-Outcome Reward Hybridization
May 23, 2025Large language models (LLMs) have demonstrated impressive capabilities in reasoning with the emergence of reasoning models like OpenAI-o1 and DeepSeek-R1. Recent research focuses on integrating reasoning capabilities into the realm of retrieval-augmented generation (RAG) via outcome-supervised reinforcement learning (RL) approaches, while the correctness of intermediate think-and-search steps is usually neglected. To address this issue, we design a process-level reward module to mitigate the unawareness of intermediate reasoning steps in outcome-level supervision without additional annotation. Grounded on this, we propose Learning to Think-and-Search (LeTS), a novel framework that hybridizes stepwise process reward and outcome-based reward to current RL methods for RAG. Extensive experiments demonstrate the generalization and inference efficiency of LeTS across various RAG benchmarks. In addition, these results reveal the potential of process- and outcome-level reward hybridization in boosting LLMs' reasoning ability via RL under other scenarios. The code will be released soon.
QUILL: Quotation Generation Enhancement of Large Language Models
Nov 06, 2024



While Large language models (LLMs) have become excellent writing assistants, they still struggle with quotation generation. This is because they either hallucinate when providing factual quotations or fail to provide quotes that exceed human expectations. To bridge the gap, we systematically study how to evaluate and improve LLMs' performance in quotation generation tasks. We first establish a holistic and automatic evaluation system for quotation generation task, which consists of five criteria each with corresponding automatic metric. To improve the LLMs' quotation generation abilities, we construct a bilingual knowledge base that is broad in scope and rich in dimensions, containing up to 32,022 quotes. Moreover, guided by our critiria, we further design a quotation-specific metric to rerank the retrieved quotations from the knowledge base. Extensive experiments show that our metrics strongly correlate with human preferences. Existing LLMs struggle to generate desired quotes, but our quotation knowledge base and reranking metric help narrow this gap. Our dataset and code are publicly available at https://github.com/GraceXiaoo/QUILL.
SEGMENT+: Long Text Processing with Short-Context Language Models
Oct 09, 2024



There is a growing interest in expanding the input capacity of language models (LMs) across various domains. However, simply increasing the context window does not guarantee robust performance across diverse long-input processing tasks, such as understanding extensive documents and extracting detailed information from lengthy and noisy data. In response, we introduce SEGMENT+, a general framework that enables LMs to handle extended inputs within limited context windows efficiently. SEGMENT+ utilizes structured notes and a filtering module to manage information flow, resulting in a system that is both controllable and interpretable. Our extensive experiments across various model sizes, focusing on long-document question-answering and Needle-in-a-Haystack tasks, demonstrate the effectiveness of SEGMENT+ in improving performance.
Teaching Large Language Models to Express Knowledge Boundary from Their Own Signals
Jun 16, 2024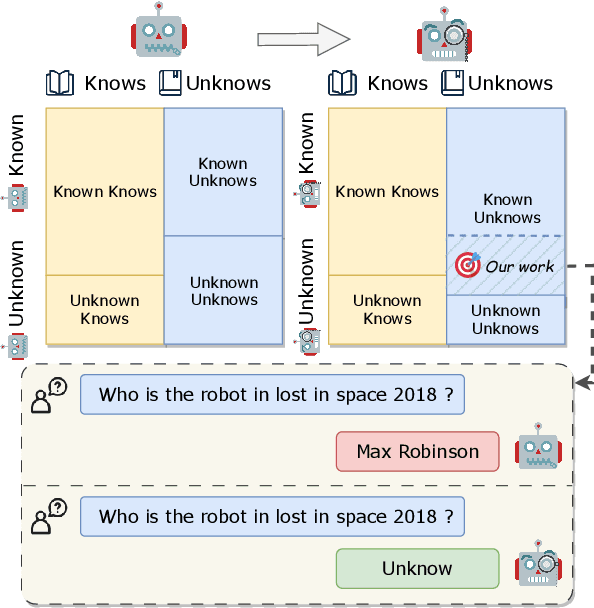
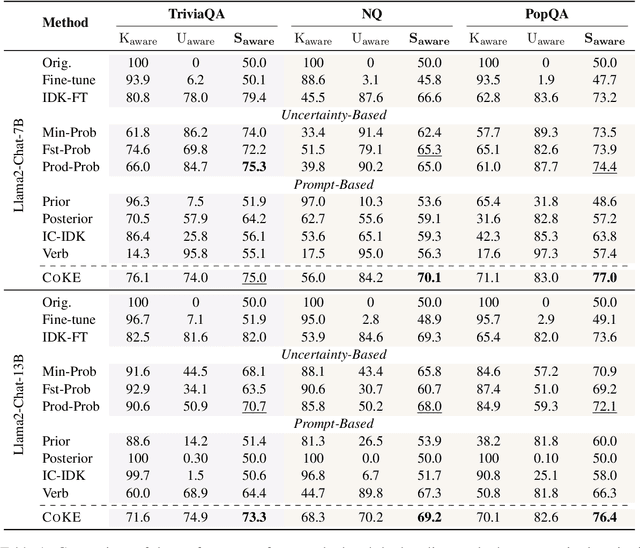
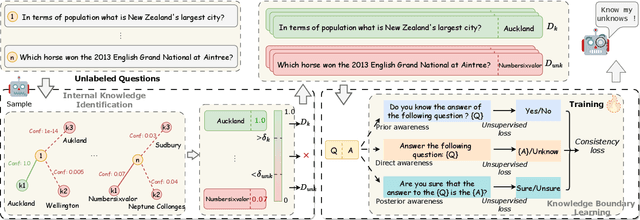
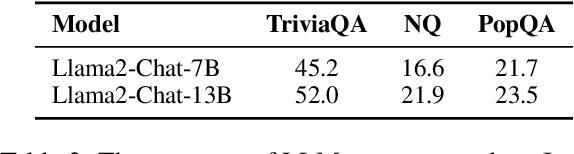
Large language models (LLMs) have achieved great success, but their occasional content fabrication, or hallucination, limits their practical application. Hallucination arises because LLMs struggle to admit ignorance due to inadequate training on knowledge boundaries. We call it a limitation of LLMs that they can not accurately express their knowledge boundary, answering questions they know while admitting ignorance to questions they do not know. In this paper, we aim to teach LLMs to recognize and express their knowledge boundary, so they can reduce hallucinations caused by fabricating when they do not know. We propose CoKE, which first probes LLMs' knowledge boundary via internal confidence given a set of questions, and then leverages the probing results to elicit the expression of the knowledge boundary. Extensive experiments show CoKE helps LLMs express knowledge boundaries, answering known questions while declining unknown ones, significantly improving in-domain and out-of-domain performance.